

PhD Thesis Semi-Supervised Ensemble Methods for Computer Vision
PhD Thesis Semi-Supervised Ensemble Methods for Computer Vision
PhD Thesis Semi-Supervised Ensemble Methods for Computer Vision

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
72 Chapter 5. On-line <strong>Semi</strong>-<strong>Supervised</strong> Boosting<br />
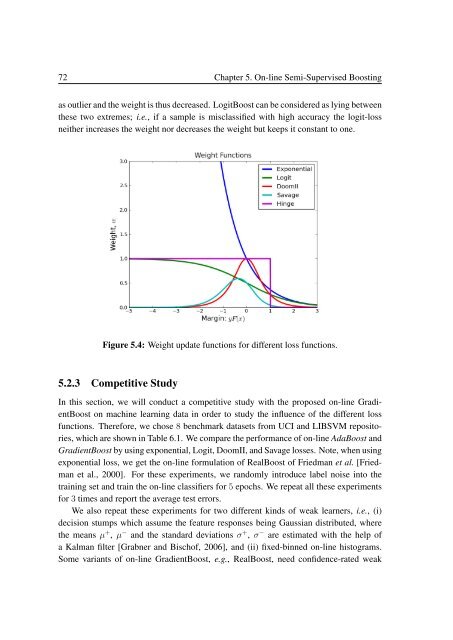
as outlier and the weight is thus decreased. LogitBoost can be considered as lying between<br />
these two extremes; i.e., if a sample is misclassified with high accuracy the logit-loss<br />
neither increases the weight nor decreases the weight but keeps it constant to one.<br />
Figure 5.4: Weight update functions <strong>for</strong> different loss functions.<br />
5.2.3 Competitive Study<br />
In this section, we will conduct a competitive study with the proposed on-line GradientBoost<br />
on machine learning data in order to study the influence of the different loss<br />
functions. There<strong>for</strong>e, we chose 8 benchmark datasets from UCI and LIBSVM repositories,<br />
which are shown in Table 6.1. We compare the per<strong>for</strong>mance of on-line AdaBoost and<br />
GradientBoost by using exponential, Logit, DoomII, and Savage losses. Note, when using<br />
exponential loss, we get the on-line <strong>for</strong>mulation of RealBoost of Friedman et al. [Friedman<br />
et al., 2000]. For these experiments, we randomly introduce label noise into the<br />
training set and train the on-line classifiers <strong>for</strong> 5 epochs. We repeat all these experiments<br />
<strong>for</strong> 3 times and report the average test errors.<br />
We also repeat these experiments <strong>for</strong> two different kinds of weak learners, i.e., (i)<br />
decision stumps which assume the feature responses being Gaussian distributed, where<br />
the means µ + , µ − and the standard deviations σ + , σ − are estimated with the help of<br />
a Kalman filter [Grabner and Bischof, 2006], and (ii) fixed-binned on-line histograms.<br />
Some variants of on-line GradientBoost, e.g., RealBoost, need confidence-rated weak
