Procesadores Gráficos y Aplicaciones en Tiempo Real ... - DAC
Procesadores Gráficos y Aplicaciones en Tiempo Real ... - DAC
Procesadores Gráficos y Aplicaciones en Tiempo Real ... - DAC

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
TEMA 1.2<br />
MODELOS DE<br />
PROGRAMACIÓN<br />
PARALELA Y ESTRATEGIAS<br />
DE DISEÑO<br />
Curso 2012 / 13<br />
<strong>Procesadores</strong> <strong>Gráficos</strong> y <strong>Aplicaciones</strong> <strong>en</strong> <strong>Tiempo</strong> <strong>Real</strong><br />
Profesores: David Miraut y Óscar D. Robles<br />
Material adaptado del curso de José Luís Bosque y Óscar D. Robles<br />
c○GMRV 2005-2013 – Enero 2013<br />
1<br />
/40<br />
c○GMRV 2013 <strong>Procesadores</strong> <strong>Gráficos</strong> y <strong>Aplicaciones</strong> <strong>en</strong> <strong>Tiempo</strong> <strong>Real</strong> 2012/13 1/40
¿Qué es la computación paralela?<br />
• Tradicionalm<strong>en</strong>te, el software se ha escrito para computación<br />
serie (o secu<strong>en</strong>cial):<br />
◦ Para su ejecución <strong>en</strong> un único computador con una sola CPU.<br />
◦ Un problema se descompone <strong>en</strong> una serie determinada de<br />
instrucciones.<br />
◦ Las instrucciones se ejecutan una tras otra.<br />
◦ Solam<strong>en</strong>te una instrucción se puede ejecutar <strong>en</strong> cada instante <strong>en</strong><br />
el tiempo.<br />
2<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Introducción 2/40
¿Qué es la computación paralela?<br />
• En el caso más simple, la computación paralela es el uso<br />
simultáneo de múltiples recursos para resolver un problema<br />
computacional:<br />
◦ Para su ejecución <strong>en</strong> múltiples CPUs.<br />
◦ Un problema se descompone <strong>en</strong> partes discretas que se pued<strong>en</strong><br />
resolver de forma concurr<strong>en</strong>te.<br />
◦ Cada parte se puede descomponer <strong>en</strong> series de instrucciones.<br />
◦ Las instrucciones de cada parte se ejecutan de forma simultánea<br />
<strong>en</strong> difer<strong>en</strong>tes CPUs.<br />
3<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Introducción 3/40
¿Qué es la computación paralela?<br />
La computación paralela<br />
es una forma efectiva de procesar información que favorece la<br />
explotación de ev<strong>en</strong>tos concurr<strong>en</strong>tes durante el proceso de<br />
computación<br />
• Los recursos computacionales deberían ser “computadores<br />
paralelos”.<br />
• En cuanto al problema computacional a resolver se debería<br />
poder:<br />
◦ Descomponerlo <strong>en</strong> partes discretas de trabajo que se puedan<br />
resolver simultáneam<strong>en</strong>te, aunque puedan cooperar y<br />
coordinarse para alcanzar un objetivo común.<br />
◦ Ejecutar múltiples instrucciones <strong>en</strong> cada instante <strong>en</strong> el tiempo.<br />
◦ Resolverlo con múltiples recursos computacionales <strong>en</strong> m<strong>en</strong>os<br />
tiempo que <strong>en</strong> un único recurso computacional.<br />
4<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Introducción 4/40
¿Por qué utilizar computación paralela?<br />
• Ahorrar tiempo y/o dinero<br />
◦ Utilizar más recursos <strong>en</strong> una tarea acorta el tiempo necesario<br />
para completarla, lo que pot<strong>en</strong>cialm<strong>en</strong>te ahorra costes.<br />
◦ Los computadores paralelos se pued<strong>en</strong> construir a partir de<br />
compon<strong>en</strong>tes baratos y comunes.<br />
• Resolver problemas más grandes:<br />
◦ Muchos problemas son tan grandes y/o complejos que es poco<br />
práctico o incluso imposible resolverlos <strong>en</strong> un único computador.<br />
• Utilizar recursos no locales:<br />
◦ Utilizar recursos de una red de área ext<strong>en</strong>sa o incluso de<br />
Internet cuando los recursos locales son escasos: computación<br />
<strong>en</strong> grid o <strong>en</strong> la nube.<br />
• Límites de la computación secu<strong>en</strong>cial: exist<strong>en</strong> restricciones<br />
tanto de índole práctica como física que impid<strong>en</strong> construir<br />
computadores secu<strong>en</strong>ciales más rápidos y pot<strong>en</strong>tes.<br />
5<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Introducción 5/40
Uso de la computación paralela<br />
• Históricam<strong>en</strong>te, la computación paralela se ha utilizado para<br />
