

Wahrscheinlichkeit & Statistik Musterlösung Serie ... - FIM - ETH Zürich
Wahrscheinlichkeit & Statistik Musterlösung Serie ... - FIM - ETH Zürich
Wahrscheinlichkeit & Statistik Musterlösung Serie ... - FIM - ETH Zürich

Sie wollen auch ein ePaper? Erhöhen Sie die Reichweite Ihrer Titel.
YUMPU macht aus Druck-PDFs automatisch weboptimierte ePaper, die Google liebt.
<strong>ETH</strong> Zürich FS 2013<br />
D-MATH<br />
Hans Rudolf Künsch<br />
Koordinator<br />
Blanka Horvath<br />
<strong>Wahrscheinlichkeit</strong> & <strong>Statistik</strong><br />
Musterlösung <strong>Serie</strong> 14<br />
1. Beim Neyman-Pearson-Test der Hypothese H 0 : X ∼ f(x) dx gegen die Alternative<br />
H A : X ∼ f(x − 1) dx wird der Verwerfungsbereich bestimmt durch die<br />
Ungleichung<br />
f(x − 1)<br />
f(x)<br />
> c = c(α).<br />
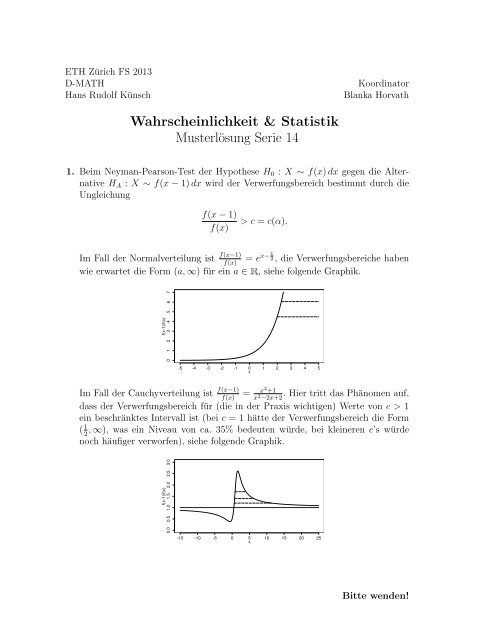
Im Fall der Normalverteilung ist f(x−1) = e x− 1 2 , die Verwerfungsbereiche haben<br />
f(x)<br />
wie erwartet die Form (a, ∞) für ein a ∈ R, siehe folgende Graphik.<br />
f(x-1)/f(x)<br />
0 1 2 3 4 5 6 7<br />
-5 -4 -3 -2 -1 0 1 2 3 4 5<br />
x<br />
Im Fall der Cauchyverteilung ist f(x−1) = x2 +1<br />
. Hier tritt das Phänomen auf,<br />
f(x) x 2 −2x+2<br />
dass der Verwerfungsbereich für (die in der Praxis wichtigen) Werte von c > 1<br />
ein beschränktes Intervall ist (bei c = 1 hätte der Verwerfungsbereich die Form<br />
( 1 , ∞), was ein Niveau von ca. 35% bedeuten würde, bei kleineren c’s würde<br />
2<br />
noch häufiger verworfen), siehe folgende Graphik.<br />
f(x-1)/f(x)<br />
0.0 0.5 1.0 1.5 2.0 2.5 3.0<br />
-15 -10 -5 0 5 10 15 20 25<br />
x<br />
Bitte wenden!
