

Analisi sintattica
Analisi sintattica
Analisi sintattica

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
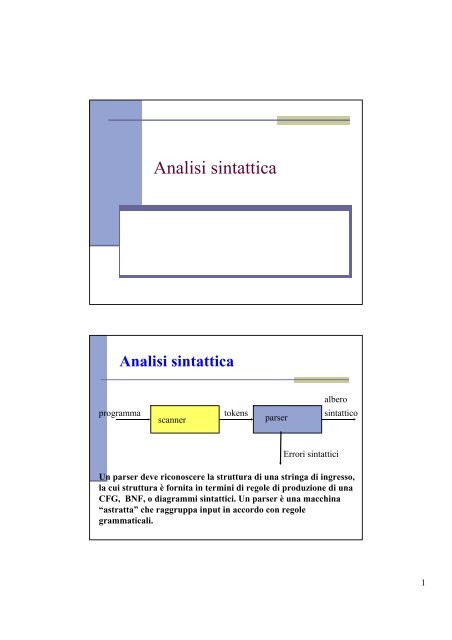
<strong>Analisi</strong> <strong>sintattica</strong><br />
<strong>Analisi</strong> <strong>sintattica</strong><br />
programma<br />
scanner<br />
tokens<br />
parser<br />
Errori sintattici<br />
albero<br />
sintattico<br />
Un parser deve riconoscere la struttura di una stringa di ingresso,<br />
la cui struttura è fornita in termini di regole di produzione di una<br />
CFG, BNF, o diagrammi sintattici. Un parser è una macchina<br />
“astratta” che raggruppa input in accordo con regole<br />
grammaticali.<br />
1
Sintassi<br />
La sintassi è costituita da un insieme di regole che<br />
definiscono le frasi formalmente corrette<br />
permettono di assegnare ad esse una struttura (albero<br />
sintattico) che ne indica la decomposizione nei costituenti<br />
immediati.<br />
Ad es. la struttura di una frase (ovvero di un programma) di<br />
un linguaggio di programmazione ha come costituenti le<br />
parti dichiarative e quelle esecutive. Le parti dichiarative<br />
definiscono i dati usati dal programma. Le parti esecutive si<br />
articolano nelle istruzioni, che possono essere di vari tipi:<br />
assegnamenti, istruzioni condizionali, frasi di lettura, ecc. I<br />
costituenti del livello più basso sono gli elementi lessicali<br />
già considerati, che dalla sintassi sono visti come atomi<br />
indecomponibili. Infatti la loro definizione spetta al livello<br />
lessicale.<br />
Grammatiche non contestuali:<br />
vantaggi<br />
La teoria formale dei linguaggi offre diversi modelli, ma<br />
nella quasi totalità dei casi il tipo di sintassi adottata è<br />
quello noto come sintassi libera o non-contestuale (contextfree)<br />
che corrisponde al tipo 2 della gerarchia di Chomsky.<br />
I metodi sintattici per il trattamento del linguaggio sono<br />
semplici<br />
efficienti<br />
la definizione del linguaggio attraverso le regole delle sintassi<br />
libere dal contesto è diretta ed intuitiva<br />
gli algoritmi deterministici di riconoscimento delle frasi sono<br />
veloci (hanno complessità lineare) e facili da realizzare<br />
partendo dalla sintassi.<br />
Tutti questi vantaggi hanno imposto le grammatiche libere<br />
dal contesto come l’unico metodo pratico per definire<br />
formalmente la struttura di un linguaggio.<br />
2
Grammatiche non contestuali:<br />
svantaggi<br />
Non tutte le regole di un linguaggio di programmazione possono essere<br />
espresse in termini nel modello noncontestuale. Ad esempio non puo<br />
espremere le seguenti regole:<br />
in un programma ogni identificatore di variabile deve comparire in<br />
una dichiarazione<br />
il tipo del parametro attuale di un sottoprogramma deve essere<br />
compatibile con quello del parametro formale corrispondente<br />
Un altro limite del modello sintattico libero tocca le esigenze di calcolo<br />
della traduzione. Se si guardano le traduzioni definibili con i soli metodi<br />
