

Können Lernalgorithmen interagieren wie im Gehirn? - Intelligent ...
Können Lernalgorithmen interagieren wie im Gehirn? - Intelligent ...
Können Lernalgorithmen interagieren wie im Gehirn? - Intelligent ...

Erfolgreiche ePaper selbst erstellen
Machen Sie aus Ihren PDF Publikationen ein blätterbares Flipbook mit unserer einzigartigen Google optimierten e-Paper Software.
Average Reward per Episode<br />
Average Step per Episode<br />
1000<br />
500<br />
2500<br />
2000<br />
Q-Learning<br />
Clustering<br />
Model based<br />
Clustering + Model based<br />
Clustering + Model based + Encaps.<br />
Average Sum of Rewards<br />
0<br />
-500<br />
Average Steps<br />
1500<br />
1000<br />
-1000<br />
Q-Learning<br />
Clustering<br />
Model based<br />
Clustering + Model based<br />
Clustering + Model based + Encapsulating<br />
-1500<br />
10 0 10 1 10 2 10 3 10 4<br />
500<br />
0<br />
10 0 10 1 10 2 10 3 10 4<br />
Number of Episodes<br />
Number of Episodes<br />
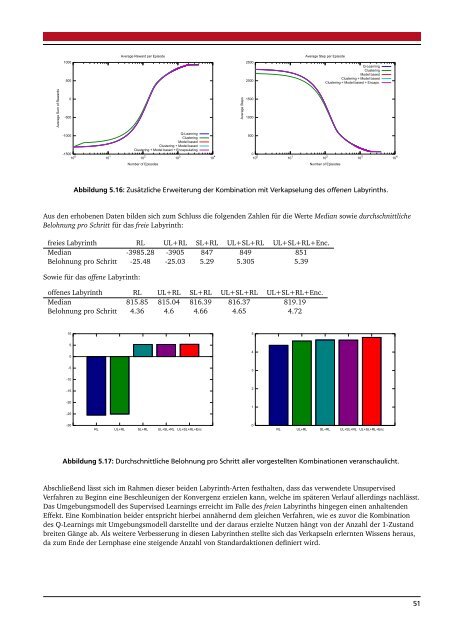
Abbildung 5.16: Zusätzliche Erweiterung der Kombination mit Verkapselung des offenen Labyrinths.<br />
Aus den erhobenen Daten bilden sich zum Schluss die folgenden Zahlen für die Werte Median so<strong>wie</strong> durchschnittliche<br />
Belohnung pro Schritt für das freie Labyrinth:<br />
freies Labyrinth RL UL+RL SL+RL UL+SL+RL UL+SL+RL+Enc.<br />
Median -3985.28 -3905 847 849 851<br />
Belohnung pro Schritt -25.48 -25.03 5.29 5.305 5.39<br />
So<strong>wie</strong> für das offene Labyrinth:<br />
offenes Labyrinth RL UL+RL SL+RL UL+SL+RL UL+SL+RL+Enc.<br />
Median 815.85 815.04 816.39 816.37 819.19<br />
Belohnung pro Schritt 4.36 4.6 4.66 4.65 4.72<br />
10<br />
5<br />
5<br />
0<br />
4<br />
-5<br />
3<br />
-10<br />
-15<br />
2<br />
-20<br />
1<br />
-25<br />
-30<br />
RL UL+RL SL+RL UL+SL+RL UL+SL+RL+Enc<br />
0<br />
RL UL+RL SL+RL UL+SL+RL UL+SL+RL+Enc<br />
Abbildung 5.17: Durchschnittliche Belohnung pro Schritt aller vorgestellten Kombinationen veranschaulicht.<br />
Abschließend lässt sich <strong>im</strong> Rahmen dieser beiden Labyrinth-Arten festhalten, dass das verwendete Unsupervised<br />
Verfahren zu Beginn eine Beschleunigen der Konvergenz erzielen kann, welche <strong>im</strong> späteren Verlauf allerdings nachlässt.<br />
Das Umgebungsmodell des Supervised Learnings erreicht <strong>im</strong> Falle des freien Labyrinths hingegen einen anhaltenden<br />
Effekt. Eine Kombination beider entspricht hierbei annähernd dem gleichen Verfahren, <strong>wie</strong> es zuvor die Kombination<br />
des Q-Learnings mit Umgebungsmodell darstellte und der daraus erzielte Nutzen hängt von der Anzahl der 1-Zustand<br />
breiten Gänge ab. Als weitere Verbesserung in diesen Labyrinthen stellte sich das Verkapseln erlernten Wissens heraus,<br />
da zum Ende der Lernphase eine steigende Anzahl von Standardaktionen definiert wird.<br />
51







