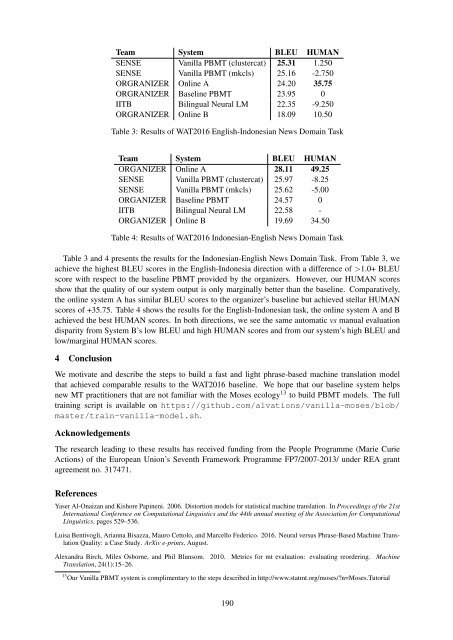
Team System BLEU HUMAN SENSE Vanilla PBMT (clustercat) 25.31 1.250 SENSE Vanilla PBMT (mkcls) 25.<strong>16</strong> -2.750 ORGRANIZER Online A 24.20 35.75 ORGRANIZER Baseline PBMT 23.95 0 IITB Bilingual Neural LM 22.35 -9.250 ORGRANIZER Online B 18.09 10.50 Table 3: Results of WAT20<strong>16</strong> English-Indonesian News Domain Task Team System BLEU HUMAN ORGANIZER Online A 28.<strong>11</strong> 49.25 SENSE Vanilla PBMT (clustercat) 25.97 -8.25 SENSE Vanilla PBMT (mkcls) 25.62 -5.00 ORGANIZER Baseline PBMT 24.57 0 IITB Bilingual Neural LM 22.58 - ORGANIZER Online B 19.69 34.50 Table 4: Results of WAT20<strong>16</strong> Indonesian-English News Domain Task Table 3 and 4 presents the results for the Indonesian-English News Domain Task. From Table 3, we achieve the highest BLEU scores in the English-Indonesia direction with a difference of >1.0+ BLEU score with respect to the baseline PBMT provided by the organizers. However, our HUMAN scores show that the quality of our system output is only marginally better than the baseline. Comparatively, the online system A has similar BLEU scores to the organizer’s baseline but achieved stellar HUMAN scores of +35.75. Table 4 shows the results for the English-Indonesian task, the online system A and B achieved the best HUMAN scores. In both directions, we see the same automatic vs manual evaluation disparity from System B’s low BLEU and high HUMAN scores and from our system’s high BLEU and low/marginal HUMAN scores. 4 Conclusion We motivate and describe the steps to build a fast and light phrase-based machine translation model that achieved comparable results to the WAT20<strong>16</strong> baseline. We hope that our baseline system helps new MT practitioners that are not familiar with the Moses ecology 13 to build PBMT models. The full training script is available on https://github.com/alvations/vanilla-moses/blob/ master/train-vanilla-model.sh. Acknowledgements The research leading to these results has received funding from the People Programme (Marie Curie Actions) of the European Union’s Seventh Framework Programme FP7/2007-2013/ under REA grant agreement no. 317471. References Yaser Al-Onaizan and Kishore Papineni. 2006. Distortion models for statistical machine translation. In Proceedings of the 21st International Conference on Computational Linguistics and the 44th annual meeting of the Association for Computational Linguistics, pages 529–536. Luisa Bentivogli, Arianna Bisazza, Mauro Cettolo, and Marcello Federico. 20<strong>16</strong>. Neural versus Phrase-Based Machine Translation Quality: a Case Study. ArXiv e-prints, August. Alexandra Birch, Miles Osborne, and Phil Blunsom. 2010. Metrics for mt evaluation: evaluating reordering. Machine Translation, 24(1):15–26. 13 Our Vanilla PBMT system is complimentary to the steps described in http://www.statmt.org/moses/?n=Moses.Tutorial 190
Peter F Brown, John Cocke, Stephen A Della Pietra, Vincent J Della Pietra, Fredrick Jelinek, John D Lafferty, Robert L Mercer, and Paul S Roossin. 1990. A statistical approach to machine translation. Computational linguistics, <strong>16</strong>(2):79–85. Peter F Brown, Vincent J Della Pietra, Stephen A Della Pietra, and Robert L Mercer. 1993. The mathematics of statistical machine translation: Parameter estimation. Computational linguistics, 19(2):263–3<strong>11</strong>. Daniel Cer, Michel Galley, Daniel Jurafsky, and Christopher D Manning. 2010. Phrasal: a toolkit for statistical machine translation with facilities for extraction and incorporation of arbitrary model features. In Proceedings of the NAACL HLT 2010 Demonstration Session, pages 9–12. Stanley Chen and Joshua T. Goodman. 