A new correlation for predicting hydrate formation conditions for ...
A new correlation for predicting hydrate formation conditions for ...
A new correlation for predicting hydrate formation conditions for ...

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
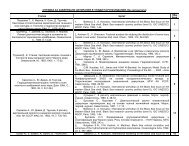
( )A.A. Elgibaly, A.M. ElkamelrFluid Phase Equilibria 152 1998 23–42 27architecture Ž Fig. 2 .. This type of network contains a layer of input neurons, a layer of output neurons,and one or several hidden layers of intermediate neurons. All the neurons are connected with differentweights. In addition, there is a bias neuron that is connected to each neuron in the hidden and outputlayers. The input layer receives input from the outside world and processes them and transmits themto the hidden layer. The output from a neuron in the hidden and the output layers is also given by Eq.Ž 6 .. In this case, the input I to a neuron in these layers is calculated from:ž Ý /iI s W O qW O Ž 7.i ij j iB Bjwhere the sum over j represents all neurons in the previous layer and OBis an invariant output fromthe bias neuron. The weight Wijrepresents the connection weight between neurons i and j and theweight WiBis the connection weight between neuron i and the bias neuron.The back-propagation neural network is applicable to a wide variety of problems and is thepredominant supervised training algorithm. The term ‘back-propagation’ indicates the method bywhich the network is trained, and the term ‘supervised learning’ implies that the network is trainedthrough a set of available input–output patterns. The network is repeatedly exposed to theseinput–output relationships and the weights among the neurons are continuously adjusted until thenetwork ‘learns’ the correct input–output behavior. Initially, all the weights are set randomly and thedifference or error between the desired and calculated outputs is calculated. This error is propagatedback through the network and is used to update the weights among neurons iteratively. This updateFig. 2. A one hidden layer feed <strong>for</strong>ward neural network.