Hierarchical Multi-Affine (HMA) algorithm for fast and accurate ...
Hierarchical Multi-Affine (HMA) algorithm for fast and accurate ...
Hierarchical Multi-Affine (HMA) algorithm for fast and accurate ...

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
<strong>Hierarchical</strong> <strong>Multi</strong>-<strong>Affine</strong> (<strong>HMA</strong>) <strong>algorithm</strong> <strong>for</strong> <strong>fast</strong> <strong>and</strong> <strong>accurate</strong><br />
feature matching in minimally-invasive surgical images<br />
Gustavo A. Puerto-Souza, <strong>and</strong> Gian Luca Mariottini<br />
Abstract— The ability to find similar features between two<br />
distinct views of the same scene (feature matching) is essential<br />
in robotics <strong>and</strong> computer vision. We are here interested in<br />
the robotic-assisted minimally-invasive surgical scenario, <strong>for</strong><br />
which feature matching can be used to recover tracked features<br />
after prolonged occlusions, strong illumination changes, image<br />
clutter, or <strong>fast</strong> camera motion. In this paper we introduce the<br />
<strong>Hierarchical</strong> <strong>Multi</strong>-<strong>Affine</strong> (<strong>HMA</strong>) feature-matching <strong>algorithm</strong>,<br />
which improves over the existing methods by recovering a<br />
larger number of image correspondences, at an increased<br />
speed <strong>and</strong> with a higher accuracy <strong>and</strong> robustness. Extensive<br />
experimental results are presented that compare <strong>HMA</strong> against<br />
existing methods, over a large surgical-image dataset <strong>and</strong> over<br />
several types of detected features.<br />
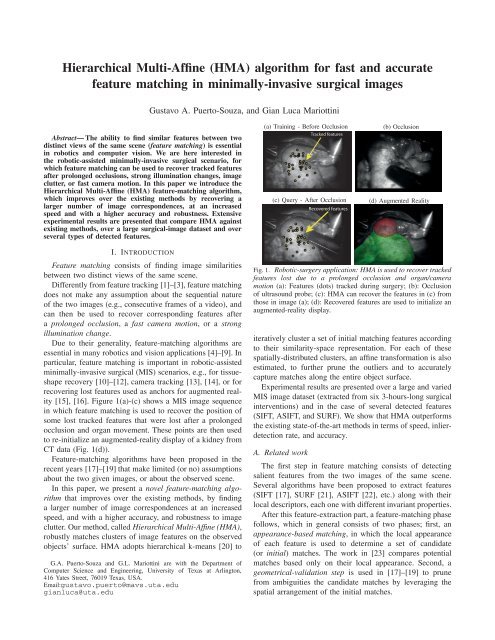
(a) Training - Be<strong>for</strong>e Occlusion<br />
Tracked features<br />
(c) Query - After Occlusion<br />
Recovered features<br />
(b) Occlusion<br />
(d) Augmented Reality<br />
I. INTRODUCTION<br />
Feature matching consists of finding image similarities<br />
between two distinct views of the same scene.<br />
Differently from feature tracking [1]–[3], feature matching<br />
does not make any assumption about the sequential nature<br />
of the two images (e.g., consecutive frames of a video), <strong>and</strong><br />
can then be used to recover corresponding features after<br />
a prolonged occlusion, a <strong>fast</strong> camera motion, or a strong<br />
illumination change.<br />
Due to their generality, feature-matching <strong>algorithm</strong>s are<br />
essential in many robotics <strong>and</strong> vision applications [4]–[9]. In<br />
particular, feature matching is important in robotic-assisted<br />
minimally-invasive surgical (MIS) scenarios, e.g., <strong>for</strong> tissueshape<br />
recovery [10]–[12], camera tracking [13], [14], or <strong>for</strong><br />
recovering lost features used as anchors <strong>for</strong> augmented reality<br />
[15], [16]. Figure 1(a)-(c) shows a MIS image sequence<br />
in which feature matching is used to recover the position of<br />
some lost tracked features that were lost after a prolonged<br />
occlusion <strong>and</strong> organ movement. These points are then used<br />
to re-initialize an augmented-reality display of a kidney from<br />
CT data (Fig. 1(d)).<br />
Feature-matching <strong>algorithm</strong>s have been proposed in the<br />
recent years [17]–[19] that make limited (or no) assumptions<br />
about the two given images, or about the observed scene.<br />
In this paper, we present a novel feature-matching <strong>algorithm</strong><br />
that improves over the existing methods, by finding<br />
a larger number of image correspondences at an increased<br />
speed, <strong>and</strong> with a higher accuracy, <strong>and</strong> robustness to image<br />
clutter. Our method, called <strong>Hierarchical</strong> <strong>Multi</strong>-<strong>Affine</strong> (<strong>HMA</strong>),<br />
robustly matches clusters of image features on the observed<br />
objects’ surface. <strong>HMA</strong> adopts hierarchical k-means [20] to<br />
G.A. Puerto-Souza <strong>and</strong> G.L. Mariottini are with the Department of<br />
Computer Science <strong>and</strong> Engineering, University of Texas at Arlington,<br />
416 Yates Street, 76019 Texas, USA.<br />
Email:gustavo.puerto@mavs.uta.edu<br />
gianluca@uta.edu<br />
Fig. 1. Robotic-surgery application: <strong>HMA</strong> is used to recover tracked<br />
features lost due to a prolonged occlusion <strong>and</strong> organ/camera<br />
motion (a): Features (dots) tracked during surgery; (b): Occlusion<br />
of ultrasound probe; (c): <strong>HMA</strong> can recover the features in (c) from<br />
those in image (a); (d): Recovered features are used to initialize an<br />
