

A new grammatical formalism to solve ellipsis: - Elhuyar Fundazioa
A new grammatical formalism to solve ellipsis: - Elhuyar Fundazioa
A new grammatical formalism to solve ellipsis: - Elhuyar Fundazioa

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
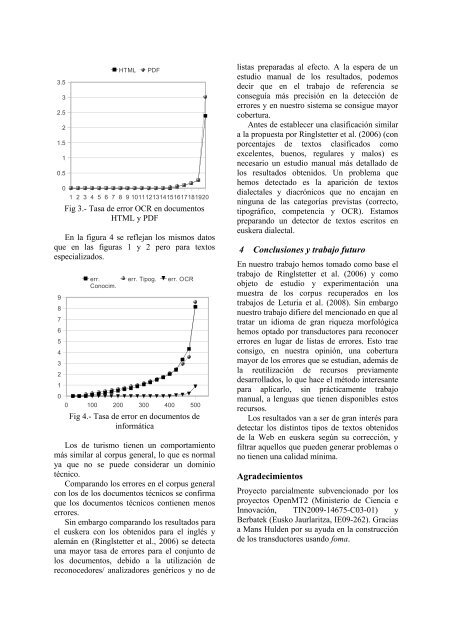
3.52.51.50.5Fig 3.- Tasa de error OCR en documen<strong>to</strong>sHTML y PDFEn la figura 4 se reflejan los mismos da<strong>to</strong>sque en las figuras 1 y 2 pero para tex<strong>to</strong>sespecializados.98765432103210HTMLPDF1 2 3 4 5 6 7 8 9 1011121314151617181920err.Conocim.err. Tipog.err. OCR0 100 200 300 400 500Fig 4.- Tasa de error en documen<strong>to</strong>s deinformáticaLos de turismo tienen un comportamien<strong>to</strong>más similar al corpus general, lo que es normalya que no se puede considerar un dominiotécnico.Comparando los errores en el corpus generalcon los de los documen<strong>to</strong>s técnicos se confirmaque los documen<strong>to</strong>s técnicos contienen menoserrores.Sin embargo comparando los resultados parael euskera con los obtenidos para el inglés yalemán en (Ringlstetter et al., 2006) se detectauna mayor tasa de errores para el conjun<strong>to</strong> delos documen<strong>to</strong>s, debido a la utilización dereconocedores/ analizadores genéricos y no delistas preparadas al efec<strong>to</strong>. A la espera de unestudio manual de los resultados, podemosdecir que en el trabajo de referencia seconseguía más precisión en la detección deerrores y en nuestro sistema se consigue mayorcobertura.Antes de establecer una clasificación similara la propuesta por Ringlstetter et al. (2006) (conporcentajes de tex<strong>to</strong>s clasificados comoexcelentes, buenos, regulares y malos) esnecesario un estudio manual más detallado delos resultados obtenidos. Un problema quehemos detectado es la aparición de tex<strong>to</strong>sdialectales y diacrónicos que no encajan enninguna de las categorías previstas (correc<strong>to</strong>,tipográfico, competencia y OCR). Estamospreparando un detec<strong>to</strong>r de tex<strong>to</strong>s escri<strong>to</strong>s eneuskera dialectal.4 Conclusiones y trabajo futuroEn nuestro trabajo hemos <strong>to</strong>mado como base eltrabajo de Ringlstetter et al. (2006) y comoobje<strong>to</strong> de estudio y experimentación unamuestra de los corpus recuperados en lostrabajos de Leturia et al. (2008). Sin embargonuestro trabajo difiere del mencionado en que altratar un idioma de gran riqueza morfológicahemos optado por transduc<strong>to</strong>res para reconocererrores en lugar de listas de errores. Es<strong>to</strong> traeconsigo, en nuestra opinión, una coberturamayor de los errores que se estudian, además dela reutilización de recursos previamentedesarrollados, lo que hace el mé<strong>to</strong>do interesantepara aplicarlo, sin prácticamente trabajomanual, a lenguas que tienen disponibles es<strong>to</strong>srecursos.Los resultados van a ser de gran interés paradetectar los distin<strong>to</strong>s tipos de tex<strong>to</strong>s obtenidosde la Web en euskera según su corrección, yfiltrar aquellos que pueden generar problemas ono tienen una calidad mínima.Agradecimien<strong>to</strong>sProyec<strong>to</strong> parcialmente subvencionado por losproyec<strong>to</strong>s OpenMT2 (Ministerio de Ciencia eInnovación, TIN2009-14675-C03-01) yBerbatek (Eusko Jaurlaritza, IE09-262). Graciasa Mans Hulden por su ayuda en la construcciónde los transduc<strong>to</strong>res usando foma.