1998. An empirical study of smoothing techniques for language modeling. Technical Report 10-98, Harvard University. David Chiang. 2005. A hierarchical phrase-based model for statistical machine translation. In Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics, pages 263–270. Association for Computational Linguistics. Josep Crego, Jungi Kim, Guillaume Klein, Anabel Rebollo, Kathy Yang, Jean Senellart, Egor Akhanov, Patrice Brunelle, Aurelien Coquard, Yongchao Deng, Satoshi Enoue, Chiyo Geiss, Joshua Johanson, Ardas Khalsa, Raoum Khiari, Byeongil Ko, Catherine Kobus, Jean Lorieux, Leidiana Martins, Dang-Chuan Nguyen, Alexandra Priori, Thomas Riccardi, Natalia Segal, Christophe Servan, Cyril Tiquet, Bo Wang, Jin Yang, Dakun Zhang, Jing Zhou, and Peter Zoldan. 20<strong>16</strong>. SYSTRAN’s Pure Neural Machine Translation Systems. ArXiv e-prints, October. Jon Dehdari, Liling Tan, and Josef van Genabith. 20<strong>16</strong>a. Bira: Improved predictive exchange word clustering. In Proceedings of the 20<strong>16</strong> Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages <strong>11</strong>69–<strong>11</strong>74, San Diego, California, June. Association for Computational Linguistics. Jon Dehdari, Liling Tan, and Josef van Genabith. 20<strong>16</strong>b. Scaling up word clustering. In Proceedings of the 20<strong>16</strong> Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations, pages 42–46, San Diego, California, June. Association for Computational Linguistics. Chris Dyer, Adam Lopez, Juri Ganitkevitch, Johnathan Weese, Ferhan Ture, Phil Blunsom, Hendra Setiawan, Vladimir Eidelman, and Philip Resnik. 2010. cdec: A decoder, alignment, and learning framework for finite-state and context-free translation models. In Proceedings of the Association for Computational Linguistics (ACL). Michel Galley and Christopher D Manning. 2008. A simple and effective hierarchical phrase reordering model. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, pages 848–856. Qin Gao and Stephan Vogel. 2008. Parallel implementations of word alignment tool. In Software Engineering, Testing, and Quality Assurance for Natural Language Processing, pages 49–57. Kenneth Heafield, Ivan Pouzyrevsky, Jonathan H. Clark, and Philipp Koehn. 2013. Scalable modified Kneser-Ney language model estimation. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 690–696, Sofia, Bulgaria. Kenneth Heafield. 20<strong>11</strong>. KenLM: Faster and smaller language model queries. In Proceedings of the EMNLP 20<strong>11</strong> Sixth Workshop on Statistical Machine Translation, pages 187–197, Edinburgh, Scotland, United Kingdom. Hieu Hoang and Adam Lopez. 2009. A unified framework for phrase-based, hierarchical, and syntax-based statistical machine translation. In In Proceedings of the International Workshop on Spoken Language Translation (IWSLT, pages 152–159. Hieu Hoang. 20<strong>11</strong>. Improving statistical machine translation with linguistic information. The University of Edinburgh. Marcin Junczys-Dowmunt. 2012. Phrasal rank-encoding: Exploiting phrase redundancy and translational relations for phrase table compression. The Prague Bulletin of Mathematical Linguistics, 98:63–74. Reinhard Kneser and Hermann Ney. 1995. Improved backing-off for m-gram language modeling. In Acoustics, Speech, and Signal Processing, 1995. ICASSP-95., 1995 International Conference on, volume 1, pages 181–184. IEEE. Kevin Knight. 1999. Decoding complexity in word-replacement translation models. Computational Linguistics, 25(4):607– 615. Philipp Koehn, Franz Josef Och, and Daniel Marcu. 2003. Statistical phrase-based translation. In Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology- Volume 1, pages 48–54. Philipp Koehn, Hieu Hoang, Alexandra Birch, Chris Callison-Burch, Marcello Federico, Nicola Bertoldi, Brooke Cowan, Wade Shen, Christine Moran, Richard Zens, Chris Dyer, Ondřej Bojar, Alexandra Constantin, and Evan Herbst. 