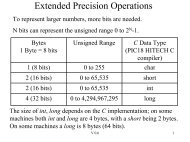
Modified Fisher's Linear Discriminant Analysis for ... - IEEE Xplore
Modified Fisher's Linear Discriminant Analysis for ... - IEEE Xplore
Modified Fisher's Linear Discriminant Analysis for ... - IEEE Xplore

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
<strong>IEEE</strong> GEOSCIENCE AND REMOTE SENSING LETTERS, VOL. 4, NO. 4, OCTOBER 2007 503<br />
<strong>Modified</strong> Fisher’s <strong>Linear</strong> <strong>Discriminant</strong> <strong>Analysis</strong><br />
<strong>for</strong> Hyperspectral Imagery<br />
Qian Du, Senior Member, <strong>IEEE</strong><br />
Abstract—In this letter, we present a modified Fisher’s linear<br />
discriminant analysis (MFLDA) <strong>for</strong> dimension reduction in hyperspectral<br />
remote sensing imagery. The basic idea of the Fisher’s<br />
linear discriminant analysis (FLDA) is to design an optimal trans<strong>for</strong>m,<br />
which can maximize the ratio of between-class to withinclass<br />
scatter matrices so that the classes can be well separated<br />
in the low-dimensional space. The practical difficulty of applying<br />
FLDA to hyperspectral images includes the unavailability of<br />
enough training samples and unknown in<strong>for</strong>mation <strong>for</strong> all the<br />
classes present. So the original FLDA is modified to avoid the<br />
requirements of training samples and complete class knowledge.<br />
The MFLDA requires the desired class signatures only. The classification<br />
result using the MFLDA-trans<strong>for</strong>med data shows that the<br />
desired class in<strong>for</strong>mation is well preserved and they can be easily<br />
separated in the low-dimensional space.<br />
Index Terms—Classification, dimension reduction, Fisher’s linear<br />
discriminant analysis (FLDA), hyperspectral imagery.<br />
I. INTRODUCTION<br />
FISHER’S linear discriminant analysis (FLDA) is a standard<br />
technique <strong>for</strong> dimension reduction in pattern recognition.<br />
It projects the original high-dimensional data onto a<br />
low-dimensional space, where all the classes are well separated<br />
by maximizing the Raleigh quotient, i.e., the ratio of betweenclass<br />
scatter matrix to within-class scatter matrix [1]. Assume<br />
there are n training sample vectors given by {r i } n i=1 <strong>for</strong> p<br />
classes: C 1 ,C<br />
∑ 2 ,...,C p , and there are n j samples <strong>for</strong> the jth<br />
class, i.e., p<br />
j=1 n j = n. Let µ be the mean of the entire<br />
training samples, i.e., (1/n) ∑ n<br />
i=1 r i = µ, and µ j be the mean<br />
of the jth class, i.e., (1/n j ) ∑ r i ∈C j<br />
r i = µ j . Then, the withinclass<br />
scatter matrix S W and the between-class scatter matrix<br />
S B are defined, respectively, as<br />
S W = ∑<br />
(r i − µ j )(r i − µ j ) T (1)<br />
r i ∈C j<br />
p∑<br />
S B = n j (µ j − µ)(µ j − µ) T . (2)<br />
j=1<br />
Manuscript received December 8, 2006; revised April 21, 2007. This work<br />
was supported in part by the National Geospatial-Intelligence Agency under<br />
Grant HM15810512006.<br />
The author is with the Department of Electrical and Computer Engineering<br />
and GeoResources Institute in High Per<strong>for</strong>mance Computing Collaboratory,<br />
Mississippi State University, Starkville, MS 39762 USA (e-mail: du@ece.<br />
msstate.edu).<br />
Color versions of one or more of the figures in this paper are available online<br />
at http://ieeexplore.ieee.org.<br />
Digital Object Identifier 10.1109/LGRS.2007.900751<br />
The goal is to find a trans<strong>for</strong>m vector w such that the Raleigh<br />
quotient is maximized, which is defined as<br />
q = wT S B w<br />
w T S W w . (3)<br />
w can be determined by solving a generalized eigenproblem<br />
specified by S B w = λS W w, where λ is a generalized eigenvalue.<br />
Since the rank of S B is p − 1, there are p − 1 eigenvectors<br />
associated with p − 1 nonzero eigenvalues. There<strong>for</strong>e, an<br />
L × (p − 1) matrix W can be found to trans<strong>for</strong>m the original<br />
L-dimensional data into a (p − 1)-dimensional space. In this<br />
