

BI SEARCH AND TEXT ANALYTICS - The Data Warehousing Institute
BI SEARCH AND TEXT ANALYTICS - The Data Warehousing Institute
BI SEARCH AND TEXT ANALYTICS - The Data Warehousing Institute

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
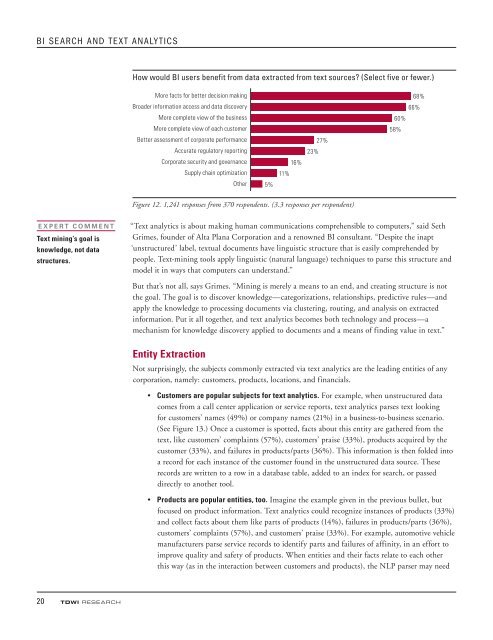
<strong>BI</strong> <strong>SEARCH</strong> <strong>AND</strong> <strong>TEXT</strong> <strong>ANALYTICS</strong>How would <strong>BI</strong> users benefit from data extracted from text sources? (Select five or fewer.)Figure 12. 1,241 responses from 370 respondents. (3.3 responses per respondent)EXPERT COMMENTText mining’s goal isknowledge, not datastructures.“Text analytics is about making human communications comprehensible to computers,” said SethGrimes, founder of Alta Plana Corporation and a renowned <strong>BI</strong> consultant. “Despite the inapt‘unstructured’ label, textual documents have linguistic structure that is easily comprehended bypeople. Text-mining tools apply linguistic (natural language) techniques to parse this structure andmodel it in ways that computers can understand.”But that’s not all, says Grimes. “Mining is merely a means to an end, and creating structure is notthe goal. <strong>The</strong> goal is to discover knowledge—categorizations, relationships, predictive rules—andapply the knowledge to processing documents via clustering, routing, and analysis on extractedinformation. Put it all together, and text analytics becomes both technology and process—amechanism for knowledge discovery applied to documents and a means of finding value in text.”Entity ExtractionNot surprisingly, the subjects commonly extracted via text analytics are the leading entities of anycorporation, namely: customers, products, locations, and financials.• Customers are popular subjects for text analytics. For example, when unstructured datacomes from a call center application or service reports, text analytics parses text lookingfor customers’ names (49%) or company names (21%) in a business-to-business scenario.(See Figure 13.) Once a customer is spotted, facts about this entity are gathered from thetext, like customers’ complaints (57%), customers’ praise (33%), products acquired by thecustomer (33%), and failures in products/parts (36%). This information is then folded intoa record for each instance of the customer found in the unstructured data source. <strong>The</strong>serecords are written to a row in a database table, added to an index for search, or passeddirectly to another tool.• Products are popular entities, too. Imagine the example given in the previous bullet, butfocused on product information. Text analytics could recognize instances of products (33%)and collect facts about them like parts of products (14%), failures in products/parts (36%),customers’ complaints (57%), and customers’ praise (33%). For example, automotive vehiclemanufacturers parse service records to identify parts and failures of affinity, in an effort toimprove quality and safety of products. When entities and their facts relate to each otherthis way (as in the interaction between customers and products), the NLP parser may need20 TDWI RE<strong>SEARCH</strong>











![Ink Jet Formulation- The Art of Color Chemistry 2005 [Read-Only]](https://img.yumpu.com/42062450/1/190x143/ink-jet-formulation-the-art-of-color-chemistry-2005-read-only.jpg?quality=85)
