

2000 PROGRESS REPORT - ENEA - Fusione
2000 PROGRESS REPORT - ENEA - Fusione
2000 PROGRESS REPORT - ENEA - Fusione

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
1. Magnetic Confinement<br />
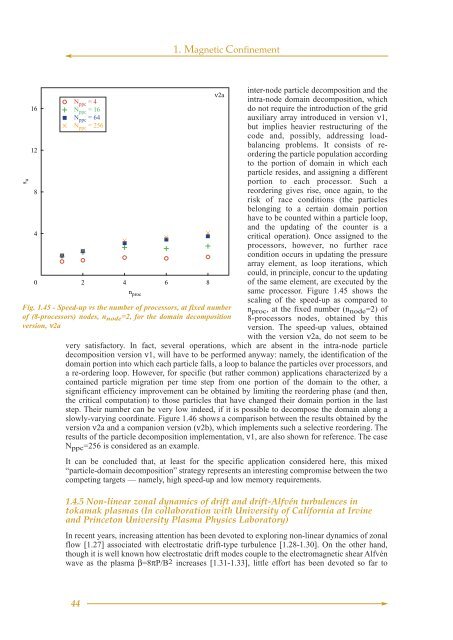
s u<br />
16<br />
12<br />
8<br />
4<br />
0<br />
N ppc = 4<br />
N ppc = 16<br />
N ppc = 64<br />
N ppc = 256<br />
2 4 6 8<br />
n proc<br />
Fig. 1.45 - Speed-up vs the number Fig. 1.45 of processors, at fixed number<br />
of (8-processors) nodes, n node =2, for the domain decomposition<br />
version, ν2a<br />
ν2a<br />
inter-node particle decomposition and the<br />
intra-node domain decomposition, which<br />
do not require the introduction of the grid<br />
auxiliary array introduced in version ν1,<br />
but implies heavier restructuring of the<br />
code and, possibly, addressing loadbalancing<br />
problems. It consists of reordering<br />
the particle population according<br />
to the portion of domain in which each<br />
particle resides, and assigning a different<br />
portion to each processor. Such a<br />
reordering gives rise, once again, to the<br />
risk of race conditions (the particles<br />
belonging to a certain domain portion<br />
have to be counted within a particle loop,<br />
and the updating of the counter is a<br />
critical operation). Once assigned to the<br />
processors, however, no further race<br />
condition occurs in updating the pressure<br />
array element, as loop iterations, which<br />
could, in principle, concur to the updating<br />
of the same element, are executed by the<br />
same processor. Figure 1.45 shows the<br />
scaling of the speed-up as compared to<br />
n proc , at the fixed number (n node =2) of<br />
8-processors nodes, obtained by this<br />
version. The speed-up values, obtained<br />
with the version ν2a, do not seem to be<br />
very satisfactory. In fact, several operations, which are absent in the intra-node particle<br />
decomposition version ν1, will have to be performed anyway: namely, the identification of the<br />
domain portion into which each particle falls, a loop to balance the particles over processors, and<br />
a re-ordering loop. However, for specific (but rather common) applications characterized by a<br />
contained particle migration per time step from one portion of the domain to the other, a<br />
significant efficiency improvement can be obtained by limiting the reordering phase (and then,<br />
the critical computation) to those particles that have changed their domain portion in the last<br />
step. Their number can be very low indeed, if it is possible to decompose the domain along a<br />
slowly-varying coordinate. Figure 1.46 shows a comparison between the results obtained by the<br />
version ν2a and a companion version (ν2b), which implements such a selective reordering. The<br />
results of the particle decomposition implementation, ν1, are also shown for reference. The case<br />
N ppc =256 is considered as an example.<br />
It can be concluded that, at least for the specific application considered here, this mixed<br />
“particle-domain decomposition” strategy represents an interesting compromise between the two<br />
competing targets — namely, high speed-up and low memory requirements.<br />
1.4.5 Non-linear zonal dynamics of drift and drift-Alfvén turbulences in<br />
tokamak plasmas (In collaboration with University of California at Irvine<br />
and Princeton University Plasma Physics Laboratory)<br />
In recent years, increasing attention has been devoted to exploring non-linear dynamics of zonal<br />
flow [1.27] associated with electrostatic drift-type turbulence [1.28-1.30]. On the other hand,<br />
though it is well known how electrostatic drift modes couple to the electromagnetic shear Alfvén<br />
wave as the plasma β=8πP/B2 increases [1.31-1.33], little effort has been devoted so far to<br />
44










