

Data Replication in Data Intensive Scientific Applications - CiteSeerX
Data Replication in Data Intensive Scientific Applications - CiteSeerX
Data Replication in Data Intensive Scientific Applications - CiteSeerX

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
14<br />
Average file access time (second)<br />
3000<br />
2500<br />
2000<br />
1500<br />
1000<br />
500<br />
Ditributed <strong>in</strong> Random<br />
Cascad<strong>in</strong>g <strong>in</strong> Random<br />
Distributed <strong>in</strong> TS-Static<br />
Cascad<strong>in</strong>g <strong>in</strong> TS-Static<br />
Distributed <strong>in</strong> TS-Dynamic<br />
Cascad<strong>in</strong>g <strong>in</strong> TS-Dynamic<br />
Average file access time (second)<br />
3000<br />
2500<br />
2000<br />
1500<br />
1000<br />
500<br />
Ditributed <strong>in</strong> Random<br />
Cascad<strong>in</strong>g <strong>in</strong> Random<br />
Distributed <strong>in</strong> TS-Static<br />
Cascad<strong>in</strong>g <strong>in</strong> TS-Static<br />
Distributed <strong>in</strong> TS-Dynamic<br />
Cascad<strong>in</strong>g <strong>in</strong> TS-Dynamic<br />
0<br />
1000 2000 3000 4000 5000<br />
Total number of files<br />
0<br />
100 200 300 400 500<br />
Storage Capacity (GB)<br />
(a) Vary<strong>in</strong>g total number of files.<br />
(b) Vary<strong>in</strong>g storage capacity of each site.<br />
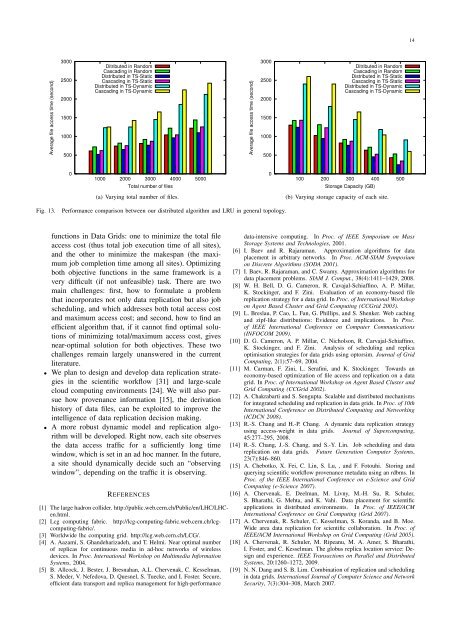
Fig. 13.<br />
Performance comparison between our distributed algorithm and LRU <strong>in</strong> general topology.<br />
functions <strong>in</strong> <strong>Data</strong> Grids: one to m<strong>in</strong>imize the total file<br />
access cost (thus total job execution time of all sites),<br />
and the other to m<strong>in</strong>imize the makespan (the maximum<br />
job completion time among all sites). Optimiz<strong>in</strong>g<br />
both objective functions <strong>in</strong> the same framework is a<br />
very difficult (if not unfeasible) task. There are two<br />
ma<strong>in</strong> challenges: first, how to formulate a problem<br />
that <strong>in</strong>corporates not only data replication but also job<br />
schedul<strong>in</strong>g, and which addresses both total access cost<br />
and maximum access cost; and second, how to f<strong>in</strong>d an<br />
efficient algorithm that, if it cannot f<strong>in</strong>d optimal solutions<br />
of m<strong>in</strong>imiz<strong>in</strong>g total/maximum access cost, gives<br />
near-optimal solution for both objectives. These two<br />
challenges rema<strong>in</strong> largely unanswered <strong>in</strong> the current<br />
literature.<br />
• We plan to design and develop data replication strategies<br />
<strong>in</strong> the scientific workflow [31] and large-scale<br />
cloud comput<strong>in</strong>g environments [24]. We will also pursue<br />
how provenance <strong>in</strong>formation [15], the derivation<br />
history of data files, can be exploited to improve the<br />
<strong>in</strong>telligence of data replication decision mak<strong>in</strong>g.<br />
• A more robust dynamic model and replication algorithm<br />
will be developed. Right now, each site observes<br />
the data access traffic for a sufficiently long time<br />
w<strong>in</strong>dow, which is set <strong>in</strong> an ad hoc manner. In the future,<br />
a site should dynamically decide such an “observ<strong>in</strong>g<br />
w<strong>in</strong>dow”, depend<strong>in</strong>g on the traffic it is observ<strong>in</strong>g.<br />
REFERENCES<br />
[1] The large hadron collider. http://public.web.cern.ch/Public/en/LHC/LHCen.html.<br />
[2] Lcg comput<strong>in</strong>g fabric. http://lcg-comput<strong>in</strong>g-fabric.web.cern.ch/lcgcomput<strong>in</strong>g-fabric/.<br />
[3] Worldwide lhc comput<strong>in</strong>g grid. http://lcg.web.cern.ch/LCG/.<br />
[4] A. Aazami, S. Ghandeharizadeh, and T. Helmi. Near optimal number<br />
of replicas for cont<strong>in</strong>uous media <strong>in</strong> ad-hoc networks of wireless<br />
devices. In Proc. International Workshop on Multimedia Information<br />
Systems, 2004.<br />
