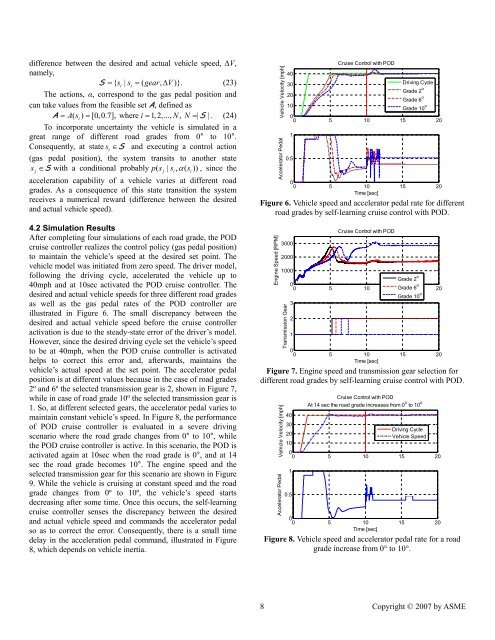
difference between the desired <strong>and</strong> actual vehicle speed, ∆V,namely,S = { si| si= ( gear, ∆V)}.(23)The actions, α, correspond to the gas pedal position <strong>and</strong>can take values from the feasible set A, defined asA = As (i) = [0,0.7], where i= 1, 2,..., N, N=| S | . (24)To incorporate uncertainty the vehicle is simulated in agreat range of different road grades from 0° to 10°.Consequently, at state s i∈S <strong>and</strong> executing a control action(gas pedal position), the system transits to another statesj∈S with a conditional probably ps (j| si, α ( si)), since theacceleration capability of a vehicle varies at different roadgrades. As a consequence of this state transition the systemreceives a numerical reward (difference between the desired<strong>and</strong> actual vehicle speed).4.2 Simulation ResultsAfter completing four simulations of each road grade, the PODcruise controller realizes the control policy (gas pedal position)to maintain the vehicle’s speed at the desired set point. Thevehicle model was initiated from zero speed. The driver model,following the driving cycle, accelerated the vehicle up to40mph <strong>and</strong> at 10sec activated the POD cruise controller. Thedesired <strong>and</strong> actual vehicle speeds <strong>for</strong> three different road gradesas well as the gas pedal rates of the POD controller areillustrated in Figure 6. The small discrepancy between thedesired <strong>and</strong> actual vehicle speed be<strong>for</strong>e the cruise controlleractivation is due to the steady-state error of the driver’s model.However, since the desired driving cycle set the vehicle’s speedto be at 40mph, when the POD cruise controller is activatedhelps to correct this error <strong>and</strong>, afterwards, maintains thevehicle’s actual speed at the set point. The accelerator pedalposition is at different values because in the case of road grades2º <strong>and</strong> 6º the selected transmission gear is 2, shown in Figure 7,while in case of road grade 10º the selected transmission gear is1. So, at different selected gears, the accelerator pedal varies tomaintain constant vehicle’s speed. In Figure 8, the per<strong>for</strong>manceof POD cruise controller is evaluated in a severe drivingscenario where the road grade changes from 0° to 10°, whilethe POD cruise controller is active. In this scenario, the POD isactivated again at 10sec when the road grade is 0°, <strong>and</strong> at 14sec the road grade becomes 10°. The engine speed <strong>and</strong> theselected transmission gear <strong>for</strong> this scenario are shown in Figure9. While the vehicle is cruising at constant speed <strong>and</strong> the roadgrade changes from 0º to 10º, the vehicle’s speed startsdecreasing after some time. Once this occurs, the self-learningcruise controller senses the discrepancy between the desired<strong>and</strong> actual vehicle speed <strong>and</strong> comm<strong>and</strong>s the accelerator pedalso as to correct the error. Consequently, there is a small timedelay in the acceleration pedal comm<strong>and</strong>, illustrated in Figure8, which depends on vehicle inertia.Vehicle Velocity [mph]Accelerator PedalCruise Control with POD4030Driving Cycle20Grade 2 oGrade 6 o10Grade 10 o00 5 10 15 2010.500 5 10 15 20Time [sec]Figure 6. Vehicle speed <strong>and</strong> accelerator pedal rate <strong>for</strong> differentroad grades by self-learning cruise control with POD.Engine Speed [RPM]30002000Cruise Control with POD1000Grade 2 o00 5 10 Grade 15 6 o 20Grade 10 o3Transmission Gear2100 5 10 15 20Time [sec]Figure 7. Engine speed <strong>and</strong> transmission gear selection <strong>for</strong>different road grades by self-learning cruise control with POD.Vehicle Velocity [mph]Accelerator PedalCruise Control with PODAt 14 sec the road grade increases from 0 o to 10 o4030Driving Cycle20Vehicle Speed1000 5 10 15 2010.500 5 10 15 20Time [sec]Figure 8. Vehicle speed <strong>and</strong> accelerator pedal rate <strong>for</strong> a roadgrade increase from 0° to 10°.8 Copyright © 2007 by ASME
Engine Speed [RPM]300020001000Transmission GearCruise Control with PODAt 14 sec the road grade increases from 0 o to 10 o00 5 10 15 2032100 5 10 15 20Time [sec]Figure 9. Engine speed <strong>and</strong> transmission gear selection <strong>for</strong> aroad grade increase from 0° to 10°.5. CONCLUDING REMARKSThis paper has presented a real-time learning method,consisting of a new state-space representation model <strong>and</strong> alearning algorithm, suited to solve sequential decision-makingproblems under uncertainty in real time. The method aims tobuild autonomous engineering systems that can learn toimprove their per<strong>for</strong>mance over time in stochasticenvironments. Such systems must be able to sense theirenvironments, estimate the consequences of their actions, <strong>and</strong>learn in real time the course of action (control