augmented-reality display.<br />
iteratively cluster a set of initial matching features according<br />
to their similarity-space representation. For each of these<br />
spatially-distributed clusters, an affine trans<strong>for</strong>mation is also<br />
estimated, to further prune the outliers <strong>and</strong> to <strong>accurate</strong>ly<br />
capture matches along the entire object surface.<br />
Experimental results are presented over a large <strong>and</strong> varied<br />
MIS image dataset (extracted from six 3-hours-long surgical<br />
interventions) <strong>and</strong> in the case of several detected features<br />
(SIFT, ASIFT, <strong>and</strong> SURF). We show that <strong>HMA</strong> outper<strong>for</strong>ms<br />
the existing state-of-the-art methods in terms of speed, inlierdetection<br />
rate, <strong>and</strong> accuracy.<br />
A. Related work<br />
The first step in feature matching consists of detecting<br />
salient features from the two images of the same scene.<br />
Several <strong>algorithm</strong>s have been proposed to extract features<br />
(SIFT [17], SURF [21], ASIFT [22], etc.) along with their<br />
local descriptors, each one with different invariant properties.<br />
After this feature-extraction part, a feature-matching phase<br />
follows, which in general consists of two phases; first, an<br />
appearance-based matching, in which the local appearance<br />
of each feature is used to determine a set of c<strong>and</strong>idate<br />
(or initial) matches. The work in [23] compares potential<br />
matches based only on their local appearance. Second, a<br />
geometrical-validation step is used in [17]–[19] to prune<br />
from ambiguities the c<strong>and</strong>idate matches by leveraging the<br />
spatial arrangement of the initial matches.
The <strong>algorithm</strong> in [17] initially matches first SIFT features<br />
according to the Euclidean distance between descriptors.<br />
Then, a geometric phase is en<strong>for</strong>ced to detect a predominant<br />
set of matches (inliers) that satisfy a unique affinetrans<strong>for</strong>mation<br />
constraint [24]. While this method can reliably<br />
discard many wrong matches, however only a limited<br />
number of those belonging to a predominant planar surface<br />
will be detected.<br />
The above issue was solved in [18], where multiple localaffine<br />
mappings are used to detect a larger number of<br />
matches over the entire non-planar object surface. However,<br />
due to its high computational time, this method can only be<br />
used <strong>for</strong> off-line data processing.<br />
The work in [19] uses a dissimilarity measure that measures<br />
the matches similarity based on both a geometric<br />
<strong>and</strong> an appearance constraint. Finally, an agglomerative step<br />
generates clusters of matches by iteratively merging similar<br />
ones (according to the dissimilarity measure). A drawback<br />
of this <strong>algorithm</strong> is due to its high number of parameters.<br />
Moreover, tuning these parameters is difficult because of<br />
their unclear physical interpretation.<br />
The <strong>HMA</strong> <strong>algorithm</strong> presented in this paper improves over<br />
the existing <strong>algorithm</strong> as described in what follows:<br />
• <strong>HMA</strong> is <strong>fast</strong> because of the adoption of hierarchical k-<br />
means in the clustering phase. In particular, when a large<br />
number of features are detected (e.g., when using HD<br />
images or extracting ASIFT features), <strong>HMA</strong> is almost<br />
two-orders-of-magnitude <strong>fast</strong>er than [19].<br />
• <strong>HMA</strong> is <strong>accurate</strong>: a large percentage of wrong matches<br />
is automatically removed. Furthermore, the cluster of<br />
affine trans<strong>for</strong>mations guarantees <strong>accurate</strong> feature recovery<br />
over the entire object’s surface.<br />
• <strong>HMA</strong> is easy to use: only a few thresholds need to be<br />
specified by the user, which have an intuitive physical<br />
interpretation.<br />
The paper is organized as follows: Sect. II describes the<br />
feature-matching problem <strong>and</strong> introduces the basic notation.<br />
Sect. III describes the <strong>HMA</strong> <strong>algorithm</strong>, while Sect. IV reports<br />
the results of our extensive experimental evaluation <strong>and</strong> the<br />
comparison of <strong>HMA</strong> with the state-of-the-art feature matching<br />
methods. Finally, in Sect. V we draw the conclusions<br />
<strong>and</strong> illustrate possible future extensions.<br />
II. OVERVIEW OF THE FEATURE MATCHING PROBLEM<br />
A. Keypoints <strong>and</strong> Descriptors: Notation<br />