resolver problemas de gran dificultad <strong>en</strong> diversas áreas de la<br />
ci<strong>en</strong>cia y la ing<strong>en</strong>iería:<br />
◦ Meteorología, Medio ambi<strong>en</strong>te, la Tierra.<br />
◦ Física aplicada, nuclear, de partículas, fusión, fotónica, alta<br />
presión.<br />
◦ Ing<strong>en</strong>iería mecánica, desde prótesis a naves espaciales.<br />
◦ Ing<strong>en</strong>iería eléctrica, diseño de circuitos, microelectrónica.<br />
• Bioci<strong>en</strong>cia, biotecnología,<br />
g<strong>en</strong>ética.<br />
• Química, ci<strong>en</strong>cia molecular.<br />
• Geología, sismología.<br />
• Informática, Matemáticas.<br />
6<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Introducción 6/40
Uso de la computación paralela<br />
• Actualm<strong>en</strong>te, difer<strong>en</strong>tes aplicaciones comerciales requier<strong>en</strong><br />
procesar grandes cantidades de datos de formas sofisticadas.<br />
• Bases de datos, minería de datos, motores de búsqueda web,<br />
servicios comerciales basados <strong>en</strong> web.<br />
• Modelizado económico y financiero, exploración petrolífera.<br />
• Diagnóstico por imag<strong>en</strong> médica, diseño farmacéutico.<br />
• Gestión de corporaciones nacionales y multinacionales.<br />
• Tecnologías multimedia, vídeo <strong>en</strong> red, gráficos avanzados y<br />
realidad virtual.<br />
7<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Introducción 7/40
¿Quién usa la computación paralela?<br />
www.top500.org<br />
8<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Introducción 8/40
¿Quién usa la computación paralela?<br />
9<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Introducción 9/40
Modelos de programación paralela<br />
• Idealizan las características que necesita un desarrollador para<br />
escribir programas paralelos efici<strong>en</strong>tes.<br />
• Abstraer por <strong>en</strong>cima de las arquitecturas de memoria y de<br />
hardware.<br />
• Exist<strong>en</strong> difer<strong>en</strong>tes modelos de programación paralela de uso<br />
común:<br />
• Memoria compartida: Threads.<br />
• Memoria distribuida / Paso de m<strong>en</strong>sajes.<br />
• Datos paralelos<br />
• Híbrido<br />
• SPMD<br />
• MDMD<br />
10<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Modelos de programación paralela 10/40
Modelo de memoria compartida<br />
• Modelo de multiprocesador ideal<br />
◦ Computador paralelo consist<strong>en</strong>te <strong>en</strong> “p” procesadores idénticos.<br />
◦ Compart<strong>en</strong> un único espacio/mapa de memoria.<br />
◦ <strong>Tiempo</strong> de acceso constante a cualquier dirección de memoria.<br />
◦ Ejecución síncrona<br />
11<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Modelos de programación paralela 11/40
Modelo de memoria compartida<br />
• En este modelo de programación, la tareas compart<strong>en</strong> un<br />
único espacio de direcciones, <strong>en</strong> el que las tareas le<strong>en</strong> y<br />
escrib<strong>en</strong> de forma asíncrona.<br />
• Cuando el programa comi<strong>en</strong>za, tanto los datos como las<br />
instrucciones están <strong>en</strong> memoria.<br />
• Todos los procesadores corr<strong>en</strong> el mismo programa ejecutable:<br />
◦ Particularizado de acuerdo a los índices.<br />
◦ Conjunto de datos con “<strong>en</strong>voltorio” difer<strong>en</strong>ciado.<br />
• La comunicación <strong>en</strong>tre procesadores se realiza modificando<br />
variables <strong>en</strong> la memoria compartida.<br />
• Reglas para acceder a variables compartidas:<br />
◦ Dos procesadores pued<strong>en</strong> acceder simultáneam<strong>en</strong>te a una<br />
variable compartida <strong>en</strong> modo sólo lectura<br />
◦ Si un procesador trata de modificar (escribir) una variable,<br />
ningún otro procesador puede acceder a ella hasta que se ha<br />
completado la modificación.<br />
12<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Modelos de programación paralela 12/40
Modelo de threads<br />
• En el modelo de programación paralela basado <strong>en</strong> threads, un<br />
proceso puede t<strong>en</strong>er múltiples caminos de ejecución<br />
concurr<strong>en</strong>te.<br />
• Un thread o hilo de ejecución es la unidad de ejecución más<br />