sintattici, esse sono<br />
decisamente povere<br />
inadeguate ai problemi reali (compilazione di un linguaggio<br />
programmativo nel linguaggio macchina)<br />
Da queste critiche sarebbe sbagliato concludere che i metodi sintattici<br />
sono inutili: al contrario essi sono indispensabili come supporto<br />
(concettuale e progettuale) su cui poggiare i più completi strumenti della<br />
semantica.<br />
Parser<br />
• Il parser lavora con stringhe di tokens<br />
Programa<br />
sorgente<br />
Scanne<br />
r<br />
token<br />
get next token<br />
Parse<br />
r<br />
Albero sintattico<br />
3
Grammatiche di tipo Context-Free<br />
Le strutture ricorsive presenti nei linguaggi di<br />
programmazione sono definite da una grammatica<br />
context-free.<br />
Una grammatica context-free (CFG) è definita come<br />
Un insieme finito di terminali V (sono i token prodotti<br />
dallo scanner)<br />
Un insieme di non terminali V.<br />
Un assioma o simbolo iniziale (uno dei non terminali.<br />
Un insieme di produzioni (dette anche “rewriting rules”<br />
con la seguente forma<br />
A → X1 ... Xm dove X1 to Xm possono essere terminali o non<br />
terminali.<br />
Se m =0 si ha A → ε che è una produzione valida<br />
Grammatiche di tipo Context-Free<br />
Le strutture ricorsive presenti nei linguaggi di<br />
programmazione sono definite da una grammatica<br />
context-free.<br />
Una grammatica context-free (CFG) è definita come<br />
Un insieme finito Esempio di terminali V (sono i token prodotti<br />
dallo scanner) T = { (, ), id , + , * , / , -}<br />
Un insieme di non terminali V = {E} V.<br />
E → E + E<br />
Un assioma o simbolo<br />
E →<br />
iniziale<br />
E – E<br />
(uno dei non terminali.<br />
Un insieme di produzioni E → E (dette * E anche “rewriting rules”<br />
con la seguente forma E → E / E<br />
E → -E<br />
A → X1 ... XmE → ( E )<br />
dove X1 to Xm possono E →essere id<br />
terminali o non<br />
terminali.<br />
Se m =0 si ha A → ε che è una produzione valida<br />
4
E ⇒ E+E<br />
Derivazioni<br />
E+E deriva da E<br />
Possiamo sostituire E con con E+E<br />
Perr poter fare questo deve esistere una produzione E→E+E nella<br />
grammatica.<br />
E ⇒ E+E ⇒ id+E ⇒ id+id<br />
Una sequenza di sostituzioni di non-terminali e chiamata una derivazione di<br />
id+id da E.<br />
In generale un passo di derivazione è<br />
αAβ ⇒αγβ se ∃ A→γ in G α ∈(V ∪ T)* e β ∈ (V ∪ T)*<br />
α 1 ⇒α 2 ⇒ ... ⇒ α n<br />
⇒ one step<br />
⇒* zero o più steps<br />
⇒+ 1 o più steps<br />
V = { Prog, Seq, Istr, Expr}<br />
T = {; , id , + }<br />
Assioma = Prog<br />
Prog → { Seq }<br />
Seq →Seq ; Istr<br />
Seq → ε<br />
Istr →Seq<br />
Istr →id = Expr<br />
Expr →id<br />
Expr →Expr + id<br />
(α n deriva da α 1 o α 1 è derivato da α n )<br />
V = { Prog, Seq, Istr, Expr}<br />
T = {; , id , + }<br />
Assioma = Prog<br />
Prog → { Seq }<br />
Seq →Seq ; Istr | ε<br />
Istr →Seq | id = Expr<br />
Expr →id | Expr + id<br />
5
Per esempio partendo da Prog possiamo generate,<br />