Consider a pair of images, I t (training) <strong>and</strong> I q (query),<br />
<strong>and</strong> their two corresponding sets of detected image features<br />
F t <strong>and</strong> F q , respectively. For a generic image I, an image<br />
feature (e.g., SIFT) is defined as, f (k,d) ∈ F, consisting<br />
of a keypoint,k, <strong>and</strong> a local descriptor,d. Each keypointk <br />
[x,σ,θ] T contains the feature pixel-position, x = [x,y] T ,<br />
scale, σ, <strong>and</strong> orientation, θ. The descriptor d is a vector<br />
containing in<strong>for</strong>mation about the local appearance around<br />
the feature position.<br />
Based on the above notation, the feature-matching problem<br />
can be defined as retrieving the set of similar feature pairs<br />
(correspondences) from all the features extracted in both<br />
images. Such a (generic) matchmis defined asm (f t ,f q ),<br />
between features inF t <strong>and</strong>F q . In addition, we are interested<br />
to simultaneously estimate a mapping function, A i , that<br />
maps any feature from the training to the query images.<br />
B. Initial Appearance-based Feature Matching<br />
In feature matching, a set M of c<strong>and</strong>idate matches is<br />
initially determined by means of appeareance-based criteria<br />
(e.g., the Nearest-Neighbor distance Ratio (NNR)).<br />
In NNR, the best training feature c<strong>and</strong>idate to match the<br />
i-th f q i = (kq i ,dq i ), is the feature ft j(i) = (kt j(i) ,dt j(i) )<br />
with both the closest descriptor-distance, i.e.,<br />
j(i) = argmin j(i) ||d q i −dt j(i) || 2, <strong>and</strong> the smallest ratio<br />
between the closest <strong>and</strong> the second-closest descriptor<br />
distances, defined as,<br />
( )<br />
NNR(i)‖d q i −dt j(i) ‖ 2/ min<br />
j∈F t −{j(i)} ‖dq i −dt j ‖ 2 .<br />
This ratio has to be less than some threshold τ NNR which<br />
allows to discard many wrong matches that could arise, e.g.,<br />
due to ambiguity with the background. Tipically, a value <strong>for</strong><br />
the ratio-threshold is τ NNR ≥ 0.8 [17].<br />
However, due to image similarities, local appearance<br />
can generate a high percentage of outliers (i.e., wrong<br />
matches). As a consequence, the matches obtained from<br />
this appearance-based phase are unreliable <strong>and</strong> might not be<br />
sufficient in several applications, such as tracking recovery<br />
(see [25] <strong>for</strong> a per<strong>for</strong>mance comparison of appearance-based<br />
criteria).<br />
C. Similarity Trans<strong>for</strong>mation from Keypoints<br />
Corresponding features in both images can be related by a<br />
rigid image motion, which consists of a rotation, translation<br />
<strong>and</strong> scale. In particular, the two matching keypoints (k t i ,kq i )<br />
of match m i can be used to compute such a (similarity)<br />
trans<strong>for</strong>mation, which models the rigid mapping <strong>for</strong> a pair of<br />
image points [u t ,v t ] T ∈ I t <strong>and</strong> [u q ,v q ] T ∈ I q , as follows,<br />
[ u<br />
q<br />
v q ]<br />
[ ] cos(δθi ) −sin(δθ<br />
= δσ i )<br />
i<br />
sin(δθ i ) cos(δθ i )<br />
} {{ }<br />
R(δθ i )<br />
[ u<br />
t<br />
u t ]<br />
+<br />
[ ] δxi<br />
, (1)<br />
δy i<br />
where the scale ratio δσ i σ q i /σt i , the 2-D rotation angle<br />
δθ i θ q i −θt i , <strong>and</strong> the translation [δx i,δy i ] T [x q i ,yq i ]T −<br />
δσ i R(δθ i )[x t i ,yt i ]T .<br />
The similarity parameters s i = [δx i ,δy i ,δσ i ,δθ i ] T are<br />
<strong>fast</strong> to compute, <strong>and</strong> only require the matched-keypoint<br />
parameters.<br />
In general, a match m i is considered to agree with<br />
a generic trans<strong>for</strong>mation 1 , A, if the symmetric pixel reprojection<br />
error of mapping its keypoints is below some<br />
threshold τ, i.e,<br />
e A (˜x t i,˜x q i ) = 0.5‖˜xq i −A˜xt i‖+0.5‖˜x t i−A −1˜x q i ‖ < τ (2)
A. Overview<br />
III. THE <strong>HMA</strong> ALGORITHM<br />
Given a set of (appearance-based) c<strong>and</strong>idate matches, M,<br />
(see Sect. II-B), the goal of <strong>HMA</strong> is to compute (i) a set<br />
of outlier-free matches, M ∗ , <strong>and</strong> (ii) a set of spatiallydistributed<br />
image mappings, A ∗ = {A 1 ,A 2 ,...,A n }. Each<br />
of these trans<strong>for</strong>mations has the capability to map features<br />
lying on different portions of the training image, to corresponding<br />
features in the query image. As illustrated in<br />
Fig. 1, these mappings can then be used to recover in I q ,<br />
the position any image feature (not necessarily SIFT but also<br />
corners) that was lost due to occlusions or rapid camera<br />