2007. Moses: Open source toolkit for statistical machine translation. In Proceedings of the 45th Annual Meeting of the ACL on Interactive Poster and Demonstration Sessions, pages 177–180. Philipp Koehn, Barry Haddow, Philip Williams, and Hieu Hoang. 2010. More linguistic annotation for statistical machine translation. In Proceedings of the Joint Fifth Workshop on Statistical Machine Translation and MetricsMATR, WMT ’10, pages <strong>11</strong>5–120, Stroudsburg, PA, USA. Association for Computational Linguistics. 191
- Page 1 and 2:
WAT 2016 The 3rd Workshop on Asian
- Page 3:
Preface Many Asian countries are ra
- Page 6 and 7:
Technical Collaborators Luis Fernan
- Page 9 and 10:
Table of Contents Overview of the 3
- Page 11 and 12:
Conference Program December 12, 201
- Page 13 and 14:
December 12, 2016 (continued) 12:00
- Page 15 and 16:
Overview of the 3rd Workshop on Asi
- Page 17 and 18:
LangPair Train Dev DevTest Test JPC
- Page 19 and 20:
ASPEC JPC IITB BPPT pivot System ID
- Page 21 and 22:
3.6 Tree-to-String Syntax-based SMT
- Page 23 and 24:
• Use of other resources in addit
- Page 25 and 26:
ASPEC JPC BPPT IITBC pivot Team ID
- Page 27 and 28:
ut the adequacy is worse. As for AS
- Page 29 and 30:
Figure 3: Official evaluation resul
- Page 31 and 32:
Figure 5: Official evaluation resul
- Page 33 and 34:
Figure 7: Official evaluation resul
- Page 35 and 36:
Figure 9: Official evaluation resul
- Page 37 and 38:
Figure 11: Official evaluation resu
- Page 39 and 40:
Figure 13: Official evaluation resu
- Page 41 and 42:
Annotator A Annotator B all weighte
- Page 43 and 44:
Kyoto-U 2 bjtu nlp UT-KAY 1 UT-KAY
- Page 45 and 46:
Online B IITP-MT EHR Online A ≫
- Page 47 and 48:
SYSTEM ID ID METHOD OTHER RESOURCES
- Page 49 and 50:
SYSTEM ID ID METHOD OTHER BLEU RIBE
- Page 51 and 52:
SYSTEM ID ID METHOD OTHER RESOURCES
- Page 53 and 54:
SYSTEM ID ID METHOD OTHER BLEU RIBE
- Page 55 and 56:
SYSTEM ID ID METHOD OTHER RESOURCES
- Page 57 and 58:
SYSTEM ID ID METHOD OTHER BLEU RIBE
- Page 59 and 60:
Hyoung-Gyu Lee, JaeSong Lee, Jun-Se
- Page 61 and 62:
Translation of Patent Sentences wit
- Page 63 and 64:
Chinese sentences contain fewer tha
- Page 65 and 66:
Figure 3: NMT decoding with technic
- Page 67 and 68:
Table 1: Automatic evaluation resul
- Page 69 and 70:
Figure 6: Example of correct transl
- Page 71 and 72:
K. Papineni, S. Roukos, T. Ward, an
- Page 73 and 74:
Table 1: Examples of title, ingredi
- Page 75 and 76:
text. In this section, we explain t
- Page 77 and 78:
Table 3: Automatic evaluation BLEU/
- Page 79 and 80:
Table 5: Number of fluency errors i
- Page 81 and 82:
Kenneth Heafield. 2011. Kenlm: Fast
- Page 83 and 84:
under-studied. MorphInd, a morphana
- Page 85 and 86:
dimensions of 150 units in second h
- Page 87 and 88:
distribution as received in JPO ade
- Page 89 and 90:
Domain Adaptation and Attention-Bas
- Page 91 and 92:
Once s M , which represents the ent
- Page 93 and 94:
3.4.2 Ensemble of Attention Scores
- Page 95 and 96:
Type Count Ratio (A) Correct 76 30.
- Page 97 and 98:
Minh-Thang Luong, Hieu Pham, and Ch
- Page 99 and 100:
Pair 1 Japanese [[ A ][ B ][ C ]
- Page 101 and 102:
ID n-grams len freq m1 prevent, | 1
- Page 103 and 104:
prediction accuracy with respect to
- Page 105 and 106:
Reference: [ A To provide] [ B a to
- Page 107 and 108:
Philipp Koehn. 2004. Statistical si
- Page 109 and 110:
Therefore, we propose to use phrase
- Page 111 and 112:
Figure 2: An NRM considering phrase
- Page 113 and 114:
Mono Swap D right D left Acc. The r
- Page 115 and 116:
Method ja-en en-ja BLEU RIBES WER B
- Page 117 and 118:
Peng Li, Yang Liu, and Maosong Sun.
