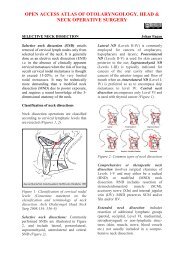
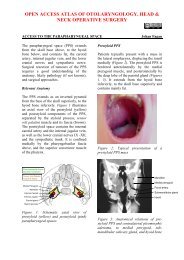
Hello Processing - Vula
Hello Processing - Vula
Hello Processing - Vula

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
An Introduction To Programming With <strong>Processing</strong><br />
small data set with a high ratio of inconsistent data types, manual data mining<br />
could be more effective and save you some time.<br />
For example, lets take a hypothetical situation where the owner of a small café<br />
has asked you to determine what items a customer is likely to purchase together.<br />
The data set you have acquired consists of all the items customers have purchased<br />
in the store over the past year. From that data you could determine that goods can<br />
be divided up into food, drinks, magazines, stationary etc, and then into even<br />
smaller groups like fruit, vegetables, soft-drinks etc. Identifying these groups<br />
would be the first step of data mining and is a process also known as clustering. If<br />
the café has a large variety of items to choose from the clusters making up the<br />
data could resultantly be numerous, yet the data set as a whole is actually quite<br />
small, only consisting of a single year of purchased items.<br />
In contrast a more established café that has been operating for several years<br />
proposes the same question to you. In the case of the smaller café groupings of<br />
purchased items would yield a lower probability of repeating in a shorter period<br />
of time. In contrast the more established café has a better chance of the same<br />
groups of items being purchased together over a longer period of time.<br />
In the former case manually mining this data set could be more effective because<br />
of the lower probability of the same items being purchased together in a relatively<br />
short space of time. In this scenario the majority of your time would be spent on<br />
clustering and populating the resultant groups after eliminating the majority of<br />
items purchased in that year because they will not fall into any cluster.<br />
However in the case of the established café although there may be just as many<br />
clusters the values that these clusters are populated with have a higher probability<br />
of being repeated, it might therefore be more efficient to have a computer<br />
program count, cluster and mine the data.<br />
Regardless of whether you choose to manually mine your data or have a software<br />
program do the work for you, you should have a set of data at the end of the<br />
process that can be manipulated programmatically.<br />
A Scalable Software Development Model 30