motion.<br />
<strong>HMA</strong> achieves these tasks by clustering the initial matches<br />
according to a spatial <strong>and</strong> an affine constraints. We adopt<br />
a hierarchical k-means strategy [20] to iteratively cluster<br />
all the matching features, as illustrated in Fig. 2. The<br />
hierarchical structure of our <strong>algorithm</strong>, <strong>and</strong> its corresponding<br />
tree structure, present several advantages:<br />
• Speed: our divide-<strong>and</strong>-conquer expansion of the tree can<br />
be stopped until a desired pixel accuracy (e.g., in terms<br />
of the reprojection error e A ).<br />
• Robustness: the quantization of the k-means clustering<br />
will iteratively adjust at each level of the tree, by<br />
reassigning matches to more appropriate clusters.<br />
• Accuracy: The multiple <strong>Affine</strong> Trans<strong>for</strong>mations (AT)<br />
locally adapt more precisely to the non-planar regions of<br />
the observed scene than a single global-affine mapping.<br />
Fig. 3 shows all the phases of the <strong>HMA</strong> <strong>algorithm</strong>:<br />
the clustering phase partitions each node’s matches into k<br />
clusters, C 1 ,C 2 ,...,C k . The affine estimation phase, <strong>for</strong> each<br />
cluster simultaneously, estimates an affine trans<strong>for</strong>mation,<br />
1 E.g., similarity, affine, homography trans<strong>for</strong>mations, etc. [24]<br />
Node 1<br />
I t<br />
I t I q I t I q<br />
. . .<br />
A 1<br />
Node 1(1)<br />
Node 1(k)<br />
I t I q I t I q<br />
A 1(1)<br />
. . .<br />
Root node<br />
I q<br />
Initial matches<br />
A 1(k)<br />
Node k<br />
Fig. 2. <strong>HMA</strong> hierarchically quantizes matches according to their spatial<br />
position on the object’s surface.<br />
Node 1<br />
<strong>Affine</strong> Est.<br />
Phase<br />
Further<br />
Expansion<br />
Clustering<br />
Phase<br />
Leaf<br />
node<br />
A 1 , M 1 ,O 1<br />
A ′ 1 , M′ 1 ,O′ 1<br />
M ′ 1 ∪ O′ 1<br />
Root node<br />
Initial Matches<br />
Clustering<br />
Phase<br />
Correction<br />
Phase<br />
Leaf<br />
node<br />
Leaf<br />
node<br />
<strong>Affine</strong> Est.<br />
Phase<br />
Clustering<br />
Phase<br />
C 1<br />
C1 C k<br />
C 1 C k<br />
Node 1(1) Node1(k) Node Node k(1) . . . k(k)<br />
M ′ 1(1) ∪ O′ i(1)<br />
Fig. 3.<br />
yes<br />
. . .<br />
no<br />
. . .<br />
M ′ 1(k) ∪ O′ i(k)<br />
C k<br />
M ′ k(1) ∪ O′ j(1)<br />
Leaf<br />
node<br />
Node k<br />
A k ,M k ,O k<br />
A ′ k ,M′ k ,O′ k<br />
no<br />
Further<br />
Leaf<br />
Expansion<br />
node<br />
M ′ k ∪ O′ k<br />
M ′ k(k) ∪ O′ j(k)<br />
.<br />
.<br />
Block diagram of the <strong>HMA</strong> feature-matching <strong>algorithm</strong>.<br />
yes<br />
Leaf<br />
node<br />
A i , the sets of inliers, M i , <strong>and</strong> the outliers O i . A correction<br />
phase is used to reassign matches to more adequate clusters<br />
<strong>and</strong>, if necessary, to obtain an updated affine mapping, A ′ i<br />
(<strong>and</strong> new sets M ′ i <strong>and</strong> O′ i ). Each cluster defines a new child<br />
node as N j(i) , where j(·) is the function that determines the<br />
index of the cluster i in the tree structure. Finally, a criteria<br />
based on the matches’ reprojection error, e A , is employed to<br />
determine if these new nodes require further clustering.<br />
These three phases are repeated until each branch reaches a<br />
leaf node. Then, the set of outlier-free correspondences,M ∗ ,<br />
<strong>and</strong> the set of trans<strong>for</strong>mations, A ∗ , are extracted from the<br />
leaf nodes that satisfy a threshold over the minimal number<br />
of inliers, i.e., |M i | ≥ τ c . Once a leaf is reached, a final<br />
validation step is used to recover those outliers that might<br />
be potential inliers <strong>for</strong> other nodes.<br />
B. Clustering phase<br />
In this phase (see Fig. 3) the input matches are partitioned<br />
into k subsets by using k-means over an extended<br />
feature space, consisting of both the matches’ similaritytrans<strong>for</strong>mation<br />
parameters, as well as their (keypoint position<br />
in the query image). The resulting clustersC 1 ,C 2 ,...,C k , are<br />
illustrated in the example of Fig. 4. Note that each cluster<br />
represents a new branch of the tree at the current level.<br />
C. Similarity-space clustering<br />
For all the matches in each node, the four similarity trans<strong>for</strong>mation<br />
parameters [δx,δy,δσ,δθ] T are first computed<br />
(c.f., Sect. II-C). Clustering in this similarity space is the key,<br />
since it will result in clusters with close similarity parameters<br />
(representing indeed an initial approximation <strong>for</strong> the AT).