pequeña que puede planificar un sistema operativo.<br />
• D<strong>en</strong>tro de un mismo proceso pued<strong>en</strong> existir múltiples hilos y<br />
compartir recursos, mi<strong>en</strong>tras que procesos difer<strong>en</strong>tes no<br />
compart<strong>en</strong> nada.<br />
◦ Los hilos de un proceso<br />
compart<strong>en</strong>:<br />
• El código de programa.<br />
• El contexto y la memoria global.<br />
• Los ficheros abiertos.<br />
◦ Cada hilo ti<strong>en</strong>e <strong>en</strong> propiedad<br />
• La pila<br />
• Los valores de los registros,<br />
incluy<strong>en</strong>do el PC.<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Modelos de programación paralela<br />
13<br />
/40<br />
13/40
Modelo de threads<br />
• ¿Cómo funcionan los threads?<br />
◦ El programa principal realiza trabajo secu<strong>en</strong>cial y crea un cierto<br />
número de hilos que se pued<strong>en</strong> ejecutar de forma concurr<strong>en</strong>te.<br />
◦ Cada hilo ti<strong>en</strong>e sus datos locales y comparte los recursos del<br />
programa principal.<br />
◦ La comunicación se hace a través de la memoria global.<br />
◦ Se requier<strong>en</strong>, por tanto, mecanismos de sincronización (cerrojos,<br />
semáforos, . . . ) para controlad el acceso a la memoria<br />
compartida: exclusión mutua.<br />
◦ Se pued<strong>en</strong> crear y destruir hilos durante la ejecución.<br />
14<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Modelos de programación paralela 14/40
Modelo de paso de m<strong>en</strong>sajes<br />
• Modelo de computador de memoria distribuida<br />
◦ Computador paralelo consist<strong>en</strong>te <strong>en</strong> p procesadores (0...p − 1).<br />
◦ Cada uno ti<strong>en</strong>e su propio espacio de direcciones de memoria:<br />
memoria local.<br />
◦ <strong>Tiempo</strong> de acceso constante a la memoria local.<br />
◦ La comunicación <strong>en</strong>tre cualquier par de nodos se realiza a través<br />
de una red de interconexión.<br />
◦ Ejecución asíncrona.<br />
15<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Modelos de programación paralela 15/40
Modelo de paso de m<strong>en</strong>sajes<br />
• Programa: conjunto de tareas indep<strong>en</strong>di<strong>en</strong>tes que utilizan su<br />
propia memoria local durante el cómputo.<br />
• Múltiples tareas pued<strong>en</strong> residir <strong>en</strong> la misma máquina física y/o<br />
<strong>en</strong> un número arbitrario de máquinas.<br />
• Las tareas intercambian datos a través de comunicaciones<br />
explícitas mediante el <strong>en</strong>vío y la recepción de m<strong>en</strong>sajes.<br />
16<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Modelos de programación paralela 16/40
Modelo de paso de m<strong>en</strong>sajes<br />
• Cuando comi<strong>en</strong>za el programa el código es accesible para<br />
todos los procesadores.<br />
• Todos los procesadores ejecutan el mismo código:<br />
◦ Se particulariza <strong>en</strong> función de un índice.<br />
◦ Conjunto de datos separados.<br />
• Dos tipos de instrucciones:<br />
◦ Instrucciones locales: se ejecutan sobre los datos del procesador.<br />
◦ Comunicación de usuario: información intercambiada mediante<br />
<strong>en</strong>vío de m<strong>en</strong>sajes.<br />
• Un programa consiste <strong>en</strong> una sucesión de instrucciones locales<br />
y directivas de comunicación.<br />
◦ Comunicaciones y cómputo son solapables.<br />
• MPI: Message Passing Interface: www.mpi-forum.org<br />
17<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Modelos de programación paralela 17/40
Modelo de paso de m<strong>en</strong>sajes<br />
Punto-punto: <strong>en</strong>vío y recepción de datos <strong>en</strong>tre dos procesadores.<br />
18<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Modelos de programación paralela 18/40
Modelo de datos paralelos<br />
• Un conjunto de tareas trabajan colectivam<strong>en</strong>te <strong>en</strong> la misma<br />
estructura de datos:<br />
◦ Sin embargo, cada tarea trabaja sobre una partición difer<strong>en</strong>te de<br />
la estructura de datos.<br />
• Las tareas realizan la misma<br />
operación, cada una sobre su<br />
partición.<br />
• En arquitecturas de memoria<br />
compartida, todas las tareas<br />
acced<strong>en</strong> a los datos a través de<br />
la memoria global.<br />
• En arquitecturas de memoria<br />