aplicando ripetutamente le produzione le seguenti<br />
stringhe:<br />
Prog<br />
{ Seq }<br />
{ Seq ;Istr}<br />
{Istr;Istr}<br />
{ id = Expr ;Istr}<br />
{ id = id ;Istr}<br />
{ id = id ; id = Expr }<br />
{ id = id ; id = Expr + id}<br />
{ id = id ; id = id + id}<br />
Le produzioni devono avere le seguenti<br />
proprietà:<br />
no produzioni inutili o ridondanti (i.e., A → A),<br />
no non-terminali senza produzioni<br />
(e.g., A → Ba dove B non è definito),<br />
no cicli infiniti (e.g., A → Aa senza altre<br />
produzioni per A),<br />
no ambiguita’: una grammatica con più alberi<br />
sintattici per la stessa espressione è ambigua<br />
descrivere correttamente il linguaggio.<br />
6
CFG - Terminologia<br />
L(G) è il linguaggio generato da G.<br />
Una frase di L(G) è una stringa di simboli terminali di G.<br />
Se S è l’assioma o start symbol di G allora<br />
+<br />
ω è una frase di L(G) iff S ⇒ ω dove ω ∈T*.<br />
• Se G è una grammatica context-free, L(G) è un<br />
linguaggio context-free.<br />
• Due grammatiche sono equivalenti se producono lo<br />
stesso linguaggio.<br />
• * S ⇒ α Se α contiene non-terminali, è chiamata forma di frase di G.<br />
Se α non contiene no-terminali è chiamata frase di G.<br />
Derivazioni Left-Most e Right-Most<br />
Left-Most Derivation<br />
E ⇒ -E ⇒ -(E) ⇒ -(E+E) ⇒ -(id+E) ⇒ -(id+id)<br />
Right-Most Derivation<br />
E ⇒ -E ⇒ -(E) ⇒ -(E+E) ⇒ -(E+id) ⇒ -(id+id)<br />
top-down parser cerca una left-most derivation del<br />
programma sorgente<br />
bottom-up parser cerca una right-most derivation del<br />
programma sorgente<br />
7
Parse Tree (Abstract Sintax Tree)<br />
I nodi non foglie dell’albero sintattico sono simboli non-terminal, le foglie simboli<br />
terminali.<br />
E ⇒ -E<br />
-<br />
-<br />
E<br />
E<br />
E<br />
E<br />
⇒ -(E) E<br />
⇒ -(E+E)<br />
- E<br />
( E )<br />
⇒ -(id+E) ⇒ -(id+id)<br />
( E )<br />
E +<br />
id<br />
E<br />
-<br />
E<br />
E<br />
( E )<br />
E +<br />
id<br />
E<br />
id<br />
-<br />
E<br />
( E )<br />
Un albero sintattico è una rappresentazione grafica di una derivazione.<br />
Per esempio partendo da Prog possiamo generate,<br />
aplicando ripetutamente le produzione le seguenti<br />
stringhe:<br />
Prog<br />
{ Seq }<br />
{ Seq ;Istr}<br />
Seq<br />
{Istr;Istr}<br />
{ id = Expr ;Istr}<br />
Seq Istr<br />
{ id = id ;Istr}<br />
{ id = id ; id = Expr }<br />
{ id = id ; id = Expr + id}<br />
{ id = id ; id = id + id}<br />
Istr<br />
E<br />
E<br />
+<br />
E<br />
8
Parser<br />
Esempio: Consideriamo l’analisi della frase<br />
1 + 2 * 3<br />
secondo la seguente grammatica<br />
::= + <br />
| * <br />
L’analisi <strong>sintattica</strong> può essere vista come un processo | numberper<br />
costruire gli alberi sintattici (parse tree).<br />
La sintassi di un programma è descritto da un agrammatica<br />
libera dal contesto (CFG). La notazione BNF (Backus-Naur<br />
Form) è una notazione per la descrzione di una CFG.<br />
Il parser verifica se un programma sorgente soddisfa le regole<br />