Die Erklärung ist, dass bei der Cauchyverteilung sehr grosse Werte sowohl unter<br />
H 0 als auch unter H A etwa gleich unwahrscheinlich sind. Deshalb ist es für nicht<br />
allzu grosse Werte von α beser, bei grosser Beobachtung X die Nullhypothese<br />
nicht zu verwerfen.<br />
Bei der Normalverteilung tritt dieses Phänomen nicht auf, da grosse X unter der<br />
Alternativhypothese sehr viel weniger unwahrscheinlich sind als unter H 0 .<br />
2. Betrachte folgende Figur:<br />
f 1(x)<br />
f (x)<br />
0<br />
f (x)<br />
0<br />
α<br />
f (x) 1<br />
Verwerfungsbereich<br />
0 1/2 1 3/2<br />
a) Für α ∈ (0, 1 2 ] wähle K′ ⊆ ( 1 2 , 1) mit µ L(K ′ ) = α (ist die Situation in<br />
der Figur) und als Verwerfungsbereich K = K ′ ∪ [1, ∞). Dieser Test ist<br />
offensichtlich ein mächtigster Test zum Niveau α, und es gilt φ = 1, falls<br />
f 1 (x) > f 0 (x), und φ = 0, falls f 1 (x) < f 0 (x) (also c = 1).<br />
Für α ∈ [ 1, 1) wähle 2 K′ ⊆ (0, 1) mit µ 2 L(K ′ ) = α − 1 und den Verwerfungsbereich<br />
K = K ′ ∪ ( 1 , ∞). Auch dieser Test ist mächtigst zum Niveau α, und<br />
2<br />
2<br />
er erfüllt die Bedingungen vom Skript mit c = 0.<br />
Solche Tests sind nicht eindeutig, da K ′ eine beliebige Teilmenge von ( 1, 1) 2<br />
bzw. von (0, 1 ) sein kann.<br />
2<br />
b) Für α ∈ ( 1, 1) (zum Beispiel für α = 3) wähle K = ( 1 , ∞). Dieser Test<br />
2 4 2<br />
verwirft immer, wenn die Alternative wahr ist. Er hat also maximale Macht<br />
E 1 [φ] = 1, obwohl er das zur Verfügung stehende Niveau nicht einmal ganz<br />
ausnützt: E 0 [φ] = 1 < 3.<br />
2 4<br />
Siehe nächstes Blatt!
3. Beim Vorzeichentest der Nullhypothese F −1 (0.5) = m lautet die Teststatistik<br />
T n,m = ∑ n<br />
i=1 I [X i >m] und der Test ist gegeben durch<br />
ϕ(x) = 1 falls ∣ Tn,m − n ∣<br />
2 > c(n, α),<br />
wobei x = (x 1 , . . . , x n ) die Beobachtungen, n die Anzahl der Beobachtungen und<br />
α das Niveau des Tests bezeichnet. Weil F als stetig angenommen wurde, ist T n,m<br />
unter der Nullhypothese Bin(n, 0.5)-verteilt. Also ist k = n − c(n, α) bestimmt<br />
2<br />
durch<br />
∑k−1<br />
( n<br />
k∑<br />
( n<br />
0.5<br />
j)<br />
n ≤ α < 0.5<br />
2<br />
j)<br />
n ,<br />
j=0<br />
und n 2 + c(n, α) = n − k. Wenn wir C ⊂ Rn+1 definieren durch<br />
j=0<br />
C = {(x 1 , . . . , x n , m); k ≤<br />
n∑<br />
I [xi >m] ≤ n − k},<br />
i=1<br />
dann ist der Schnitt A(m) = {(x 1 , . . . , x n ); (x 1 , . . . , x n , m) ∈ C} der Annahmebereich<br />
des Vorzeichentests zum Niveau α. Mit dem Dualitätssatz bildet der<br />
Schnitt B(x) = {m; (x 1 , . . . , x n , m) ∈ C} daher einen Vertrauensbereich zum<br />
Niveau 1 − α. Wenn x (1) < x (2) < . . . < x (n) die der Grösse nach geordneten<br />
Beobachtungen bezeichnet, dann gilt<br />
m ∈ [x (j) , x (j+1) ) ⇔<br />
n∑<br />
I [xi >m] = n − j.<br />
i=1<br />
Also ist m ∈ B(x) genau dann, wenn x (k) ≤ m < x (n+1−k) , d.h. (X (k) , X (n+1−k) )<br />
ist ein Vertrauensintervall für den Median zum Niveau 1 − α (weil F als stetig<br />
angenommen wurde, spielt es keine Rolle, ob man das offene oder abgeschlossene<br />
Intervall nimmt). Wegen des zentralen Grenzwertsatzes ist c(n, 0.95) ≈<br />
1.96 √ n/4 ≈ √ n, also ist das Intervall genähert gleich (X (n/2−<br />
√ n) , X (n/2+<br />
√ n) ).<br />
4. a) 1. Sei X die Zufallsvariable welche die Länge der Karotten modelliert, getestes<br />
wird auf den Parameter µ = E[X], die durchschnittliche Länge<br />
der Karotten. Die Nullhypothese ist die Behauptung des Gemüsehändlers,<br />
wir wollen testen ob sie sich widerlegen lässt, daraus ergibt sich ein<br />
linksseitiger Test mit µ 0 = 30cm und den Hypothesen H 0 : µ ≥ µ 0 H A :<br />
µ < µ 0 .<br />
2. Zweiseitiger Test mit µ 0 = 50g sowie den Hypothesen H 0 : µ = µ 0 H A :<br />
µ ≠ µ 0 .<br />
3. Rechtsseitiger Test mit µ 0 = 3mm sowie den Hypothesen H 0 : µ ≤<br />
µ 0 H A : µ > µ 0 .<br />
Bitte wenden!