- Page 119 and 120:
Figure 1: The framework of NMT. Whe
- Page 121 and 122:
For long sentence, we discarded all
- Page 123 and 124:
As shown in the above tables and fi
- Page 125 and 126:
Translation systems and experimenta
- Page 127 and 128:
The number of TM training sentence
- Page 129 and 130:
where, f, p and e means a source, p
- Page 131 and 132:
former system can translate more th
- Page 133 and 134:
Lexicons and Minimum Risk Training
- Page 135 and 136:
2.2 Parameter Optimization If we de
- Page 137 and 138:
ML (λ=0.0) ML (λ=0.8) MR (λ=0.0)
- Page 139 and 140:
Graham Neubig. 2013. Travatar: A fo
- Page 141 and 142:
Feature Space Common (h ) Domain 1
- Page 143 and 144:
Preprocessing Training Translation
- Page 145 and 146:
JPC ASPEC LM Method Ja-En En-Ja Ja-
- Page 147 and 148:
Translation Using JAPIO Patent Corp
- Page 149 and 150:
4 Results Table 1 shows official ev
- Page 151 and 152:
Table 3: Examples of translation er
- Page 153 and 154: An Efficient and Effective Online S
- Page 155 and 156: #$ #%$ #$ !""
- Page 157 and 158: This formula requires a context of
- Page 159 and 160: Sentence Segmenter Parameters Dev.
- Page 161 and 162: a meaningful baseline for related r
- Page 163 and 164: Similar Southeast Asian Languages:
- Page 165 and 166: τ around 0.71, and the Malay-Indon
- Page 167 and 168: -0.9 -0.8 -0.7 -0.6 -0.5 -0.4 -0.3
- Page 169 and 170: 1.800 1.600 1.400 1.200 1.000 0.800
- Page 171 and 172: Integrating empty category detectio
- Page 173 and 174: 3 Preordering with empty categories
- Page 175 and 176: We performed the tests under two co
- Page 177 and 178: the decoded sentence and the refere
- Page 179 and 180: Kenneth Heafield. 2011. Kenlm: Fast
- Page 181 and 182: Figure 1: Overview of KyotoEBMT. Th
- Page 183 and 184: proportionally slower to compute (a
- Page 185 and 186: 3.6 Ensembling Ensembling has previ
- Page 187 and 188: when Chinese is also the language m
- Page 189 and 190: Character-based Decoding in Tree-to
- Page 191 and 192: where W s ∈ R d×d is a matrix an
- Page 193 and 194: Model BLEU (BP) RIBES Character-bas
- Page 195 and 196: The word-based NMT models cannot us
- Page 197 and 198: Razvan Pascanu, Tomas Mikolov, and
- Page 199 and 200: governs the grammaticality of the t
- Page 201 and 202: 2.1 Quantization and Binarization o
- Page 203: 3 Results Team Other Resources Syst
- Page 207 and 208: Yonghui Wu, Mike Schuster, Zhifeng
- Page 209 and 210: Language Sentence Chinese 该 / 钽
- Page 211 and 212: Chinese or Japanese sentences Chine
- Page 213 and 214: 4 Experiments and Results 4.1 Chine
- Page 215 and 216: 6 Conclusion and Future Work In thi
- Page 217 and 218: Controlling the Voice of a Sentence
- Page 219 and 220: Figure 2: Flow of the voice predict
- Page 221 and 222: ecause the number of passive senten
- Page 223 and 224: controlling the sentence length wit
- Page 225 and 226: Chinese-to-Japanese Patent Machine
- Page 227 and 228: using the reordering oracles over t
- Page 229 and 230: Conference on Natural Language Proc
- Page 231 and 232: Figure 1: Hierarchical approach wit
- Page 233 and 234: newswire test and development set o
- Page 235 and 236: Source: the rain and cold wind on W
- Page 237 and 238: Residual Stacking of RNNs for Neura
- Page 239 and 240: 2.2 Generalized Minimum Bayes Risk
- Page 241 and 242: 5.0 4.5 4.0 Baseline model Enlarged
- Page 243: Felix Hill, Kyunghyun Cho, Sebastie