

A Guided Walk Down Wall Street: An Introduction to Econophysics
A Guided Walk Down Wall Street: An Introduction to Econophysics
A Guided Walk Down Wall Street: An Introduction to Econophysics

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
1046 Giovani L. Vasconcelos<br />
(22) and (23) then yields<br />
[<br />
lim E (Q n − t) 2] = 0.<br />
n→∞<br />
We have thus proven that Q n converges <strong>to</strong> t in the mean<br />
square sense. This fact suggests that ∆W 2 can be thought<br />
of as being of the order of ∆t, meaning that as ∆t → 0 the<br />
quantity ∆W 2 “resembles more and more” the deterministic<br />
quantity ∆t. In terms of differentials, we write<br />
[dW ] 2 = dt. (24)<br />
Alternatively, we could say that dW is of order √ dt:<br />
dW = O( √ dt). (25)<br />
(I remark parenthetically that the boundedness of the<br />
quadratic variation of the Brownian motion should be<br />
∑<br />
contrasted with the fact that its <strong>to</strong>tal variation, A n =<br />
n<br />
i=0 |∆W i|, is unbounded, that is, A n → ∞ as n → ∞,<br />
with probability 1; see [7].)<br />
<strong>An</strong>other important property of the Brownian motion<br />
W (t) is the fact that it is self-similar (or more exactly selfaffine)<br />
in the following sense:<br />
W (at) d = a 1/2 W (t), (26)<br />
for all a > 0. Here d = means equality in the sense of probability<br />
distribution, that is, the two processes W (at) and<br />
a 1/2 W (t) have exactly the same finite-dimensional distributions<br />
p(x 1 , t 1 ; ..., x n , t n ) for any choice of t i , i = 1, ..., n,<br />
and n ≥ 1. Self-similarity means that any finite portion of<br />
a Brownian motion path when properly rescaled is (statistically)<br />
indistinguishable from the whole path. For example,<br />
if we ‘zoom in’ in any given region (no matter how small)<br />
of a Brownian motion path, by rescaling the time axis by a<br />
fac<strong>to</strong>r of a and the vertical axis by a fac<strong>to</strong>r of √ a, we obtain<br />
a curve similar (statistically speaking) <strong>to</strong> the original path.<br />
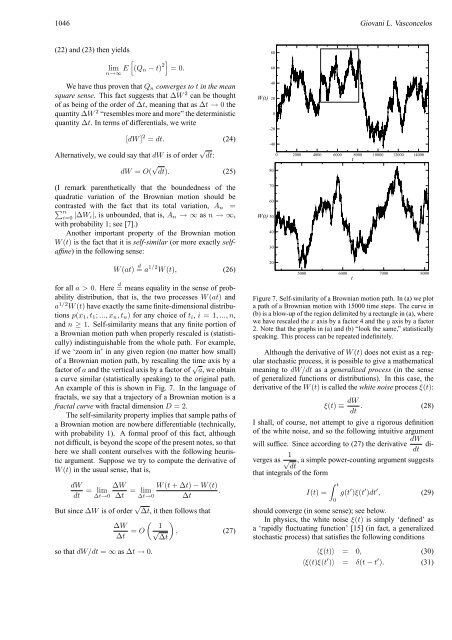
<strong>An</strong> example of this is shown in Fig. 7. In the language of<br />
fractals, we say that a trajec<strong>to</strong>ry of a Brownian motion is a<br />
fractal curve with fractal dimension D = 2.<br />
The self-similarity property implies that sample paths of<br />
a Brownian motion are nowhere differentiable (technically,<br />
with probability 1). A formal proof of this fact, although<br />
not difficult, is beyond the scope of the present notes, so that<br />
here we shall content ourselves with the following heuristic<br />
argument. Suppose we try <strong>to</strong> compute the derivative of<br />
W (t) in the usual sense, that is,<br />
dW<br />
dt<br />
∆W<br />
= lim<br />
∆t→0 ∆t<br />
= lim<br />
∆t→0<br />
W (t + ∆t) − W (t)<br />
.<br />
∆t<br />
But since ∆W is of order √ ∆t, it then follows that<br />
∆W<br />
∆t<br />
= O<br />
so that dW/dt = ∞ as ∆t → 0.<br />
( ) 1<br />
√ , (27)<br />
∆t<br />
W(t)<br />
W(t)<br />
80<br />
60<br />
40<br />
20<br />
0<br />
-20<br />
-40<br />
80<br />
70<br />
60<br />
50<br />
40<br />
30<br />
20<br />
0 2000 4000 6000 8000 10000 12000 14000<br />
t<br />
5000 6000 7000 8000<br />
t<br />
Figure 7. Self-similarity of a Brownian motion path. In (a) we plot<br />
a path of a Brownian motion with 15000 time steps. The curve in<br />
(b) is a blow-up of the region delimited by a rectangle in (a), where<br />
we have rescaled the x axis by a fac<strong>to</strong>r 4 and the y axis by a fac<strong>to</strong>r<br />
2. Note that the graphs in (a) and (b) “look the same,” statistically<br />
speaking. This process can be repeated indefinitely.<br />
Although the derivative of W (t) does not exist as a regular<br />
s<strong>to</strong>chastic process, it is possible <strong>to</strong> give a mathematical<br />
meaning <strong>to</strong> dW/dt as a generalized process (in the sense<br />
of generalized functions or distributions). In this case, the<br />
derivative of the W (t) is called the white noise process ξ(t):<br />
ξ(t) ≡ dW dt . (28)<br />
I shall, of course, not attempt <strong>to</strong> give a rigorous definition<br />
of the white noise, and so the following intuitive argument<br />
will suffice. Since according <strong>to</strong> (27) the derivative dW diverges<br />
as √ , a simple power-counting argument suggests<br />
dt<br />
1<br />
dt<br />
that integrals of the form<br />
I(t) =<br />
∫ t<br />
0<br />
g(t ′ )ξ(t ′ )dt ′ , (29)<br />
should converge (in some sense); see below.<br />
In physics, the white noise ξ(t) is simply ‘defined’ as<br />
a ‘rapidly fluctuating function’ [15] (in fact, a generalized<br />
s<strong>to</strong>chastic process) that satisfies the following conditions<br />
〈ξ(t)〉 = 0, (30)<br />
〈ξ(t)ξ(t ′ )〉 = δ(t − t ′ ). (31)