[5] B. Allcock, J. Bester, J. Bresnahan, A.L. Chervenak, C. Kesselman,<br />
S. Meder, V. Nefedova, D. Quesnel, S. Tuecke, and I. Foster. Secure,<br />
efficient data transport and replica management for high-performance<br />
data-<strong>in</strong>tensive comput<strong>in</strong>g. In Proc. of IEEE Symposium on Mass<br />
Storage Systems and Technologies, 2001.<br />
[6] I. Baev and R. Rajaraman. Approximation algorithms for data<br />
placement <strong>in</strong> arbitrary networks. In Proc. ACM-SIAM Symposium<br />
on Discrete Algorithms (SODA 2001).<br />
[7] I. Baev, R. Rajaraman, and C. Swamy. Approximation algorithms for<br />
data placement problems. SIAM J. Comput., 38(4):1411–1429, 2008.<br />
[8] W. H. Bell, D. G. Cameron, R. Cavajal-Schiaff<strong>in</strong>o, A. P. Millar,<br />
K. Stock<strong>in</strong>ger, and F. Z<strong>in</strong>i. Evaluation of an economy-based file<br />
replication strategy for a data grid. In Proc. of International Workshop<br />
on Agent Based Cluster and Grid Comput<strong>in</strong>g (CCGrid 2003).<br />
[9] L. Breslau, P. Cao, L. Fan, G. Phillips, and S. Shenker. Web cach<strong>in</strong>g<br />
and zipf-like distributions: Evidence and implications. In Proc.<br />
of IEEE International Conference on Computer Communications<br />
(INFOCOM 2009).<br />
[10] D. G. Cameron, A. P. Millar, C. Nicholson, R. Carvajal-Schiaff<strong>in</strong>o,<br />
K. Stock<strong>in</strong>ger, and F. Z<strong>in</strong>i. Analysis of schedul<strong>in</strong>g and replica<br />
optimisation strategies for data grids us<strong>in</strong>g optorsim. Journal of Grid<br />
Comput<strong>in</strong>g, 2(1):57–69, 2004.<br />
[11] M. Carman, F. Z<strong>in</strong>i, L. Seraf<strong>in</strong>i, and K. Stock<strong>in</strong>ger. Towards an<br />
economy-based optimization of file access and replication on a data<br />
grid. In Proc. of International Workshop on Agent Based Cluster and<br />
Grid Comput<strong>in</strong>g (CCGrid 2002).<br />
[12] A. Chakrabarti and S. Sengupta. Scalable and distributed mechanisms<br />
for <strong>in</strong>tegrated schedul<strong>in</strong>g and replication <strong>in</strong> data grids. In Proc. of 10th<br />
International Conference on Distributed Comput<strong>in</strong>g and Network<strong>in</strong>g<br />
(ICDCN 2008).<br />
[13] R.-S. Chang and H.-P. Chang. A dynamic data replication strategy<br />
us<strong>in</strong>g access-weight <strong>in</strong> data grids. Journal of Supercomput<strong>in</strong>g,<br />
45:277–295, 2008.<br />
[14] R.-S. Chang, J.-S. Chang, and S.-Y. L<strong>in</strong>. Job schedul<strong>in</strong>g and data<br />
replication on data grids. Future Generation Computer Systems,<br />
23(7):846–860.<br />
[15] A. Chebotko, X. Fei, C. L<strong>in</strong>, S. Lu, , and F. Fotouhi. Stor<strong>in</strong>g and<br />
query<strong>in</strong>g scientific workflow provenance metadata us<strong>in</strong>g an rdbms. In<br />
Proc. of the IEEE International Conference on e-Science and Grid<br />
Comput<strong>in</strong>g (e-Science 2007).<br />
[16] A. Chervenak, E. Deelman, M. Livny, M.-H. Su, R. Schuler,<br />
S. Bharathi, G. Mehta, and K. Vahi. <strong>Data</strong> placement for scientific<br />
applications <strong>in</strong> distributed environments. In Proc. of IEEE/ACM<br />
International Conference on Grid Comput<strong>in</strong>g (Grid 2007).<br />
[17] A. Chervenak, R. Schuler, C. Kesselman, S. Koranda, and B. Moe.<br />
Wide area data replication for scientific collaboration. In Proc. of<br />
IEEE/ACM International Workshop on Grid Comput<strong>in</strong>g (Grid 2005).<br />
[18] A. Chervenak, R. Schuler, M. Ripeanu, M. A. Amer, S. Bharathi,<br />
I. Foster, and C. Kesselman. The globus replica location service: Design<br />
and experience. IEEE Transactions on Parallel and Distributed<br />
Systems, 20:1260–1272, 2009.<br />
[19] N. N. Dang and S. B. Lim. Comb<strong>in</strong>ation of replication and schedul<strong>in</strong>g<br />
<strong>in</strong> data grids. International Journal of Computer Science and Network<br />
Security, 7(3):304–308, March 2007.