4. Hier modelliert die Zufallsvariable X mit Wertebereich W X = [0, 1]<br />
den Anteil an holzigen Spargel, getestet wird wieder auf den durchschnittlichen<br />
Wert davon, also auf µ = E[X], aus der Behauptung des<br />
Gemüsehändlers ergibt sich ein rechtsseitiger Test mit µ 0 = 0.003 sowie<br />
den Hypothesen H 0 : µ ≤ µ 0 H A : µ > µ 0 .<br />
5. Zweiseitiger Test mit µ 0 = 0.4 sowie den Hypothesen H 0 : µ = µ 0 H A :<br />
µ ≠ µ 0 .<br />
b) Die Nullhypothese wurde verworfen obwohl sie stimmt, d.h. Fehler 1.Art.<br />
c) Die Nullhypothese wurde nicht verworfen obwohl sie falsch ist, d.h. Fehler<br />
2.Art.<br />
Bemerkung: Da wir ehrliche Gemüsehändler nicht ungerechtfertigt in Misskredit<br />
bringen wollen, müssen wir die <strong>Wahrscheinlichkeit</strong> für einen Fehler 1.Art gering<br />
halten, d.h. wenn wir seine Behauptung anzweifeln, dann müssen wir einen guten<br />
Grund haben dafür, und dieser ist die geringe <strong>Wahrscheinlichkeit</strong> für eine<br />
bestimmte Gesamtheit von Testausgängen falls die Behauptung stimmt (Fehler<br />
1.Art). Da es im Allgemeinen nicht gelingt beide Fehler klein zu halten, bedeutet<br />
ein Akzeptieren der Nullhypothese nicht, dass die Behauptung stimmt, sie konnte<br />
lediglich nicht widerlegt werden. Der Gemüsehändler ist also auf der sicheren Seite,<br />
sagt er die Wahrheit, dann hat er kaum was zu befürchten (Fehler 1.Art), und<br />
wenn er lügt, dann hat er in bestimmten Fällen sogar ein gute Chance (Fehler<br />
2.Art) nicht entlarvt zu werden.<br />
5. a) Die Stichprobe ist ungepaart.<br />
b) Da getestet werden soll, ob das Getränk eine positive Wirkung hat, wird<br />
einseitig getestet.<br />
c) Die Alternativhypothese, die von den vier Möglichkeiten am besten passt ist<br />
in dem Fall die Nummer 3., d.h. Das Getränk bewirkt eine bessere Leistung.<br />
Bemerkung: Die Nullhypothese lautet, dass die Leistung nach Einnahme des<br />
Getränkes genausogut oder schlechter ist.<br />
d) 1. richtig: Der P -Wert ist das kleinste Niveau, auf dem die Nullhypothese<br />
verworfen wird, und 0.01 < 0.034.<br />
2. falsch: Das Niveau gibt die <strong>Wahrscheinlichkeit</strong> an, die Nullhypothese<br />
zu verwerfen, obwohl sie richtig ist. Bei kleinerem Niveau wird daher<br />
weniger oft verworfen.<br />
3. richtig: Fehler 1. Art heisst, die Nullhypothese zu verwerfen, obwohl sie<br />
richtig ist.<br />
Siehe nächstes Blatt!
4. falsch: Beim t-Test ist das Niveau nur exakt richtig unter Normalverteilung,<br />
beim Wilcoxon-Test hingegen für beliebige stetige Verteilungen.<br />
5. richtig: Folgt aus dem Dualitätssatz. Der Annahmebereich bei α =1%<br />
ist grösser als bei α =5% (vergleiche 2.)<br />
6. richtig: Je kleiner |µ|, desto näher liegt die Alternative bei der Nullhypothese,<br />
und desto eher entscheidet man sich für die Nullhypothese statt<br />
für die Alternative.