low-dimensional space, it is expected that the p classes can be<br />
well separated.<br />
The application of FLDA to hyperspectral images has been<br />
investigated <strong>for</strong> classification in [2] and [3] and <strong>for</strong> linear spectral<br />
mixture analysis in [5]. The major problem when applying<br />
FLDA to remote sensing imagery is the difficulty in finding<br />
enough training samples <strong>for</strong> all the classes. In particular, <strong>for</strong> an<br />
L-band hyperspectral image, L linearly independent samples<br />
are required to make S W full rank. Sample selection becomes<br />
very difficult when pixels are mixed due to low spatial resolution.<br />
Moreover, it may be impossible to know the in<strong>for</strong>mation<br />
of all the classes present in an image scene, such as the number<br />
of background classes and their signatures.<br />
In [2] and [3], the ratio of interclass distance to intraclass<br />
distance replaced the Raleigh quotient with the constraint that<br />
different class centers would be aligned along different directions<br />
as proposed in [4]. The resulting algorithm was referred<br />
to as constrained linear discriminant analysis (CLDA). In [5],<br />
the same constraint in [2]–[4] was employed when the original<br />
Raleigh quotient was to be maximized. The resulting algorithm<br />
was called constrained FLDA (CFLDA) in this letter. Since the<br />
constraint is applied, CLDA and CFLDA are actually classifiers<br />
because classification is achieved simultaneously with the<br />
trans<strong>for</strong>ms.<br />
In this letter, we will investigate linear discriminant analysis<br />
(LDA) under the original mechanism of FLDA without any<br />
constraint. Specifically, we intend to relax the requirements<br />
on the training samples and complete knowledge about all<br />
the classes present in an image scene. The developed algorithm<br />
is referred to as modified FLDA (MFLDA). It should<br />
be noted that MFLDA conducts dimension reduction only as<br />
the original FLDA does. If detection or classification needs<br />
to be accomplished, a detector or classifier has to be applied<br />
to the trans<strong>for</strong>med data. The per<strong>for</strong>mance of MFLDA will be<br />
compared with FLDA, CFLDA, and CLDA in terms of the class<br />
separability in the low-dimensional space.<br />
1545-598X/$25.00 © 2007 <strong>IEEE</strong>
504 <strong>IEEE</strong> GEOSCIENCE AND REMOTE SENSING LETTERS, VOL. 4, NO. 4, OCTOBER 2007<br />
II. MFLDA<br />
Let the total scatter matrix S T be defined as<br />
S T =<br />
n∑<br />
(r i − µ)(r i − µ) T (4)<br />
i=1<br />
and it can be related with S W and S B by [1]<br />
S T = S W + S B . (5)<br />
So the maximization of (3) is equivalent to maximizing<br />
q ′ = wT S B w<br />
w T S T w . (6)<br />
Following the same idea of FLDA, the solution will be the<br />
eigenvectors of the generalized eigenproblem: S B w = λS T w.<br />
When the only available in<strong>for</strong>mation is the class signatures<br />
{s 1 , s 2 ,...,s p }, they can be treated as class means, i.e., M =<br />
[µ 1 µ 2 ···µ p ] ≈ [s 1 s 2 ···s p ].TheS B in (2) becomes<br />
Ŝ B =<br />
p∑<br />
(s j − ˆµ)(s j − ˆµ) T (7)<br />
j=1<br />
where ˆµ is the mean of class signatures, i.e., (1/p) ∑ p<br />
i=1 s i =<br />
ˆµ. S T in (4) can be replaced by the data covariance<br />
matrix Σ, i.e.,<br />
Ŝ T =Σ=<br />
N∑<br />
(r i − ˜µ)(r i − ˜µ) T (8)<br />
i=1<br />
where ˜µ is the sample mean of the entire data set with N pixels,<br />
i.e., (1/N ) ∑ N<br />
i=1 r i = ˜µ. Then, the solution is the eigenvectors<br />
of the generalized eigenproblem: ŜBw = λΣw or Σ −1 Ŝ B .<br />
Regardless of the actual classes present in the data, replacing<br />
S T with Σ represents an extreme case, which means all the<br />
pixels are separated into the classes they belong to and selected<br />
as samples. Using ŜB as S B represents another extreme case,<br />
which means there is only one sample in each class. So the<br />
discrepancy incurred comes from two factors: only one sample<br />
