

Kapitel VI Neuronale Netze
Kapitel VI Neuronale Netze
Kapitel VI Neuronale Netze

Erfolgreiche ePaper selbst erstellen
Machen Sie aus Ihren PDF Publikationen ein blätterbares Flipbook mit unserer einzigartigen Google optimierten e-Paper Software.
Multi Layer Perzeptron<br />
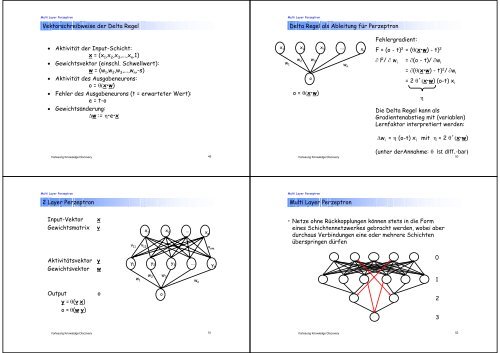
Vektorschreibweise der Delta Regel<br />
Multi Layer Perzeptron<br />
Delta Regel als Ableitung für Perzeptron<br />
Fehlergradient:<br />
<br />
<br />
<br />
<br />
<br />
Aktivität der Input-Schicht:<br />
x = (x 1 ,x 2 ,x 3 ,...,x n ,1)<br />
Gewichtsvektor (einschl. Schwellwert):<br />
w = (w 1 ,w 2 ,w 3 ,...,w n ,-s)<br />
Aktivität des Ausgabeneurons:<br />
o = x•w)<br />
Fehler des Ausgabeneurons (t = erwarteter Wert):<br />
e = t-o<br />
Gewichtsänderung:<br />
w := •e•x<br />
x 1 x 2 x 3 ...<br />
w w<br />
w 2 3<br />
1<br />
w n<br />
o<br />
o = x•w)<br />
x n<br />
F = (o - t) 2 = (x•w) - t) 2<br />
F/ w i<br />
= (o - t)/ w i<br />
= (x•w) - t) 2 / w i<br />
= 2 ´x•w) (o-t) x i<br />
<br />
Die Delta Regel kann als<br />
Gradientenabstieg mit (variablen)<br />
Lernfaktor interpretiert werden:<br />
w i = (o-t) x i mit = 2 ´x•w)<br />
Vorlesung Knowledge Discovery<br />
49<br />
Vorlesung Knowledge Discovery<br />
(unter derAnnahme: ist diff.-bar)<br />
50<br />
Multi Layer Perzeptron<br />
Multi Layer Perzeptron<br />
2 Layer Perzeptron<br />
Multi Layer Perzeptron<br />
Input-Vektor<br />
Gewichtsmatrix<br />
Aktivitätsvektor<br />
Gewichtsvektor<br />
x<br />
v<br />
y<br />
w<br />
v 12<br />
y 1 y 2 y 3 ...<br />
x 1 x 2 ... x m<br />
v nm<br />
y n<br />
w 2 w<br />
w 3<br />
1 w n<br />
• <strong>Netze</strong> ohne Rückkopplungen können stets in die Form<br />
eines Schichtennetzwerkes gebracht werden, wobei aber<br />
durchaus Verbindungen eine oder mehrere Schichten<br />
überspringen dürfen<br />
v 11<br />
52<br />
0<br />
1<br />
Output o<br />
y = (v . x)<br />
o = (w . y)<br />
o<br />
2<br />
3<br />
Vorlesung Knowledge Discovery<br />
51<br />
Vorlesung Knowledge Discovery













