

Appendix G - Clemson University
Appendix G - Clemson University
Appendix G - Clemson University

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
Clock<br />
cycles<br />
9<br />
8<br />
7<br />
6<br />
5<br />
4<br />
3<br />
2<br />
1<br />
0<br />
10<br />
G.3 Two Real-World Issues: Vector Length and Stride ■ G-21<br />
30 50 70 90 110 130 150 170 190<br />
Vector size<br />
Total time<br />
per element<br />
Total<br />
overhead<br />
per element<br />
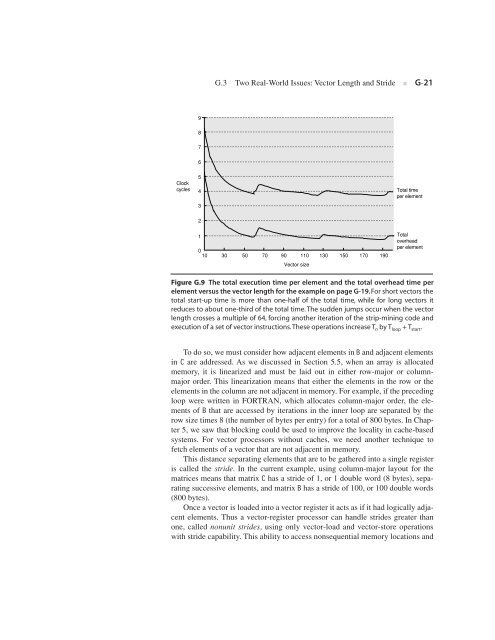
Figure G.9 The total execution time per element and the total overhead time per<br />
element versus the vector length for the example on page G-19. For short vectors the<br />
total start-up time is more than one-half of the total time, while for long vectors it<br />
reduces to about one-third of the total time. The sudden jumps occur when the vector<br />
length crosses a multiple of 64, forcing another iteration of the strip-mining code and<br />
execution of a set of vector instructions. These operations increase T n by T loop + T start.<br />
To do so, we must consider how adjacent elements in B and adjacent elements<br />
in C are addressed. As we discussed in Section 5.5, when an array is allocated<br />
memory, it is linearized and must be laid out in either row-major or columnmajor<br />
order. This linearization means that either the elements in the row or the<br />
elements in the column are not adjacent in memory. For example, if the preceding<br />
loop were written in FORTRAN, which allocates column-major order, the elements<br />
of B that are accessed by iterations in the inner loop are separated by the<br />
row size times 8 (the number of bytes per entry) for a total of 800 bytes. In Chapter<br />
5, we saw that blocking could be used to improve the locality in cache-based<br />
systems. For vector processors without caches, we need another technique to<br />
fetch elements of a vector that are not adjacent in memory.<br />
This distance separating elements that are to be gathered into a single register<br />
is called the stride. In the current example, using column-major layout for the<br />
matrices means that matrix C has a stride of 1, or 1 double word (8 bytes), separating<br />
successive elements, and matrix B has a stride of 100, or 100 double words<br />
(800 bytes).<br />
Once a vector is loaded into a vector register it acts as if it had logically adjacent<br />
elements. Thus a vector-register processor can handle strides greater than<br />
one, called nonunit strides, using only vector-load and vector-store operations<br />
with stride capability. This ability to access nonsequential memory locations and