(i.e., class signature) <strong>for</strong> each of the p classes is used to estimate<br />
S B , and all the pixels are used to estimate S T with the implicit<br />
assumption that pixels are put into all the existing classes<br />
including unknown background classes (i.e., the actual number<br />
of classes p T may be greater than p). In the experiments, it will<br />
be shown that the term Σ −1 is very effective in background<br />
suppression.<br />
Since the rank of ŜB is the same as S B , which is (p − 1),<br />
the dimensionality of the MFLDA-trans<strong>for</strong>med data is (p − 1)<br />
as that of FLDA. After the data are projected onto this (p − 1)-<br />
dimensional space, an algorithm is needed <strong>for</strong> some tasks, such<br />
as classification or detection. A less powerful distance-based<br />
classifier such as the Spectral Angle Mapper (SAM) can be<br />
applied. Or, a more powerful filter, such as target constrained<br />
interference minimized filter (TCIMF), may be used [6].<br />
III. RELATIONSHIP BETWEEN LDA-BASED APPROACHES<br />
A. Relationship Between FLDA and CFLDA<br />
The CFLDA in [5] imposed a constraint to align the class<br />
centers along with different directions [4], i.e.,<br />
w T l µ j = δ lj , <strong>for</strong> 1 ≤ l; j ≤ p. (9)<br />
This also means that the jth trans<strong>for</strong>m vector w j is <strong>for</strong> the<br />
jth class. So the CFLDA-trans<strong>for</strong>med data are actually classification<br />
maps. It can be derived that when the constraint<br />
was satisfied, w T S B w was a constant. Thus, the constrained<br />
problem would be to minimize w T S W w in (3) while satisfying<br />
the constraint in (9). Using the Lagrange multiplier approach,<br />
it was shown that the desired trans<strong>for</strong>m matrix W including all<br />
the p trans<strong>for</strong>m vectors is<br />
W CFLDA = S −1<br />
W M ( M T S −1<br />
W M) −1<br />
. (10)<br />
Obviously, the implementation of CFLDA requires the<br />
knowledge of the training samples of each class to compute<br />
S W .<br />
B. Relationship Between CFLDA, CLDA, and MFLDA<br />
Following the same idea of FLDA in maximizing the class<br />
separability, the CLDA in [2] and [3] imposed the same<br />
constraint that different classes were aligned along different<br />
directions as in (9). To make the constrained problem easier to<br />
solve, it employed the ratio of within-class and between-class<br />
distances instead of the Raleigh quotient [4]. It was proved that<br />
the trans<strong>for</strong>med within-class distance is a constant when the<br />
constraint in (9) was satisfied. It also used the data covariance<br />
matrix Σ to substitute S T as in MFLDA. It was proved that the<br />
trans<strong>for</strong>m matrix W is equivalent to [3]<br />
W CLDA =Σ −1 M(M T Σ −1 M) −1 . (11)<br />
Equation (11) is similar to (10) except that S W is replaced<br />
with Σ. There<strong>for</strong>e, CLDA does not require the training samples<br />
in each class and it needs the class signatures only. Similar to<br />
CFLDA, CLDA was designed <strong>for</strong> classification, so the classification<br />
maps were obtained right after the trans<strong>for</strong>m.<br />
C. Use of Σ and S W<br />
Both CFLDA and CLDA apply the constraint in (9), resulting<br />
in the similar operators in (10) and (11) with the difference<br />
that CLDA uses Σ while CFLDA uses S W . So CLDA does<br />
not require the training samples, which is the same as in<br />
MFLDA. There is another benefit of using Σ. As mentioned<br />
earlier, the true number of classes present in an image scene<br />
p T is greater than p due to the difficulty of exhausting all the<br />
present classes, in particular, those background classes. In the<br />
ideal case when all the pixels in an image scene are put into<br />
the p T classes, S T =Σ. There<strong>for</strong>e, using Σ in LDA-based<br />
approaches represents the best situation <strong>for</strong> S T , which means
DU: MODIFIED FISHER’S LINEAR DISCRIMINANT ANALYSIS FOR HYPERSPECTRAL IMAGERY 505<br />
Fig. 1. (a) HYDICE image scene with 30 panels. (b) Spatial locations of the<br />