implicate da una grammatica context-free o no.<br />
Se le soddisfa, il parser crea l’albero sintattico (del programma<br />
Altrimenti genera un messaggio di errore.<br />
Una grammatica non contestuale<br />
Da una specifica rigorosa della sintassi dei linguaggi di<br />
programmazione<br />
Il progetto della grammatica e la fase iniziale del progetto del<br />
compilatore<br />
Esistono strumenti automatici per costruire automaticamente il<br />
compilatore dalla grammatica<br />
Ambiguita<br />
• Una grammatica è ambigua se esistono più alberi sintattici per la<br />
stessa frase.<br />
E ⇒ E+E ⇒ id+E ⇒ id+E*E<br />
⇒ id+id*E ⇒ id+id*id<br />
Esempio<br />
T = { (, ), id , + , * , / , -}<br />
E V ⇒= {E} E*E ⇒ E+E*E ⇒ id+E*E<br />
E<br />
⇒<br />
→<br />
id+id*E<br />
E + E<br />
⇒ id+id*id<br />
E → E – E<br />
E → E * E<br />
E → E / E<br />
E → -E<br />
E → ( E )<br />
E → id<br />
E +<br />
id<br />
E<br />
E<br />
* E<br />
E<br />
id<br />
id<br />
E<br />
E +<br />
id E<br />
E<br />
* E<br />
id id<br />
9
Esempio<br />
T = { Ambiguita<br />
(, ), id , + , * , / , -}<br />
V = {E}<br />
E → E + E<br />
E → E – E<br />
•E Una → E grammatica * E è ambigua se esistono più alberi sintattici per la<br />
stessa E → E frase. / E<br />
E<br />
E → -E<br />
E + E<br />
E E → ⇒( E E+E ) ⇒ id+E ⇒ id+E*E<br />
E → ⇒id id+id*E ⇒ id+id*id<br />
id E * E<br />
E ⇒ E*E ⇒ E+E*E ⇒ id+E*E<br />
⇒ id+id*E ⇒ id+id*id<br />
E +<br />
id<br />
E<br />
E<br />
* E<br />
E<br />
id<br />
id<br />
id id<br />
Per poter costruire un parser la grammatica<br />
non deve essere ambigua<br />
Grammatica non ambigua ∃ un unico<br />
albero sintattico per ogni frase del linguaggio<br />
Le ambiguità nella grammatica devono<br />
essere eliminate durante il progetto del<br />
compilatore<br />
10
Ambiguità<br />
istr → if expr then istr |<br />
if expr then istr else istr | otheristrs<br />
istr<br />
if E 1 then if E 2 then S 1 else S 2<br />
if expr then istr else istr<br />
E 1 if expr then istr S 2<br />
1<br />
E 2<br />
Ambiguità<br />
S 1<br />
istr<br />
if expr then istr<br />
E 1 if expr then istr else istr<br />
E 2 S 1 S<br />
• Noi preferiamo il secondo albero sintattico (else corrisponde al<br />
if più vicino).<br />
• Dobbiamo eliminare l’ambiguità con tale obiettivo<br />
• La grammatica non-ambigua sarà:<br />
istr → matchedistr | unmatchedistr<br />
matchedistr → if expr then matchedistr else matchedistr<br />
| otheristrs<br />
unmatchedistr → if expr then istr |<br />
if expr then matchedistr else unmatchedistr<br />
2<br />
11
Ambiguita – Precedenza degli<br />
operatori<br />
Grammatiche ambigue possono essere rese non-ambigue<br />
in accordo alle precedenze degli operatori e alle regole di<br />
associativià degli operatori.<br />
E → E+E | E*E | E^E | id | (E)<br />
E → E+T | T<br />
T → T*F | F<br />
F → G^F | G<br />
G → id | (E)<br />
precedenze: ^ (right to left)<br />
* (left to right)<br />
+ (left to right)<br />
Ricorsione sinistra (Left Recursion)<br />