Training<br />
Query<br />
Fig. 4. Clustering phase: Example of the partition of matches. Note each<br />
symbol (<strong>and</strong> color) represents a different cluster (better seen in color).<br />
From our experiments, we noticed that this step does not<br />
always ensure that the clusters are disjoint, which would<br />
be ideal in order to define a unique affine trans<strong>for</strong>mation<br />
features <strong>for</strong> that portion of the scene. For this reason, we<br />
apply k-means to an extended (six-dimensional) similarity<br />
space 2 given by [x q ,y q ,δx,δy,δσ,δθ] T .<br />
We also noticed that, in earlier levels of the tree, the translation<br />
parameters [δx,δy] are more in<strong>for</strong>mative in isolating<br />
outliers. On the other h<strong>and</strong>, in latter levels of the tree, the<br />
position parameters [x q ,y q ] become more important 3 , <strong>and</strong><br />
[δx,δy] tends to be less in<strong>for</strong>mative. Finally, we noticed that<br />
δσ <strong>and</strong> δθ are not very in<strong>for</strong>mative <strong>and</strong> can be very sensitive<br />
to changes of view, in particular when the observed object<br />
is non-planar.<br />
Due to the above empirical observations, a scaling vector<br />
W was chosen to adaptively weight the relative importance<br />
of those similarity parameters be<strong>for</strong>e applying k-means.<br />
Our strategy varies W depending on the values of the AT<br />
residuals. As from what discussed above, W will put more<br />
importance on the translation (than on the other parameters)<br />
when the cluster’s AT is not adequate to model the matches<br />
(e.g., due to the large number of outliers such as in the initial<br />
levels of the tree). When the number of outliers is reduced,<br />
W will reduce its importance on the translation parameters,<br />
<strong>and</strong> increase its weight values on the weight <strong>for</strong> the position<br />
(thus en<strong>for</strong>cing spatial contiguity of the clusters).<br />
The weights W are computed by interpolating between<br />
two given weigh values W i (initial), <strong>and</strong> W f (final), as<br />
follows: W = W i + (W f − W i )α(¯r), where ¯r represent<br />
the average of all the symmetric reprojection errors, <strong>and</strong> α<br />
is a decreasing function with image in the interval [0,1],<br />
defined as,<br />
⎧<br />
⎨ ( 1 ) if ¯r ≤ τ R<br />
α(¯r) = ¯r−τ<br />
⎩ 1−erf √ r<br />
,<br />
otherwise<br />
2σ 2 w<br />
where τ R is the mapping maximum-error threshold, <strong>and</strong> σ w<br />
is a parameter which smooths the shape of α(¯r).<br />
Finally, the dataset is scaled according to these weights,<br />
i.e., Q [x q ,y q ,δx,δy,δσ,δθ]W, which is then clustered<br />
by k-means.<br />
D. <strong>Affine</strong>-estimation phase<br />
The keypoints (k t ,k q ) contained in each cluster C i are<br />
used in the affine-trans<strong>for</strong>mation estimation phase to com-<br />
2 This six-dimensional dataset is normalized (each column vector will have<br />
norm one) <strong>and</strong> scaled (with respect to each column).<br />
3 In fact, spatial contiguity of the clusters has higher priority.<br />
pute A i . RANSAC is used, <strong>for</strong> a given pixel error threshold<br />
τ R , to provide a robust estimate of A i , as well as to obtain<br />
the inliers M i . The affine model A i maps a generic image<br />
point [u t ,v t ] T ∈ I t (in the corresponding cluster C i ) to<br />
[û q ,ˆv q ] T ∈ I q , according to:<br />
[ûq<br />
ˆv q ]<br />
=<br />
[<br />
m1 m 2<br />
m 3<br />
m 4<br />
][ u<br />
t<br />
v t ]<br />
+<br />
[ ]<br />
m5<br />
. (3)<br />
m 6<br />
The parameters in A i represent the translation, rotation,<br />
<strong>and</strong> shear associated with the AT. The vector m <br />
[m 1 ,m 2 ,...,m 6 ] can be estimated at each RANSAC iteration<br />
by r<strong>and</strong>omly picking triplets of matches <strong>and</strong> by using<br />
them to solve <strong>for</strong> m in a least-squares sense from (3). Fig. 5<br />
shows an example of the AT <strong>and</strong> the set of inliers. The<br />
colored boxes indicate how each region is mapped between<br />
images. As observed, these regions nicely capture keypoints<br />
according to the slope of their local surface.<br />
Fig. 5.<br />
Training<br />
Query<br />
Example of AT (the planar regions) <strong>and</strong> inliers <strong>for</strong> each cluster.<br />
In order to eliminate the isolated matches with large<br />
residuals 4 , we adopt a non-parametric outlier-detection technique<br />
[26]. In particular, a threshold τ o is first computed<br />
from the statistics of the symmetric reprojection errors, <strong>and</strong><br />
used to discard matches with an error larger than τ o . This<br />
threshold is computed as τ o q 3 +γ(q 3 −q 1 ), where q i is<br />
the i-th quartile of the error over all the matches, <strong>and</strong> γ is a<br />
factor 5 .<br />
E. Correction phase<br />
In the correction phase the outliers O i are reassigned to<br />
other, more appropriate) clusters <strong>and</strong>, if necessary, the ATs<br />
are recomputed with the new set of features. In particular,<br />
Linear Discriminant Analysis (LDA) [27] is used to separate<br />
features belonging to all the known classes (clusters) in the<br />
query image, thus guaranteeing non overlap among the final<br />
clusters.<br />
F. Stop Criteria<br />
In order to stop the expansion of a i-th node, <strong>and</strong><br />
to deem it as a leaf node, <strong>HMA</strong> examines the number<br />
of inliers (consensus), |M i |, <strong>and</strong> the ratio of inliers,<br />
ρ i |M i |/(|M i |+|O i |). In particular, a node is deemed as<br />
a leaf when |M i | < τ c or ρ i > τ ρ . Note that these thresholds<br />
have indeed a very intuitive interpretation <strong>and</strong> were fixed <strong>for</strong><br />
our experiments (c.f., Sect. IV).<br />
4 These matches could negatively affect subsequent clustering phases.<br />
5 γ has been fixed to 3/2, as in [26].