30 panels that were provided by ground truth.<br />
all the classes can be well separated without knowing these<br />
class in<strong>for</strong>mation. This is particularly important to suppress<br />
the background classes <strong>for</strong> better extraction of the <strong>for</strong>eground<br />
classes. Σ −1 represents the data whitening term, which has<br />
the power to suppress the unknown background classes [7].<br />
There<strong>for</strong>e, in general it is reasonable and desirable to use Σ<br />
to replace S W or S T in the practical implementation of LDA.<br />
IV. EXPERIMENTS<br />
A. HYDICE<br />
The HYperspectral Digital Imagery Collection Experiment<br />
(HYDICE) image scene shown in Fig. 1 includes 30 panels<br />
arranged in a 10 × 3 matrix [3]. The three panels in the same<br />
row, i.e., p ia , p ib , p ic , were made from the same material of<br />
sizes 3 m × 3m,2m× 2m,and1m× 1 m, respectively,<br />
which can be considered as one class, P i <strong>for</strong> 1 ≤ i ≤ 10. The<br />
pixel-level ground truth map in Fig. 1(b) shows the precise<br />
locations of pure panel pixels. These panel classes have very<br />
close signatures <strong>for</strong> differentiation.<br />
A pure pixel from each leftmost panel (3 m × 3m)was<br />
used as the corresponding class signature. Fig. 2(a) shows the<br />
classification result using SAM on the original data, where<br />
the panels could not be classified. Here, the minimum angle<br />
was displayed in white, the maximum angle in black,<br />
and others in shades between white and black. Fig. 2(b)<br />
is the result using TCIMF, which is a more powerful filter,<br />
on the original image, where the panels were well detected<br />
and separated. Fig. 2(c) shows the SAM classification<br />
result using the 9-D MFLDA-trans<strong>for</strong>med data, where the<br />
panels were correctly classified. This demonstrates that<br />
MFLDA successfully separated the ten panel classes when<br />
per<strong>for</strong>ming dimension reduction, allowing a less powerful classifier,<br />
such as SAM, to correctly classify these classes, which is<br />
impossible when using the original 169-D data.<br />
To quantify the per<strong>for</strong>mance of MFLDA and compare it with<br />
that of TCIMF using the original data, each classification map<br />
was normalized to [0 1] and converted to a binary map with a<br />
threshold η. The binary classification maps were compared with<br />
the pure panel pixels provided as ground truth. The accurately<br />
detected panel pixels were counted as N D and false alarm as<br />
N F . To comprehensively evaluate the per<strong>for</strong>mance, the similar<br />
concept of receiver operating characteristic (ROC) curve was<br />
adopted here [8]. As η was changed from 0.1 to 0.9, an ROC<br />
curve could be estimated. For the 28-pixel test set, the resulting<br />
ROCs with the averaged probability of false alarm (Pf) and<br />
Fig. 2. Comparison between the classification results using the original and<br />
MFLDA-trans<strong>for</strong>med data. (a) SAM (soft) classification result on the original<br />
data. (b) TCIMF (soft) classification result on the original data. (c) SAM (soft)<br />
classification result on the MFLDA-trans<strong>for</strong>med data.<br />
probability of detection (Pd) are shown in Fig. 3. The larger<br />
the area under a curve, the better the per<strong>for</strong>mance [9]. We<br />
can see that SAM on the MFLDA-trans<strong>for</strong>med data slightly<br />
outper<strong>for</strong>ms TCIMF on the original data.<br />
To further compare the results in Fig. 2, Table I lists the<br />
largest number of detected pixels in the test set (N D ) when no<br />
false alarm exists (N F =0). This happened when η =0.6 <strong>for</strong><br />
the MFLDA with SAM and η =0.4 <strong>for</strong> TCIMF. By applying<br />
MFLDA followed by SAM, 21 out of 28 panel pixels in the
506 <strong>IEEE</strong> GEOSCIENCE AND REMOTE SENSING LETTERS, VOL. 4, NO. 4, OCTOBER 2007<br />
Fig. 4. AVIRIS Cuprite image scene. (a) Spectral band image. (b) Spatial<br />