Una grammatica è “left recursive” se ha un non<br />
terminale A tale che<br />
+<br />
A ⇒ Aα per qualche stringa α<br />
Le tecniche di parser Top-down non possono gestire<br />
grammatiche left-recursive.<br />
Una grammatica left-recursive deve esssere<br />
convertita in una non left-recursive.<br />
La ricorsione sinistra può comparire in un singolo<br />
passo della derivazione (immediate left-recursion), o<br />
può comparire in più che un passo.<br />
12
Immediate Left-Recursion<br />
A → A α | β dove β ≠ Aγ e γ∈(V ∪ T)*<br />
⇓<br />
A →βA ’<br />
A ’ →αA ’ | ε grammatica equivalente<br />
In generale<br />
A → A α1 | ... | A αm | β1 | ... | βn dove βi ≠ Aγ e γ∈(V ∪ T)*<br />
⇓<br />
A →β 1 A ’ | ... | β n A ’<br />
A ’ →α 1 A ’ | ... | α m A ’ | ε grammatica equivalente<br />
Esempio<br />
E → E+T<br />
E → T<br />
T → T*F<br />
T → F<br />
eliminate immediate left recursion<br />
F → id<br />
F →(E)<br />
E → T E ’<br />
E ’ → +T E ’<br />
E’ → ε<br />
T → F T ’<br />
T ’ → *F T ’<br />
T’ → ε<br />
F → id<br />
F → (E)<br />
13
Left-Recursion – Problema!!<br />
• Una grammatica che non e direttamente left-recursive, ma lo è in<br />
modo indirettp.<br />
• Anche in questo caso va eliminata la ricorsione sinistra<br />
Esempio<br />
S → Aa | b<br />
A → Sc | d<br />
S ⇒ Aa ⇒ Sca<br />
A ⇒ Sc ⇒ Aac<br />
Algoritmo per l’eliminazione della<br />
ricorsione sinistra<br />
- Ordinare I non-terminali A1 ... An -fori from 1 to n do {<br />
- for j from 1 to i-1 do {<br />
sostituire ogni produzione<br />
Ai → Aj γ<br />
con<br />
Ai →α1 γ | ... | αk γ<br />
dove Aj →α1 | ... | αk }<br />
- eliminare la ricorsione sinistra nelle produzioni di Ai }<br />
14
Esempio<br />
S → Aa | b<br />
A → Ac | Sd | f<br />
- Ordinare I non-terminali: S, A<br />
per S:<br />
- non c’e una ricorsione sinistra diretta.<br />
for A:<br />
- sostituiamo A → Sd con A → Aad | bd<br />
Cosi avremoA → Ac | Aad | bd | f<br />
- Eliminiamo la ricorsione sinistra in A<br />
A → bdA ’ | fA ’<br />
A ’ → cA ’ | adA ’ | ε<br />
Avremo la grammatica non ricorsiva equivalente:<br />
S → Aa | b<br />
A → bdA ’ | fA ’<br />
A ’ → cA ’ | adA ’ | ε<br />
Esempio<br />
S → Aa | b<br />
A → Ac | Sd | f<br />
- Ordinare I non-terminali : A, S<br />
per A:<br />
Eliminamo la ricorsione sinistra in A<br />
A → SdA ’ | fA ’<br />
A ’ → cA ’ | ε<br />
per S:<br />
- Sostituiamo S → Aa with S → SdA ’ a | fA ’ a<br />
Così avremo S → SdA ’ a | fA ’ a | b<br />
- Eliminamo la ricorsione sinistra in S<br />
S → fA’aS’ | bS ’<br />
S ’ → dA ’ aS’ | ε<br />
Avremo la grammatica non ricorsiva equivalente:<br />
S → fA’aS’ | bS ’<br />
S ’ → dA ’ aS’ | ε<br />
A → SdA ’ | fA ’<br />
A ’ → cA ’ | ε<br />
15
Left-Factoring (fattorizzazione<br />
sinistra)<br />
Un parser top down deterministico richiede<br />
una grammatica left-factored.<br />
grammatica grammatica equivalente<br />
istr → if (expr ) istr else istr |<br />
if (expr) istr<br />
Left-Factoring (cont.)<br />
In generale,<br />
A → αβ1 | αβ2 dove α∈(V∪T)* - {ε}, β1∈ (V∪T)* - {ε}, β2∈ (V∪T)* -<br />