Method Avg. Error Time % Inl. Avg. Error Time % Inl. Avg. Error Time % Inl.<br />
(SIFT)(pix) (SIFT)(s) (SIFT) (SURF)(pix) (SURF)(s) (SURF) (ASIFT)(pix) (ASIFT)(s) (ASIFT)<br />
Lowe 22.90±24.67 0.38 27.7% 20.77±22.15 0.40 34.6% 19.68±20.38 4.54 34.4%<br />
AMA 4.37±6.18 7.98 58.5% 4.45±7.38 13.00 69.4% 2.48±2.76 133.47 76.2%<br />
Cho 6.33±8.89 0.58 59.9% 6.92±6.83 0.56 66.6% 9.37±23.29 595.18 40.6%<br />
<strong>HMA</strong> 4.30±4.75 0.73 59.3% 4.44±6.66 0.67 66.7% 3.00±2.84 5.99 73.0%<br />
IV. EXPERIMENTAL RESULTS AND DISCUSSION<br />
We validated the per<strong>for</strong>mance of the <strong>HMA</strong> <strong>algorithm</strong> in<br />
two scenarios: (i) a fully controlled in-lab experiment, <strong>and</strong><br />
(ii) a real MIS scenario, composed of almost 100 images<br />
extracted from 6 surgical interventions. For each image,<br />
we measured the inlier ratio 6 that is descriptive of the<br />
detection power of our <strong>algorithm</strong>, the mapping accuracy over<br />
a set of manually-labelled ground-truth correspondences (per<br />
image), <strong>and</strong> the computational time. The computational time<br />
is measured in seconds of timer CPU 7 required by each run<br />
of each <strong>algorithm</strong>.<br />
In addition, we compared <strong>HMA</strong> against other recent<br />
<strong>algorithm</strong>s: Lowe’s [17], AMA [18], <strong>and</strong> Cho’s [19], when<br />
using either SIFT [17], SURF [21], or ASIFT [22] features.<br />
Our implementation of <strong>HMA</strong> considered the following<br />
fixed parameters: k = 4, τ R = 5 [pixels],<br />
W i = [0.2,0.2,0.25,0.25,0.05,0.05] T , W f =<br />
[0.5,0.5,0,0,0,0] T , which were chosen after an extensive<br />
analysis.<br />
In order to provide a fair comparison between the a<strong>for</strong>ementioned<br />
<strong>algorithm</strong>s, we used the same sets of initial<br />
matches 8 . We consider a threshold of 5 pixels <strong>for</strong> AMA <strong>and</strong><br />
Lowe, while a cutoff value of 25 in the linkage function was<br />
chosen <strong>for</strong> Cho.<br />
A. In-lab experiment<br />
In this experiment a pair of images with resolution 640×<br />
480 were used. The initial matches are 354, 330 <strong>and</strong> 4903<br />
<strong>for</strong> SIFT, SURF, <strong>and</strong> ASIFT, respectively. The ground-truth<br />
corresponding corners are 41 manually-selected matches.<br />
Table I provides detailed statistical results of the <strong>algorithm</strong>s’<br />
per<strong>for</strong>mance <strong>for</strong> all the features. The second, fifth<br />
<strong>and</strong> eighth columns show the mean <strong>and</strong> st<strong>and</strong>ard deviation<br />
of the symmetric reprojection error, the third, sixth <strong>and</strong> ninth<br />
indicate the computational time (in seconds), <strong>and</strong> the <strong>for</strong>th,<br />
seventh <strong>and</strong> tenth contain the percentage of inliers.<br />
Discussion: From the results in Table I, we observe that<br />
<strong>HMA</strong> achieves better results than AMA in terms of speed<br />
(approximately 11, 19, <strong>and</strong> 22 times <strong>fast</strong>er <strong>for</strong> SIFT, SURF,<br />
<strong>and</strong> ASIFT, respectively). While <strong>HMA</strong> requires slightly<br />
higher computational time when compared to Cho (in SIFT<br />
<strong>and</strong> SURF), however <strong>HMA</strong> obtains a reduced reprojection<br />
error. Furthermore, when using ASIFT features (in general<br />
more than 4000 are detected per image), <strong>HMA</strong> requires<br />
significant less computational time when compared to Cho.<br />
6 Inliers ratio = no. of inliers/no. of initial matches.<br />
7 i7, 2.20GHz.<br />
8 The initial matches are computed using NN distance ratio with thresholds<br />
0.9 (SIFT), 0.8 (SURF), <strong>and</strong> 0.8 (ASIFT).<br />
TABLE I<br />
In-lab experiment: Algorithms’ per<strong>for</strong>mance<br />
B. Surgical-images dataset<br />
Each laparoscopic image has a resolution of 704 × 480<br />
pixels, <strong>and</strong> the set of ground-truth correspondences contains<br />
an average of 20 points. Table II summarizes the results<br />
obtained by the four feature-matching <strong>algorithm</strong>s.<br />
Discussion: <strong>HMA</strong> achieves comparable accuracy than<br />
AMA, but with a significantly lower computational ef<strong>for</strong>t.<br />
In fact, <strong>HMA</strong> is approximately 21 times <strong>fast</strong>er than AMA<br />