locations of five pure pixels corresponding to the following minerals: alunite<br />
(A), buddingtonite (B), calcite (C), kaolinite (K), and muscovite (M).<br />
Fig. 3.<br />
ROC curves in the HYDICE <strong>for</strong> the test set.<br />
TABLE I<br />
(LARGEST)NUMBER OF DETECTED PIXELS (N D ) IN THE<br />
TEST SET WHEN NO FALSE ALARM EXISTS (N F =0)<br />
TABLE II<br />
(SMALLEST)NUMBER OF FALSE ALARM PIXELS (N F ) WHEN<br />
ALL PIXELS IN THE TEST SET ARE DETECTED (N D = 28)<br />
test set were detected, whereas TCIMF using the original data<br />
detected 19 pixels. By slightly decreasing the threshold, all the<br />
28 pixels could be detected although the false alarm was not<br />
zero any more. Table II lists the smallest N F when all the<br />
28 panel pixels in the test set were still detected, corresponding<br />
to η =0.5 <strong>for</strong> MFLDA and η =0.2 <strong>for</strong> TCIMF. In this case,<br />
N F = 150 from MFLDA, which is much smaller than 6952<br />
from TCIMF.<br />
B. AVIRIS Experiment<br />
To compare the four LDA techniques, the Airborne Visible/<br />
Infrared Imaging Spectrometer (AVIRIS) Cuprite scene as<br />
shown in Fig. 4 was used, which is well understood mineralogically<br />
[5]. At least five minerals were present, namely:<br />
1) alunite (A), 2) buddingtonite (B), 3) calcite (C), 4) kaolinite<br />
(K), and 5) muscovite (M). The approximate spatial locations<br />
of these minerals are marked in Fig. 4(b). However, no pixel<br />
level ground truth is available. Due to the scene complexity, the<br />
actual number of classes p T is much greater than five.<br />
To compare the per<strong>for</strong>mance of FLDA, MFLDA, CFLDA,<br />
and CLDA, SAM and TCIMF were applied to the original<br />
and trans<strong>for</strong>med data. To conduct FLDA and CFLDA, training<br />
samples were generated by comparing with the five material<br />
endmembers using SAM, and the number of training samples<br />
<strong>for</strong> the five classes were 63, 59, 69, 72, and 63, respectively.<br />
As shown in Fig. 5(a), with the original data, SAM could not<br />
classify these five minerals, but TCIMF provided accurate result<br />
as shown in Fig. 5(b). Fig. 5(c) and (d) shows the SAM and<br />
TCIMF results using the 4-D FLDA-trans<strong>for</strong>med data, respectively,<br />
where the SAM result was slightly improved but the classification<br />
result was still incorrect and the TCIMF result was<br />
much worse than that in Fig. 5(b) when the original data were<br />
used. If SAM was applied to the 4-D MFLDA-trans<strong>for</strong>med<br />
data, the classification was improved as in Fig. 5(e), and the<br />
TCIMF result in Fig. 5(f) was as good as in Fig. 5(b) using the<br />
189-band data. The CFLDA on the 189-band original data was<br />
shown in Fig. 5(g), which included a lot of misclassifications<br />
due to the use of S W that was estimated under the assumption<br />
that only five classes were present. The CLDA on the original<br />
data in Fig. 5(h) did as well as the TCIMF in Fig. 5(b) since<br />
the matrices R and Σ in the operators have the same role on<br />
background suppression.<br />
To per<strong>for</strong>m quantitative comparison, Table III lists the spatial<br />
correlation coefficients between the result from the use of LDAtrans<strong>for</strong>med<br />
data and that from the TCIMF on the original<br />
data, where a value closer to one is associated with better<br />
classification. It is obvious that MFLDA outper<strong>for</strong>ms FLDA<br />
and CFLDA, and it per<strong>for</strong>ms comparably to CLDA but on the<br />
data with much lower dimensionality. This means Σ is a better<br />
term than S W when the actual number of classes and their<br />
in<strong>for</strong>mation are difficult or even impossible to obtain.<br />
V. C ONCLUSION<br />
The original FLDA is modified <strong>for</strong> hyperspectral image<br />
dimension reduction when enough class training samples are<br />
unavailable. This situation comes from the existence of mixed
DU: MODIFIED FISHER’S LINEAR DISCRIMINANT ANALYSIS FOR HYPERSPECTRAL IMAGERY 507<br />
TABLE III<br />
