- Page 2 and 3:
Building Machine Learning Systems w
- Page 4 and 5:
Credits Authors Willi Richert Luis
- Page 6 and 7:
Luis Pedro Coelho is a Computationa
- Page 8 and 9:
Maurice HT Ling completed his PhD.
- Page 10 and 11:
Table of Contents Preface 1 Chapter
- Page 12 and 13:
Table of Contents Tuning the instan
- Page 14 and 15:
Table of Contents Improving classif
- Page 16 and 17:
Preface You could argue that it is
- Page 18 and 19:
Preface What you need for this book
- Page 20:
Downloading the example code You ca
- Page 23 and 24:
Getting Started with Python Machine
- Page 25 and 26:
Getting Started with Python Machine
- Page 27 and 28:
Getting Started with Python Machine
- Page 29 and 30:
Getting Started with Python Machine
- Page 31 and 32:
Getting Started with Python Machine
- Page 33 and 34:
Getting Started with Python Machine
- Page 35 and 36:
Getting Started with Python Machine
- Page 37 and 38:
Getting Started with Python Machine
- Page 39 and 40:
Getting Started with Python Machine
- Page 41 and 42:
Getting Started with Python Machine
- Page 43 and 44:
Getting Started with Python Machine
- Page 45 and 46:
Getting Started with Python Machine
- Page 48 and 49:
Learning How to Classify with Real-
- Page 50 and 51:
Chapter 2 We are using Matplotlib;
- Page 52 and 53:
Chapter 2 The last few lines select
- Page 54 and 55:
Chapter 2 error = 0.0 for ei in ran
- Page 56 and 57:
Chapter 2 We can play around with t
- Page 58 and 59:
Chapter 2 Features and feature engi
- Page 60 and 61:
Chapter 2 In the preceding screensh
- Page 62 and 63:
Chapter 2 Binary and multiclass cla
- Page 64 and 65:
Clustering - Finding Related Posts
- Page 66 and 67:
Chapter 3 How to do it More robust
- Page 68 and 69:
Chapter 3 This means that the first
- Page 70 and 71: Chapter 3 ... post = posts[i] ... i
- Page 72 and 73: Chapter 3 If you have a clear pictu
- Page 74 and 75: Chapter 3 Extending the vectorizer
- Page 76 and 77: Chapter 3 0.0 >>> print(tfidf("b",
- Page 78 and 79: Chapter 3 Flat clustering divides t
- Page 80 and 81: Because the cluster centers are mov
- Page 82 and 83: Chapter 3 'D:\\data\\379\\raw\\comp
- Page 84 and 85: As we have learned previously, we w
- Page 86 and 87: Chapter 3 Position Similarity Excer
- Page 88: Chapter 3 But before you go there,
- Page 91 and 92: Topic Modeling For those who are in
- Page 93 and 94: Topic Modeling Sparsity means that
- Page 95 and 96: Topic Modeling Although daunting at
- Page 97 and 98: Topic Modeling … for tj,v in t:
- Page 99 and 100: Topic Modeling Finally, we build th
- Page 101 and 102: Topic Modeling Alternatively, we ca
- Page 103 and 104: Topic Modeling Topic modeling was f
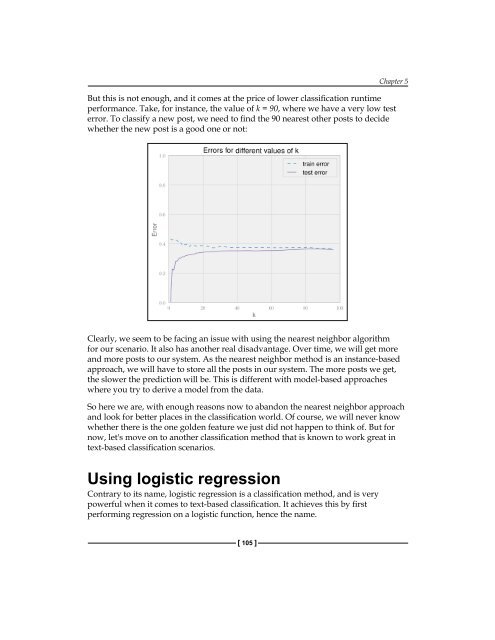
- Page 105 and 106: Classification - Detecting Poor Ans
- Page 107 and 108: Classification - Detecting Poor Ans
- Page 109 and 110: Classification - Detecting Poor Ans
- Page 111 and 112: Classification - Detecting Poor Ans
- Page 113 and 114: Classification - Detecting Poor Ans
- Page 115 and 116: Classification - Detecting Poor Ans
- Page 117 and 118: Classification - Detecting Poor Ans
- Page 119: Classification - Detecting Poor Ans
- Page 123 and 124: Classification - Detecting Poor Ans
- Page 125 and 126: Classification - Detecting Poor Ans
- Page 127 and 128: Classification - Detecting Poor Ans
- Page 129 and 130: Classification - Detecting Poor Ans
- Page 132 and 133: Classification II - Sentiment Analy
- Page 134 and 135: Chapter 6 Getting to know the Bayes
- Page 136 and 137: Using Naive Bayes to classify Given
- Page 138 and 139: Chapter 6 This denotation "" leads
- Page 140 and 141: Chapter 6 Similarly, we do this for
- Page 142 and 143: Chapter 6 A quick look at the previ
- Page 144 and 145: Chapter 6 To keep our experimentati
- Page 146 and 147: Chapter 6 Y = np.zeros(Y.shape[0])