<strong>for</strong> both SIFT <strong>and</strong> SURF, <strong>and</strong> 66 times <strong>for</strong> ASIFT. Furthermore,<br />
<strong>HMA</strong> demonstrates a smaller reprojection error<br />
than Cho’s, with a comparable time (note Cho’s larger<br />
st<strong>and</strong>ard deviation) <strong>for</strong> SIFT <strong>and</strong> SURF. As from the previous<br />
results, <strong>HMA</strong> shows a dramatic lower computation time<br />
(<strong>and</strong> lower accuracy cost) with a high number of ASIFT<br />
matches. Note that <strong>HMA</strong> has an inlier ratio comparable to<br />
other methods. Finally, <strong>HMA</strong> achieves high stability over<br />
all the experiment’s image pairs. These results suggest that<br />
<strong>HMA</strong> <strong>for</strong>mulation achieves a good balance between speed<br />
<strong>and</strong> accuracy.<br />
Figs. 6 <strong>and</strong> show qualitative examples of the matching<br />
per<strong>for</strong>mance of the four <strong>algorithm</strong>s <strong>for</strong> SIFT. Note that Lowe<br />
is not able to fully adapt to the non-planar surface in both<br />
cases, while AMA, Cho, <strong>and</strong> <strong>HMA</strong> obtain similar results<br />
(covering most of the organ’s surface).<br />
V. CONCLUSIONS<br />
In this work we presented <strong>HMA</strong>, a novel feature-matching<br />
<strong>algorithm</strong>, <strong>and</strong> we applied to robotic-assisted minimallyinvasive<br />
surgery (MIS). The MIS scenario is challenging<br />
because laparoscopic images have a lot of clutter, non-planar<br />
structures, changes in viewpoint, <strong>and</strong> organ de<strong>for</strong>mations.<br />
<strong>HMA</strong> improves over existing methods by achieving a lower<br />
computational time, <strong>and</strong> a higher accuracy <strong>and</strong> robustness to<br />
identify many matches. This comparison was made over a<br />
very large <strong>and</strong> carefully annotated MIS-image dataset, <strong>and</strong><br />
over three most-popular feature descriptors (SIFT, SURF,<br />
<strong>and</strong> ASIFT). As future work we plan to include fusion of<br />
descriptors <strong>and</strong> to further improve <strong>HMA</strong> computational time.<br />
REFERENCES<br />
[1] Bruce D. Lucas <strong>and</strong> Takeo Kanade. An iterative image registration<br />
technique with an application to stereo vision (ijcai). In Proc. of the<br />
7th Int. Joint Conference on Artificial Intelligence, pages 674–679,<br />
April 1981.<br />
[2] D. Stoyanov, G. Mylonas, F. Deligianni, A. Darzi, <strong>and</strong> G. Yang. Softtissue<br />
motion tracking <strong>and</strong> structure estimation <strong>for</strong> robotic assisted mis<br />
procedures. MICCAI, pages 139–146, 2005.<br />
[3] R. Richa, A.P. L Bo, <strong>and</strong> P. Poignet. Towards robust 3d visual tracking<br />
<strong>for</strong> motion compensation in beating heart surgery. Medical Image<br />
Analysis, 15(3):302–1315, 2010.<br />
[4] D. Scaramuzza <strong>and</strong> F. Fraundorfer. Visual odometry : Tutorial. IEEE<br />
Robotics Automation Magazine, 18(4):80–92, Dec. 2011.
Method Avg. Error Avg. Time % Inl. Avg. Error Avg. Time % Inl. Avg. Error Avg. Time % Inl.<br />
(SIFT) (SIFT) (SIFT) (SURF) (SURF) (SURF) (ASIFT) (ASIFT) (ASIFT)<br />
Lowe 4.66±4.24 0.37±0.15 34% 4.06±3.64 0.36±0.06 28% 4.77±4.25 1.83±1.57 35%<br />
AMA 2.49±2.42 5.74±4.45 40% 3.11±3.57 11.16±3.55 34% 2.57±2.85 162.43±136.88 46%<br />
Cho 3.56±3.35 0.31±0.12 39% 4.44±5.06 0.41±0.17 39% 7.56±11.16 116.10±162.39 31%<br />
<strong>HMA</strong> 2.84±2.64 0.27±0.1 39% 3.70±3.45 0.51±0.13 32% 3.62±3.55 2.44±1.11 50%<br />
I t<br />
(a) Lowe<br />
TABLE II<br />
MIS dataset: Algorithms’ per<strong>for</strong>mance<br />
I q<br />
I t<br />
(b) AMA<br />
I q<br />
I t<br />
(c) Cho<br />
I q<br />
I t<br />
(d) <strong>HMA</strong><br />
I q<br />
Fig. 6. Qualitative example of the matching per<strong>for</strong>mance <strong>for</strong> SIFT features.<br />
I t<br />
I q<br />
I t<br />
(a) Lowe<br />
(b) AMA<br />
I q<br />
I t<br />
(c) Cho<br />
I q<br />
I t<br />
(d) <strong>HMA</strong><br />
I q<br />
Fig. 7.<br />
[5] F. Rothganger, S. Lazebnik, C. Schmid, <strong>and</strong> J. Ponce. 3d object<br />
modeling <strong>and</strong> recognition using local affine-invariant image descriptors<br />
<strong>and</strong> multi-view spatial constraints. Proc. IEEE/RSJ Int. Conf. Intel.<br />
Robots Syst, 66(3):231–259, 2011.<br />
[6] M. Brown <strong>and</strong> D.G. Lowe. Automatic panoramic image stitching using<br />
invariant features. Int. J. Comp. Vis., 74(1):59–73, 2007.<br />
