

Data Replication in Data Intensive Scientific Applications - CiteSeerX
Data Replication in Data Intensive Scientific Applications - CiteSeerX
Data Replication in Data Intensive Scientific Applications - CiteSeerX

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
8<br />
Total Access Cost<br />
18000<br />
16000<br />
14000<br />
12000<br />
10000<br />
8000<br />
6000<br />
4000<br />
2000<br />
0<br />
500<br />
Greedy<br />
Local Greedy<br />
Random<br />
1000<br />
1500<br />
Number of Files<br />
2000<br />
Total Access Cost<br />
18000<br />
16000<br />
14000<br />
12000<br />
10000<br />
8000<br />
6000<br />
4000<br />
2000<br />
Greedy<br />
Local Greedy<br />
Random<br />
0<br />
10 20 30 40 50 60 70 80 90<br />
Storage Capacity (GB)<br />
Total Access Cost<br />
22000<br />
20000<br />
18000<br />
16000<br />
14000<br />
12000<br />
10000<br />
8000<br />
6000<br />
4000<br />
2000<br />
Greedy<br />
Local Greedy<br />
Random<br />
10 15 20 25 30 35 40 45 50<br />
Number of Grid sites<br />
(a) Vary<strong>in</strong>g number of data files.<br />
(b) Vary<strong>in</strong>g storage capacity.<br />
(c) Vary<strong>in</strong>g number of Grid sites.<br />
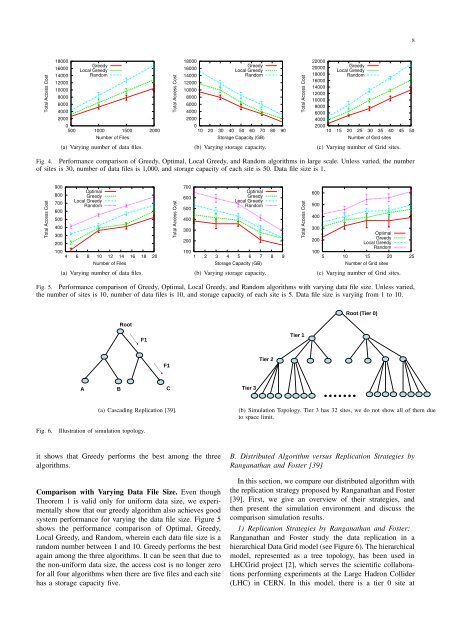
Fig. 4. Performance comparison of Greedy, Optimal, Local Greedy, and Random algorithms <strong>in</strong> large scale. Unless varied, the number<br />
of sites is 30, number of data files is 1,000, and storage capacity of each site is 50. <strong>Data</strong> file size is 1.<br />
Total Access Cost<br />
900<br />
800<br />
700<br />
600<br />
500<br />
400<br />
300<br />
200<br />
Optimal<br />
Greedy<br />
Local Greedy<br />
Random<br />
100<br />
4 6 8 10 12 14 16 18 20<br />
Number of Files<br />
Total Access Cost<br />
700<br />
600<br />
500<br />
400<br />
300<br />
200<br />
Optimal<br />
Greedy<br />
Local Greedy<br />
Random<br />
100<br />
1 2 3 4 5 6 7 8 9<br />
Storage Capacity (GB)<br />
Total Access Cost<br />
600<br />
500<br />
400<br />
300<br />
Optimal<br />
200<br />
Greedy<br />
Local Greedy<br />
Random<br />
100<br />
5 10 15 20 25<br />
Number of Grid sites<br />
(a) Vary<strong>in</strong>g number of data files.<br />
(b) Vary<strong>in</strong>g storage capacity.<br />
(c) Vary<strong>in</strong>g number of Grid sites.<br />
Fig. 5. Performance comparison of Greedy, Optimal, Local Greedy, and Random algorithms with vary<strong>in</strong>g data file size. Unless varied,<br />
the number of sites is 10, number of data files is 10, and storage capacity of each site is 5. <strong>Data</strong> file size is vary<strong>in</strong>g from 1 to 10.<br />
(a) Cascad<strong>in</strong>g <strong>Replication</strong> [39].<br />
(b) Simulation Topology. Tier 3 has 32 sites, we do not show all of them due<br />
to space limit.<br />
Fig. 6.<br />
Illustration of simulation topology.<br />
it shows that Greedy performs the best among the three<br />
algorithms.<br />
Comparison with Vary<strong>in</strong>g <strong>Data</strong> File Size. Even though<br />
Theorem 1 is valid only for uniform data size, we experimentally<br />
show that our greedy algorithm also achieves good<br />
system performance for vary<strong>in</strong>g the data file size. Figure 5<br />
shows the performance comparison of Optimal, Greedy,<br />
Local Greedy, and Random, where<strong>in</strong> each data file size is a<br />
random number between 1 and 10. Greedy performs the best<br />
aga<strong>in</strong> among the three algorithms. It can be seen that due to<br />
the non-uniform data size, the access cost is no longer zero<br />
for all four algorithms when there are five files and each site<br />
has a storage capacity five.<br />
B. Distributed Algorithm versus <strong>Replication</strong> Strategies by<br />
Ranganathan and Foster [39]<br />
In this section, we compare our distributed algorithm with<br />
the replication strategy proposed by Ranganathan and Foster<br />
[39]. First, we give an overview of their strategies, and<br />
then present the simulation environment and discuss the<br />
comparison simulation results.<br />
1) <strong>Replication</strong> Strategies by Ranganathan and Foster:<br />
Ranganathan and Foster study the data replication <strong>in</strong> a<br />
hierarchical <strong>Data</strong> Grid model (see Figure 6). The hierarchical<br />
model, represented as a tree topology, has been used <strong>in</strong><br />
LHCGrid project [2], which serves the scientific collaborations<br />
perform<strong>in</strong>g experiments at the Large Hadron Collider<br />
(LHC) <strong>in</strong> CERN. In this model, there is a tier 0 site at