{ε}<br />
e β1≠. Noi possiamo riscrivere la grammatica come segue<br />
A → αA ’<br />
A’ →β 1 | β 2<br />
16
Algoritmo<br />
Per ogni non-terminale A con due o più<br />
alternative (produzioni) con una parte non<br />
vuota comune<br />
A → αβ1 | ... | αβn | γ1 | ... | γm diventa<br />
A → αA ’ | γ 1 | ... | γ m<br />
A ’ →β 1 | ... | β n<br />
Esempio<br />
A → abB | aB | cdg | cdeB | cdfB<br />
⇓<br />
A → aA ’ | cdg | cdeB | cdfB<br />
A ’ → bB | B<br />
⇓<br />
A → aA ’ | cdA ’’<br />
A ’ → bB | B<br />
A ’’ → g | eB | fB<br />
17
Esempio<br />
A → ad | a | ab | abc | b<br />
⇓<br />
A → aA’ | b<br />
A’ → d | ε | b | bc<br />
⇓<br />
A → aA’ | b<br />
A’ → d | ε | bA’’<br />
A’’ →ε | c<br />
istr → if (expr ) istr else istr |<br />
if (expr) istr<br />
istr → if (expr ) istr X<br />
X → else istr<br />
X →ε 18
Le frasi possono essere analizzate da<br />
sinistra a destra (L parser), possono<br />
essere costruite con derivazioni left-most<br />
(LL(k) parser) o right-most (LR(k) parser)<br />
utilizzando k symboli di look-ahead!<br />
LL è più conosciuta come top-down parser.<br />
LR è più conosciuta come bottom-up<br />
parser.<br />
Per ragioni pratiche k deve essere piccolo.<br />
Per un compilatore è auspicabile l’uso di<br />
grammatiche che possono essere analizzate in<br />
modo deterministico con al più k symboli di lookahead.<br />
L’assenza di ambiguità è condizione<br />
necessaria per un analisi determinstica<br />
Consideriamo un bottom up parse per abbcde<br />
generato dalla seguente grammatica con assioma<br />
S, eseguento un approccio “left-most matches<br />
First”.<br />
S → aAcBe<br />
A → Ab|b<br />
B → d<br />
19
abbcde applicando B → d<br />
aAbcBe applicando A → b<br />
aAcBe applicando A → Ab<br />
S applicando S → aAcBe<br />
Parser<br />
Due differenti metodi di analisi <strong>sintattica</strong><br />
A 1<br />
A 2<br />
S 4<br />
B 3<br />
a b b c d e<br />
top-down: l’albero sintattico è creato dalla radice alle foglie<br />
bottom-up: l’albero sintattico è creato dalle foglie alla radice<br />
Il parser può lavorare in una varietà di modi ma esso<br />
tipicamente processa l’ input da sinistra a destra.<br />
Parser sia top-down che bottom-up possono essere<br />
implmentati in modo efficente solo per alcune sottoclassi di<br />
gramatiche context-free:<br />
LL per top-down<br />
LR per bottom-up<br />
Una “left-most (right-most) derivation” è una derivazione nella<br />
quale durante ogni passo viene sostituito solo il non-terminale<br />
più a sinistra (destra).<br />
20
Definzione di First(α)<br />
Data una grammatica non contestuale G(V,T,P,S) si definisce<br />
First(α) = {a in T | α⇒* aβ}<br />
Quindi First(α) è il seguente sottoinsieme di T:<br />
•se α = aβ con a ∈ T allora a ∈ First(α)<br />
•se α = Aβ con A ∈ T allora<br />
• se ∃ una produzione A → γallora First(γ) ⊆ First(α)<br />
• se ∃ una produzione A →εallora First(β) ⊆ First(α)<br />
First(α) è l’insieme di tutti i terminali con cui può iniziare una<br />
stringa derivata da α.<br />