- Page 148 and 149: Chapter 6 ° ° Experiment with whe
- Page 150 and 151: Chapter 6 We have to be patient whe
- Page 152 and 153: Chapter 6 First, we define a range
- Page 154 and 155: Chapter 6 Determining the word type
- Page 156 and 157: Chapter 6 Successfully cheating usi
- Page 158 and 159: Chapter 6 Our first estimator Now w
- Page 160 and 161: Chapter 6 for d in documents: allca
- Page 162 and 163: Regression - Recommendations You ha
- Page 164 and 165: Chapter 7 The preceding graph shows
- Page 166 and 167: Chapter 7 Root mean squared error a
- Page 168 and 169: Penalized regression The important
- Page 170 and 171:
Chapter 7 P greater than N scenario
- Page 172 and 173:
Chapter 7 So, we can see that the d
- Page 174 and 175:
Chapter 7 Fortunately, scikit-learn
- Page 176 and 177:
[ 161 ] Chapter 7 The loading of th
- Page 178:
Chapter 7 Summary In this chapter,
- Page 181 and 182:
Regression - Recommendations Improv
- Page 183 and 184:
Regression - Recommendations Improv
- Page 185 and 186:
Weights Regression - Recommendation
- Page 187 and 188:
Regression - Recommendations Improv
- Page 189 and 190:
Regression - Recommendations Improv
- Page 191 and 192:
Regression - Recommendations Improv
- Page 193 and 194:
Regression - Recommendations Improv
- Page 196 and 197:
Classification III - Music Genre Cl
- Page 198 and 199:
Chapter 9 Matplotlib provides the c
- Page 200 and 201:
[ 185 ] Chapter 9
- Page 202 and 203:
Chapter 9 def create_fft(fn): sampl
- Page 204 and 205:
Chapter 9 ax.set_yticks(range(len(g
- Page 206 and 207:
Chapter 9 On the left-hand side gra
- Page 208 and 209:
[ 193 ] Chapter 9 Improving classif
- Page 210 and 211:
We get the following promising resu
- Page 212:
Chapter 9 Summary In this chapter,
- Page 215 and 216:
Computer Vision - Pattern Recogniti
- Page 217 and 218:
Computer Vision - Pattern Recogniti
- Page 219 and 220:
Computer Vision - Pattern Recogniti
- Page 221 and 222:
Computer Vision - Pattern Recogniti
- Page 223 and 224:
Computer Vision - Pattern Recogniti
- Page 225 and 226:
Computer Vision - Pattern Recogniti
- Page 227 and 228:
Computer Vision - Pattern Recogniti
- Page 229 and 230:
Computer Vision - Pattern Recogniti
- Page 231 and 232:
Computer Vision - Pattern Recogniti
- Page 233 and 234:
Computer Vision - Pattern Recogniti
- Page 235 and 236:
Computer Vision - Pattern Recogniti
- Page 237 and 238:
Dimensionality Reduction Sketching
- Page 239 and 240:
Dimensionality Reduction However, t
- Page 241 and 242:
Dimensionality Reduction To underst
- Page 243 and 244:
Dimensionality Reduction In order t
- Page 245 and 246:
Dimensionality Reduction Asking the
- Page 247 and 248:
Dimensionality Reduction n_ feature
- Page 249 and 250:
Dimensionality Reduction Sketching
- Page 251 and 252:
Dimensionality Reduction Limitation
- Page 253 and 254:
Dimensionality Reduction Now, MDS t
- Page 255 and 256:
Dimensionality Reduction Of course,
- Page 257 and 258:
Big(ger) Data • Your algorithms c
- Page 259 and 260:
Big(ger) Data sleep(4) return 2*x @
- Page 261 and 262:
Big(ger) Data Looking under the hoo
- Page 263 and 264:
Big(ger) Data def write_result(ofna
- Page 265 and 266:
Big(ger) Data Amazon Web Services i
- Page 267 and 268:
Big(ger) Data In EC2 parlance, a ru
- Page 269 and 270:
Big(ger) Data In this system, pip i
- Page 271 and 272:
Big(ger) Data Keys, keys, and more
- Page 273 and 274:
Big(ger) Data We can use the same j
- Page 276 and 277:
Where to Learn More about Machine L
- Page 278 and 279:
• Machined Learnings at http://ww
- Page 280 and 281:
Index A AcceptedAnswerId attribute
- Page 282 and 283:
F false negative 41 false positive
- Page 284 and 285:
inary matrix of recommendations, us
- Page 286:
sklearn.naive_bayes package 127 skl
- Page 289 and 290:
NumPy Beginner's Guide - Second Edi