

A new grammatical formalism to solve ellipsis: - Elhuyar Fundazioa
A new grammatical formalism to solve ellipsis: - Elhuyar Fundazioa
A new grammatical formalism to solve ellipsis: - Elhuyar Fundazioa

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
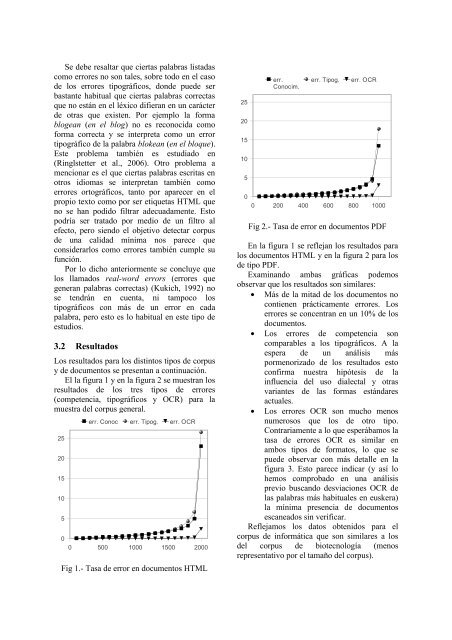
Se debe resaltar que ciertas palabras listadascomo errores no son tales, sobre <strong>to</strong>do en el casode los errores tipográficos, donde puede serbastante habitual que ciertas palabras correctasque no están en el léxico difieran en un carácterde otras que existen. Por ejemplo la formablogean (en el blog) no es reconocida comoforma correcta y se interpreta como un errortipográfico de la palabra blokean (en el bloque).Este problema también es estudiado en(Ringlstetter et al., 2006). Otro problema amencionar es el que ciertas palabras escritas enotros idiomas se interpretan también comoerrores or<strong>to</strong>gráficos, tan<strong>to</strong> por aparecer en elpropio tex<strong>to</strong> como por ser etiquetas HTML queno se han podido filtrar adecuadamente. Es<strong>to</strong>podría ser tratado por medio de un filtro alefec<strong>to</strong>, pero siendo el objetivo detectar corpusde una calidad mínima nos parece queconsiderarlos como errores también cumple sufunción.Por lo dicho anteriormente se concluye quelos llamados real-word errors (errores quegeneran palabras correctas) (Kukich, 1992) nose tendrán en cuenta, ni tampoco lostipográficos con más de un error en cadapalabra, pero es<strong>to</strong> es lo habitual en este tipo deestudios.3.2 ResultadosLos resultados para los distin<strong>to</strong>s tipos de corpusy de documen<strong>to</strong>s se presentan a continuación.El la figura 1 y en la figura 2 se muestran losresultados de los tres tipos de errores(competencia, tipográficos y OCR) para lamuestra del corpus general.2520151050err. Conoc err. Tipog. err. OCR0 500 1000 1500 2000Fig 1.- Tasa de error en documen<strong>to</strong>s HTML2520151050err.Conocim.err. Tipog.err. OCR0 200 400 600 800 1000Fig 2.- Tasa de error en documen<strong>to</strong>s PDFEn la figura 1 se reflejan los resultados paralos documen<strong>to</strong>s HTML y en la figura 2 para losde tipo PDF.Examinando ambas gráficas podemosobservar que los resultados son similares:• Más de la mitad de los documen<strong>to</strong>s nocontienen prácticamente errores. Loserrores se concentran en un 10% de losdocumen<strong>to</strong>s.• Los errores de competencia soncomparables a los tipográficos. A laespera de un análisis máspormenorizado de los resultados es<strong>to</strong>confirma nuestra hipótesis de lainfluencia del uso dialectal y otrasvariantes de las formas estándaresactuales.• Los errores OCR son mucho menosnumerosos que los de otro tipo.Contrariamente a lo que esperábamos latasa de errores OCR es similar enambos tipos de forma<strong>to</strong>s, lo que sepuede observar con más detalle en lafigura 3. Es<strong>to</strong> parece indicar (y así lohemos comprobado en una análisisprevio buscando desviaciones OCR delas palabras más habituales en euskera)la mínima presencia de documen<strong>to</strong>sescaneados sin verificar.Reflejamos los da<strong>to</strong>s obtenidos para elcorpus de informática que son similares a losdel corpus de biotecnología (menosrepresentativo por el tamaño del corpus).