policy) thatoptimizes a specified objective. The major difference betweenthe POD learning method presented in this paper <strong>and</strong> theexisting rein<strong>for</strong>cement learning methods is that the firstemploys an evaluation function which does not requirerecursive iterations to approximate the Bellman equation. Thisapproach has been shown to be especially appealing to systemsin which the initial state is not fixed, <strong>and</strong> recursive updates ofthe evaluation functions to approximate the Bellman equationwould dem<strong>and</strong> significant amount of experience to achieve thedesired system per<strong>for</strong>mance.The overall per<strong>for</strong>mance of the POD method in deriving anoptimal control policy was evaluated by its application to twoexamples: (a) the cart-pole balancing problem, <strong>and</strong> (b) a realtimevehicle cruise-controller development. In the firstproblem, POD realized the balancing control policy <strong>for</strong> aninverted pendulum when the pendulum was released from anyangle between 3° <strong>and</strong> -3°. In implementing the real-time cruisecontroller, the POD was able to maintain the desired vehicle’sspeed at any road grade between 0° <strong>and</strong> 10°. Future researchshould investigate the potential of advancing the POD methodto accommodate more than one decision maker in sequentialdecision-making problems under uncertainty, known as multiagentsystems [39]. These problems are found in systems inwhich many intelligent decision makers (agents) interact witheach other. The agents are considered to be autonomousentities. Their interactions can be either cooperative or selfish,i.e., the agents can share a common goal, e.g., control ofvehicles operating in platoons to improve throughput oncongested highways by allowing groups of vehicles to traveltogether in a tightly spaced platoon at high speeds.Alternatively, the agents can pursue their own interests.ACKNOWLEDGMENTSThis research was partially supported by the AutomotiveResearch Center (ARC), a U.S. Army Center of Excellence in<strong>Model</strong>ing <strong>and</strong> Simulation of Ground Vehicles at the Universityof Michigan. The engine simulation package enDYNA wasprovided by TESIS DYNAware GmbH. This support isgratefully acknowledged.REFERENCES[1] Bertsekas, D. P. <strong>and</strong> Shreve, S. E., Stochastic OptimalControl: The Discrete-Time Case, 1st edition, AthenaScientific, February 2007.[2] Gosavi, A., "Rein<strong>for</strong>cement <strong>Learning</strong> <strong>for</strong> Long-RunAverage Cost," European Journal of OperationalResearch, vol. 155, pp. 654-74, 2004.[3] Bertsekas, D. P. <strong>and</strong> Tsitsiklis, J. N., Neuro-DynamicProgramming (Optimization <strong>and</strong> Neural ComputationSeries, 3), 1st edition, Athena Scientific, May 1996.[4] Sutton, R. S. <strong>and</strong> Barto, A. G., Rein<strong>for</strong>cement <strong>Learning</strong>:An Introduction (Adaptive Computation <strong>and</strong> Machine<strong>Learning</strong>), The MIT Press, March 1998.[5] Borkar, V. S., "A <strong>Learning</strong> <strong>Algorithm</strong> <strong>for</strong> Discrete-TimeStochastic Control," Probability in the Engineering <strong>and</strong>In<strong>for</strong>mation Sciences, vol. 14, pp. 243-258, 2000.[6] Samuel, A. L., "Some Studies in Machine <strong>Learning</strong> Usingthe Game of Checkers," IBM Journal of Research <strong>and</strong>Development, vol. 3, pp. 210-229, 1959.[7] Samuel, A. L., "Some Studies in Machine <strong>Learning</strong> Usingthe Game of Checkers. II -Recent progress," IBM Journalof Research <strong>and</strong> Development, vol. 11, pp. 601-617, 1967.[8] Sutton, R. S., Temporal Credit Assignment inRein<strong>for</strong>cement <strong>Learning</strong>, PhD Thesis, University ofMassachusetts, Amherst, MA, 1984.[9] Sutton, R. S., "<strong>Learning</strong> to Predict by the Methods ofTemporal Difference," Machine <strong>Learning</strong>, vol. 3, pp. 9-44, 1988.[10] Watkins, C. J., <strong>Learning</strong> from Delayed Rewards, PhDThesis, Kings College, Cambridge, Engl<strong>and</strong>, May 1989.[11] Watkins, C. J. C. H. <strong>and</strong> Dayan, P., "Q-learning," Machine<strong>Learning</strong>, vol. 8, pp. 279-92, 1992.[12] Kaelbling, L. P., Littman, M. L., <strong>and</strong> Moore, A. W.,"Rein<strong>for</strong>cement <strong>Learning</strong>: A Survey," Journal of ArtificialIntelligence Research, vol. 4.[13] Schwartz, A., "A Rein<strong>for</strong>cement <strong>Learning</strong> Method <strong>for</strong>Maximizing Undiscounted Rewards," Proceedings of theTenth International Conference on Machine <strong>Learning</strong>, pp.298-305, Amherst, Massachusetts, 1993,[14] Mahadevan, S., "Average Reward Rein<strong>for</strong>cement<strong>Learning</strong>: Foundations, <strong>Algorithm</strong>s, <strong>and</strong> EmpiricalResults," Machine <strong>Learning</strong>, vol. 22, pp. 159-195, 1996.9 Copyright © 2007 by ASME