[7] Hailin Jin, P. Favaro, <strong>and</strong> S. Soatto. Real-time feature tracking <strong>and</strong><br />
outlier rejection with changes in illumination. In Proc. IEEE Intern.<br />
Conf. on Computer Vision, volume 1, pages 684–689, 2001.<br />
[8] P. Mountney, B. Lo, S. Thiemjarus, D. Stoyanov, <strong>and</strong> G. Zhong-<br />
Yang. A probabilistic framework <strong>for</strong> tracking de<strong>for</strong>mable soft tissue<br />
in minimally invasive surgery. In MICCAI, pages 34–41. Springer,<br />
2007.<br />
[9] P. Mountney <strong>and</strong> G.Z. Yang. Motion compensated slam <strong>for</strong> image<br />
guided surgery. MICCAI, pages 496–504, 2010.<br />
[10] Benny P. L. Lo, Marco Visentini-Scarzanella, Danail Stoyanov, <strong>and</strong><br />
Guang-Zhong Yang. Belief propagation <strong>for</strong> depth cue fusion in<br />
minimally invasive surgery. In MICCAI, pages 104–112, 2008.<br />
[11] Marco Visentini-Scarzanella, George P. Mylonas, Danail Stoyanov,<br />
<strong>and</strong> Guang-Zhong Yang. i-brush: A gaze-contingent virtual paintbrush<br />
<strong>for</strong> dense 3d reconstruction in robotic assisted surgery. In Med. Im.<br />
Comp. <strong>and</strong> Comp. Ass. Int., pages 353–360, 2009.<br />
[12] J. Totz, P. Mountney, D. Stoyanov, <strong>and</strong> G.-Z. Yang. Dense surface<br />
reconstruction <strong>for</strong> enhanced navigation in MIS. In MICCAI, pages<br />
89–96, 2011.<br />
[13] M. Hu, G.P. Penney, D. Rueckert, P.J. Edwards, F. Bello, R. Casula,<br />
M. Figl, <strong>and</strong> D.J. Hawkes. Non-rigid reconstruction of the beating<br />
heart surface <strong>for</strong> minimally invasive cardiac surgery. In MICCAI, 2009.<br />
[14] P. Mountney, D. Stoyanov, <strong>and</strong> Guang-Zhong Yang;. Threedimensional<br />
tissue de<strong>for</strong>mation recovery <strong>and</strong> tracking. IEEE Signal<br />
Processing Magazine, 27:14–24, 2010.<br />
[15] L.M. Su, B.P. Vagvolgyi, R. Agarwal, C.E. Reiley, R.H. Taylor, <strong>and</strong><br />
G.D. Hager. Augmented reality during robot-assisted laparoscopic<br />
Qualitative example of the matching per<strong>for</strong>mance <strong>for</strong> ASIFT features.<br />
partial nephrectomy: Toward real-time 3d-ct to stereoscopic video<br />
registration. Urology, 73(4):896–900, 2009.<br />
[16] O. Ukimura <strong>and</strong> I.S. Gill. Image-fusion, augmented reality, <strong>and</strong><br />
predictive surgical navigation. Urologic Clinics of North America,<br />
36(2):115 – 123, 2009.<br />
[17] D.G. Lowe. Distinctive image features from scale-invariant keypoints.<br />
Int. J. Comp. Vis., 60(2):91–110, 2004.<br />
[18] G. A. Puerto-Souza, M. Adibi, J. A. Cadeddu, <strong>and</strong> G.L. Mariottini.<br />
Adaptive multi-affine (AMA) feature-matching <strong>algorithm</strong> <strong>and</strong><br />
its application to minimally-invasive surgery images. In IEEE/RSJ<br />
International Conference on Intelligent Robots <strong>and</strong> Systems, pages<br />
2371 –2376, sept. 2011.<br />
[19] M. Cho, J. Lee, <strong>and</strong> K.M. Lee. Feature correspondence <strong>and</strong> de<strong>for</strong>mable<br />
object matching via agglomerative correspondence clustering. In Proc.<br />
9th Int. Conf. Comp. Vis., pages 1280–1287, 2009.<br />
[20] H. Trevor, T. Robert, <strong>and</strong> F. Jerome. The elements of statistical<br />
learning: data mining, inference <strong>and</strong> prediction. New York: Springer-<br />
Verlag, 1(8):371–406, 2001.<br />
[21] H. Bay, T. Tuytelaars, <strong>and</strong> L. Van Gool. SURF: Speeded up robust<br />
features. In Proc. European Comp Vis. Conf, pages 404–417. Springer,<br />
2006.<br />
[22] J.M. Morel <strong>and</strong> G. Yu. ASIFT: A new framework <strong>for</strong> fully affine<br />
invariant image comparison. Journal on Imaging Sciences, 2(2):438–<br />
469, 2009.<br />
[23] K. Mikolajczyk <strong>and</strong> C. Schmid. Scale & affine invariant interest point<br />
detectors. Int. J. Comp. Vis., 60(1):63–86, 2004.<br />
[24] R. Hartley <strong>and</strong> A. Zisserman. <strong>Multi</strong>ple view geometry in computer<br />
vision. Cambridge Univ Press, 2000.<br />
[25] K. Mikolajczyk <strong>and</strong> C. Schmid. A per<strong>for</strong>mance evaluation of local<br />
descriptors. IEEE Trans. Pattern Anal., 60:1615–1630, 2005.<br />
[26] J.W. Tukey. Exploratory data analysis. Reading, MA, 1977.<br />
[27] Christopher M. Bishop. Pattern Recognition <strong>and</strong> Machine Learning.<br />
Springer-Verlag New York, Inc., Secaucus, NJ, USA, 2006.