

INTRODUÇÃO À SUMARIZAÇÃO AUTOMÁTICA - ICMC - USP
INTRODUÇÃO À SUMARIZAÇÃO AUTOMÁTICA - ICMC - USP
INTRODUÇÃO À SUMARIZAÇÃO AUTOMÁTICA - ICMC - USP

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
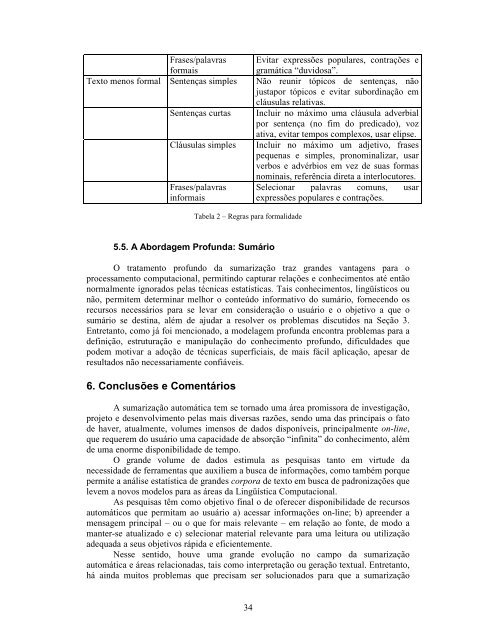
Frases/palavras Evitar expressões populares, contrações e<br />
formais<br />
gramática “duvidosa”.<br />
Texto menos formal Sentenças simples Não reunir tópicos de sentenças, não<br />
Sentenças curtas<br />
justapor tópicos e evitar subordinação em<br />
cláusulas relativas.<br />
Incluir no máximo uma cláusula adverbial<br />
por sentença (no fim do predicado), voz<br />
ativa, evitar tempos complexos, usar elipse.<br />
Cláusulas simples Incluir no máximo um adjetivo, frases<br />
pequenas e simples, pronominalizar, usar<br />
verbos e advérbios em vez de suas formas<br />
Frases/palavras<br />
informais<br />
Tabela 2 – Regras para formalidade<br />
5.5. A Abordagem Profunda: Sumário<br />
34<br />
nominais, referência direta a interlocutores.<br />
Selecionar palavras comuns, usar<br />
expressões populares e contrações.<br />
O tratamento profundo da sumarização traz grandes vantagens para o<br />
processamento computacional, permitindo capturar relações e conhecimentos até então<br />
normalmente ignorados pelas técnicas estatísticas. Tais conhecimentos, lingüísticos ou<br />
não, permitem determinar melhor o conteúdo informativo do sumário, fornecendo os<br />
recursos necessários para se levar em consideração o usuário e o objetivo a que o<br />
sumário se destina, além de ajudar a resolver os problemas discutidos na Seção 3.<br />
Entretanto, como já foi mencionado, a modelagem profunda encontra problemas para a<br />
definição, estruturação e manipulação do conhecimento profundo, dificuldades que<br />
podem motivar a adoção de técnicas superficiais, de mais fácil aplicação, apesar de<br />
resultados não necessariamente confiáveis.<br />
6. Conclusões e Comentários<br />
A sumarização automática tem se tornado uma área promissora de investigação,<br />
projeto e desenvolvimento pelas mais diversas razões, sendo uma das principais o fato<br />
de haver, atualmente, volumes imensos de dados disponíveis, principalmente on-line,<br />
que requerem do usuário uma capacidade de absorção “infinita” do conhecimento, além<br />
de uma enorme disponibilidade de tempo.<br />
O grande volume de dados estimula as pesquisas tanto em virtude da<br />
necessidade de ferramentas que auxiliem a busca de informações, como também porque<br />
permite a análise estatística de grandes corpora de texto em busca de padronizações que<br />
levem a novos modelos para as áreas da Lingüística Computacional.<br />
As pesquisas têm como objetivo final o de oferecer disponibilidade de recursos<br />
automáticos que permitam ao usuário a) acessar informações on-line; b) apreender a<br />
mensagem principal – ou o que for mais relevante – em relação ao fonte, de modo a<br />
manter-se atualizado e c) selecionar material relevante para uma leitura ou utilização<br />
adequada a seus objetivos rápida e eficientemente.<br />
Nesse sentido, houve uma grande evolução no campo da sumarização<br />
automática e áreas relacionadas, tais como interpretação ou geração textual. Entretanto,<br />
há ainda muitos problemas que precisam ser solucionados para que a sumarização













