

Resource Allocation in OFDM Based Wireless Relay Networks ...
Resource Allocation in OFDM Based Wireless Relay Networks ...
Resource Allocation in OFDM Based Wireless Relay Networks ...

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
4.5 Simulations<br />
40<br />
30<br />
20<br />
Sum−ρ<br />
Sum−P ObjSub<br />
JPC<br />
OPNC<br />
10<br />
0<br />
0 100 200 300 400 500<br />
Number of iterations<br />
1.5<br />
1<br />
0.5<br />
0<br />
FP<br />
GD<br />
FP−GD<br />
5 10 15 20 25<br />
Number of iterations<br />
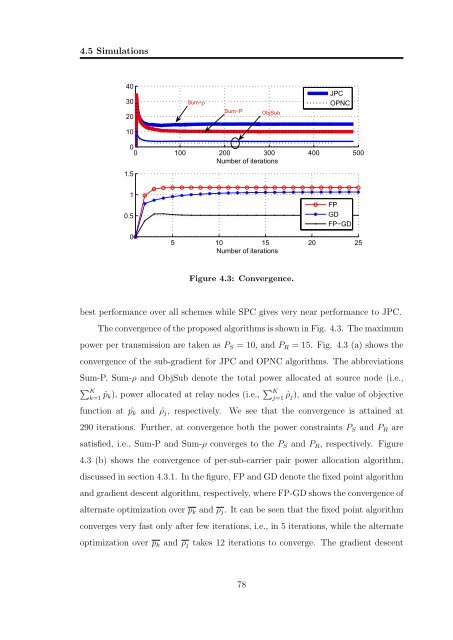
Figure 4.3: Convergence.<br />
best performance over all schemes while SPC gives very near performance to JPC.<br />
The convergence of the proposed algorithms is shown <strong>in</strong> Fig. 4.3. The maximum<br />
power per transmission are taken as P S = 10, and P R = 15. Fig. 4.3 (a) shows the<br />
convergence of the sub-gradient for JPC and OPNC algorithms. The abbreviations<br />
Sum-P, Sum-ρ and ObjSub denote the total power allocated at source node (i.e.,<br />
∑ K<br />
k=1 ˆp k), power allocated at relay nodes (i.e., ∑ K<br />
j=1 ˆρ j), and the value of objective<br />
function at ˆp k and ˆρ j , respectively. We see that the convergence is atta<strong>in</strong>ed at<br />
290 iterations. Further, at convergence both the power constra<strong>in</strong>ts P S and P R are<br />
satisfied, i.e., Sum-P and Sum-ρ converges to the P S and P R , respectively. Figure<br />
4.3 (b) shows the convergence of per-sub-carrier pair power allocation algorithm,<br />
discussed <strong>in</strong> section 4.3.1. In the figure, FP and GD denote the fixed po<strong>in</strong>t algorithm<br />
and gradient descent algorithm, respectively, where FP-GD shows the convergence of<br />
alternate optimization over p k and ρ j . It can be seen that the fixed po<strong>in</strong>t algorithm<br />
converges very fast only after few iterations, i.e., <strong>in</strong> 5 iterations, while the alternate<br />
optimization over p k and ρ j takes 12 iterations to converge. The gradient descent<br />
78