CLASSIFICATION RESULTS COMPARED WITH THE TCIMF RESULT USING<br />
ORIGINAL DATA (CORRELATION COEFFICIENT) IN AVIRIS EXPERIMENT<br />
The experiments demonstrate that MFLDA can well preserve<br />
and separate classes in the low-dimensional space, where a<br />
simple classifier such as SAM may easily classify them, which<br />
is difficult if the original high-dimensional data were used.<br />
The term Σ −1 in MFLDA has the function of background<br />
suppression, which is particularly important when background<br />
classes are unknown. Thus, it outper<strong>for</strong>ms FLDA and CFLDA<br />
that employ S W . Compared to CLDA, which is actually<br />
a classifier, the MFLDA-trans<strong>for</strong>med low-dimensional data<br />
permits similar classification to that from the original highdimensional<br />
data.<br />
In summary, the novelty of the MFLDA approach includes<br />
the following: 1) it makes FLDA feasible when training samples<br />
are unavailable; 2) it makes FLDA feasible when complete<br />
class in<strong>for</strong>mation (including background) are unavailable; and<br />
3) when FLDA (and other LDA-based approaches) can be<br />
implemented, it improves the per<strong>for</strong>mance in background suppression<br />
and class separability by replacing S W or S T with Σ.<br />
The MFLDA-based dimension reduction does require desired<br />
class signatures. In practice, a laboratory or field measurement<br />
can be used as a class signature. When these options are<br />
not appropriate estimates, the results from an endmember extraction<br />
algorithm such as pixel purity index may be considered<br />
as the substitute.<br />
Fig. 5. AVIRIS classification results [from left to right: alunite (A), buddingtonite<br />
(B), calcite (C), kaolinite (K), and muscovite (M)]. (a) SAM on<br />
the original data. (b) TCIMF on the original data. (c) SAM on the FLDAtrans<strong>for</strong>med<br />
data. (d) TCIMF on the FLDA-trans<strong>for</strong>med data. (e) SAM on<br />
the MFLDA-trans<strong>for</strong>med data. (f) TCIMF on the MFLDA-trans<strong>for</strong>med data.<br />
(g) CFLDA on the original data. (h) CLDA on the original data.<br />
pixels and classes appearing in small size due to low spatial resolution.<br />
When class signatures are known, they can be used to<br />
estimate S B , and Σ can be used to estimate S T . Such treatment<br />
generally makes the signal subspace less class-dependent.<br />
REFERENCES<br />
[1] R.O.DudaandP.E.Hart,Pattern Classification and Scene <strong>Analysis</strong>. New<br />
York: Wiley, 1973.<br />
[2] Q. Du and C.-I Chang, “<strong>Linear</strong> constrained distance-based discriminant<br />
analysis <strong>for</strong> hyperspectral image classification,” Pattern Recognit., vol. 34,<br />
no. 2, pp. 361–373, 2001.<br />
[3] Q. Du and H. Ren, “Real-time constrained linear discriminant analysis<br />
to target detection and classification in hyperspectral imagery,” Pattern<br />
Recognit., vol. 36, no. 1, pp. 1–8, 2003.<br />
[4] H. Soltanian-Zadeh, J. P. Windham, and D. J. Peck, “Optimal linear trans<strong>for</strong>mation<br />
<strong>for</strong> MRI feature extraction,” <strong>IEEE</strong> Trans. Med. Imag., vol. 15,<br />
no. 6, pp. 749–767, Dec. 1996.<br />
[5] C.-I Chang and B.-H. Ji, “Fisher’s linear spectral mixture analysis,” <strong>IEEE</strong><br />
Trans. Geosci. Remote Sens., vol. 44, no. 8, pp. 2292–2304, Aug. 2006.<br />
[6] H. Ren and C.-I Chang, “A target-constrained interference-minimized approach<br />
to subpixel detection <strong>for</strong> hyperspectral images,” Opt. Eng., vol. 39,<br />
no. 12, pp. 3138–3145, 2000.<br />
[7] Q. Du, H. Ren, and C.-I Chang, “A comparative study <strong>for</strong> orthogonal<br />
subspace projection and constrained energy minimization,” <strong>IEEE</strong> Trans.<br />
Geosci. Remote Sens., vol. 41, no. 6, pp. 1525–1529, Jun. 2003.<br />
[8] H. V. Poor, An Introduction to Signal Detection and Estimation, 2nd ed.<br />
New York: Springer-Verlag, 1994.<br />
[9] C. E. Metz, “ROC methodology in radiological imaging,” Invest. Radiol.,<br />
vol. 21, no. 9, pp. 720–733, 1986.