

RECENT DEVELOPMENT IN COMPUTATIONAL SCIENCE
RECENT DEVELOPMENT IN COMPUTATIONAL SCIENCE
RECENT DEVELOPMENT IN COMPUTATIONAL SCIENCE

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
ISCS 2011 Selected Papers Vol.2 Time Benchmarks for the OpenMP and GPU<br />
Elapsed time (sec)<br />
5<br />
4<br />
3<br />
2<br />
1<br />
FFTW<br />
CUFFT(DOUBLE)<br />
CUFFT(S<strong>IN</strong>GLE)<br />
0.02<br />
0.01<br />
0<br />
0 50 100<br />
0<br />
0 100 200 300 400<br />
Transform Size (N^3)<br />
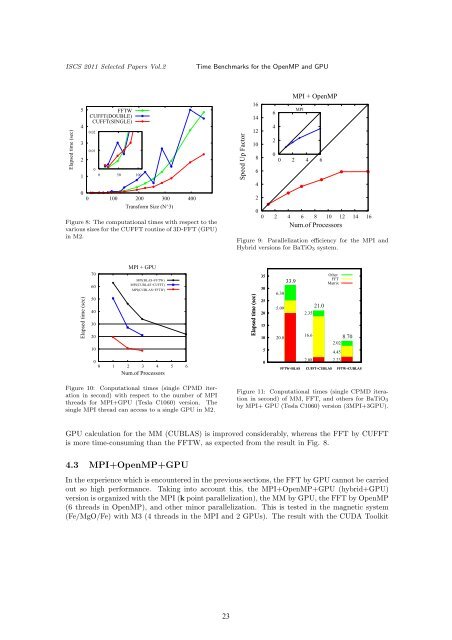
Figure 8: The computational times with respect to the<br />
various sizes for the CUFFT routine of 3D-FFT (GPU)<br />
in M2.<br />
Elapsed time (sec)<br />
70<br />
60<br />
50<br />
40<br />
30<br />
20<br />
10<br />
MPI + GPU<br />
MPI(BLAS+FFTW)<br />
MPI(CUBLAS+CUFFT)<br />
MPI(CUBLAS+FFTW)<br />
0<br />
0 1 2 3 4 5 6<br />
Num.of Processors<br />
Figure 10: Conputational times (single CPMD iteration<br />
in second) with respect to the number of MPI<br />
threads for MPI+GPU (Tesla C1060) version. The<br />
single MPI thread can access to a single GPU in M2.<br />
Speed Up Factor<br />
16<br />
14<br />
12<br />
10<br />
8<br />
6<br />
4<br />
2<br />
6<br />
4<br />
2<br />
MPI + OpenMP<br />
MPI<br />
0<br />
0 2 4 6<br />
0<br />
0 2 4 6 8 10 12 14 16<br />
Num.of Processors<br />
Figure 9: Parallelization efficiency for the MPI and<br />
Hybrid versions for BaTiO3 system.<br />
Elapsed time (sec)<br />
35<br />
30<br />
25<br />
20<br />
15<br />
10<br />
5<br />
0<br />
6.30<br />
5.09<br />
20.0<br />
33.9<br />
2.35<br />
16.6<br />
2.08<br />
21.0<br />
Other<br />
FFT<br />
Matrix<br />
8.70<br />
2.02<br />
4.45<br />
2.23<br />
FFTW+BLAS CUFFT+CUBLAS FFTW+CUBLAS<br />
Figure 11: Conputational times (single CPMD iteration<br />
in second) of MM, FFT, and others for BaTiO3<br />
by MPI+ GPU (Tesla C1060) version (3MPI+3GPU).<br />
GPU calculation for the MM (CUBLAS) is improved considerably, whereas the FFT by CUFFT<br />
is more time-consuming than the FFTW, as expected from the result in Fig. 8.<br />
4.3 MPI+OpenMP+GPU<br />
In the experience which is encountered in the previous sections, the FFT by GPU cannot be carried<br />
out so high performance. Taking into account this, the MPI+OpenMP+GPU (hybrid+GPU)<br />
version is organized with the MPI (k point parallelization), the MM by GPU, the FFT by OpenMP<br />
(6 threads in OpenMP), and other minor parallelization. This is tested in the magnetic system<br />
(Fe/MgO/Fe) with M3 (4 threads in the MPI and 2 GPUs). The result with the CUDA Toolkit<br />
23