Se α →*ε allora ε∈First(α).<br />
First(α) = {a ∈ T | α →* a β} ∪ if a → *ε then {ε} else ∅<br />
Esempio<br />
T = {a, b, c, d, e},<br />
V = {S, B, C}<br />
P = { S → aSe | B,<br />
B → bBe | C,<br />
C → cCe | d }<br />
S = S<br />
First(aSe) = {a}<br />
First(B) = First(bBe) ∪ First(C) = {b} ∪ First(cCe) ∪ First(d) =<br />
{b} ∪ {c} ∪ {d} = {b, c, d}<br />
First(bBe) = {b}<br />
First(C) = First(cCe) ∪ First(d) = {c} ∪ {d} = {c, d}<br />
First(cCe) = {c}<br />
21
Esempio<br />
T = {a, b, c, d, e}<br />
V = {A, B, C, D}<br />
P = { A → B | Ce | a<br />
B → bC,<br />
C → Dc<br />
D → d | ε}<br />
S = A<br />
First(B) = First(b) ={b}<br />
First(C e) = First (Dc) = First(d) ∪ First(ε) = {d} ∪{ε} = {d,<br />
ε }<br />
First(a) = {a}<br />
First(bC )= {b}<br />
Esempio<br />
T = {(, +, ), v, f}<br />
V = {E, Prefix, Tail}<br />
P = { E → Prefix(E) | v Tail<br />
Prefix → f | ε<br />
Tail → + E | ε }<br />
S = E<br />
First(Prefix(E) ) = {f} ∪{ε}<br />
First(v Tail) = {v}<br />
First(f) = {f}<br />
First(ε )= {ε}<br />
22
Esempio<br />
T = {a, (, ), +, ","}<br />
V = {E, T, L, P}<br />
P = { E → E + T | T<br />
T → a | (E) |<br />
a(L)<br />
E}<br />
S = E<br />
L → P | ε ,<br />
P → E | P ","<br />
First(E) = {a, (}<br />
First(T) = {a, (}<br />
First(L) = {ε , a, (}<br />
T = {a, b, c, d, e}<br />
V = {A, B, C, D}<br />
P = { A → B | C | Ce | a<br />
B → bC<br />
Definizione di Follow(A)<br />
C → Dc | D<br />
D → d | ε }<br />
S = A<br />
First(A) = {a, b, d, c, e, ε }<br />
First(B) = {b}<br />
First(C) = {d, c, ε }<br />
Data una grammatica non contestuale G(V,T,P,S) si definisce<br />
Follow(A) l’insieme dei terminali che seguono in una qualsiasi frase<br />
Esso è definito come segue:<br />
Follow(A) = {a ∈ T | S → +… Aa ….} ∪<br />
(if S ⇒* … A then {ε} else ∅}<br />
23
T = {a, b, c, d, e},<br />
V = {S, B, C}<br />
P = { S → aSe | B,<br />
B → bBe | C,<br />
C → cCe | d }<br />
S = S<br />
Follow(S) = {e, $}<br />
Follow(B) = {e, $}<br />
Follow(C) = {e, $}<br />
T = {(, +, ), v, f}<br />
V = {E, Prefix, Tail}<br />
P = { E → Prefix(E) | v<br />
Tail<br />
Prefix → f | ε<br />
Tail → + E | ε }<br />
S = E<br />
Follow(Prefix ) = { ( }<br />
Follow(E) = {$}<br />
Follow(Tail) = { $ }<br />
T = {a, (, ), +, ","}<br />
V = {E, T, L, P}<br />
P = { E → E + T | T<br />
T → a | (E) | a(L)<br />
L → P | ε ,<br />
P → E | P "," E}<br />
S = E<br />
Follow(E) = {+, ) , “,“ , $}<br />
Follow(T) = {+, ) , “,“ , $}<br />
Follow(L) = { ) }<br />
Follow(P) = {) , “,”}<br />
T = {a, b, c, d, e}<br />
V = {A, B, C, D}<br />
P = { A → B | Ce | a<br />
B → bC,<br />
C → Dc<br />
D → d | ε}<br />
S = A<br />
Follow(A) = {$}<br />
Follow(B) = {$}<br />
Follow(C) = {$, e}<br />
Follow(D) = {c}<br />
24
T = {a, b, c, d, e}<br />
V = {A, B, C, D}<br />
P = { A → B | C | Ce | a<br />
B → bC<br />
C → Dc | D<br />
D → d | ε }<br />
S = A<br />
Follow(A) = {$}<br />
Follow(B) = Follow(A) = {$}<br />
Follow(C) = Follow(A) ∪ Follow(B) ∪ {e} = {e , $}<br />
Follow(D) = {c } ∪ Follow(C) = {c, e , $}<br />
25