distribuida los datos se part<strong>en</strong> y<br />
cada trozo reside <strong>en</strong> la memoria<br />
local de la tarea.<br />
19<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Modelos de programación paralela 19/40
Modelo híbrido<br />
• Combinación de algunos de los modelos descritos previam<strong>en</strong>te.<br />
• Modelo de paso de m<strong>en</strong>sajes (MPI) con el modelo de threads<br />
(Op<strong>en</strong>MP)<br />
◦ Los hilos implem<strong>en</strong>tan kernels computacionalm<strong>en</strong>te int<strong>en</strong>sos<br />
utilizando datos locales situados <strong>en</strong> los nodos.<br />
◦ La comunicación <strong>en</strong>tre procesos situados <strong>en</strong> difer<strong>en</strong>tes nodos se<br />
realiza a través de la red utilizando MPI.<br />
• Programación con GPUs y MPI.<br />
◦ Las GPUs implem<strong>en</strong>tan kernels computacionalm<strong>en</strong>te int<strong>en</strong>sos<br />
utilizando datos locales situados <strong>en</strong> ellas.<br />
◦ La comunicación <strong>en</strong>tre procesos situados <strong>en</strong> difer<strong>en</strong>tes nodos se<br />
realiza a través de la red utilizando MPI.<br />
20<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Modelos de programación paralela 20/40
Compr<strong>en</strong>der el problema y el programa<br />
• Primer paso: compr<strong>en</strong>der el problema que se quiere resolver <strong>en</strong><br />
paralelo.<br />
◦ Si se parte de un programa secu<strong>en</strong>cial, esto implica compr<strong>en</strong>der<br />
el código exist<strong>en</strong>te.<br />
• Antes de invertir tiempo <strong>en</strong> int<strong>en</strong>tar desarrollar una solución<br />
paralela a un problema, determinar si el problema se puede<br />
paralelizar o no.<br />
21<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Diseño de programas paralelos 21/40
Compr<strong>en</strong>der el problema y el programa<br />
• Id<strong>en</strong>tificar los puntos cali<strong>en</strong>tes del programa:<br />
◦ Saber dónde se realiza la mayor parte del trabajo.<br />
◦ Pued<strong>en</strong> ayudar las herrami<strong>en</strong>tas de análisis de r<strong>en</strong>dimi<strong>en</strong>to o los<br />
profilers<br />
◦ C<strong>en</strong>trarse <strong>en</strong> paralelizar los puntos cali<strong>en</strong>tes e ignorar aquellas<br />
secciones del programa que supon<strong>en</strong> poco uso de la CPU.<br />
• Id<strong>en</strong>tificar los cuellos de botella <strong>en</strong> el programa:<br />
◦ Parte del código que ral<strong>en</strong>tiza (o incluso convierte <strong>en</strong><br />
secu<strong>en</strong>cial) la ejecución del programa paralelo. Por ejemplo, las<br />
instrucciones de E/S.<br />
◦ Puede ser posible reestructurar el programa o utilizar un<br />
algoritmo difer<strong>en</strong>te para reducir o eliminar zonas<br />
innecesariam<strong>en</strong>te l<strong>en</strong>tas.<br />
• Id<strong>en</strong>tificar los inhibidores del paralelismo. Ejemplos típicos<br />
son las dep<strong>en</strong>d<strong>en</strong>cias de datos o las bifurcaciones.<br />
• Investigar algoritmos alternativos si es posible.<br />
22<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Diseño de programas paralelos 22/40
Partición<br />
• Uno de los primeros pasos <strong>en</strong> el diseño de un programa<br />
paralelo es su descomposición <strong>en</strong> “trozos” discretos de trabajo<br />
que se pued<strong>en</strong> distribuir <strong>en</strong> múltiples tareas. Esto se conoce<br />
como descomposición o partición.<br />
• Exist<strong>en</strong> dos formas básicas de hacer una partición<br />
computacional de trabajo <strong>en</strong>tre tareas paralelas:<br />
◦ Descomposición <strong>en</strong> función del dominio.<br />
◦ Descomposición funcional.<br />
• La combinación de ambos tipos de descomposición de un<br />
problema es muy común y natural.<br />
23<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Diseño de programas paralelos 23/40
Partición<br />
• Descomposición <strong>en</strong> función del dominio:<br />
◦ Se descompon<strong>en</strong> los datos asociados a un problema.<br />
◦ Cada tarea paralela trabaja <strong>en</strong>tonces sobre una porción de los<br />
datos<br />
◦ Hay réplicas del mismo programa trabajando <strong>en</strong> porciones<br />
distintas de los datos.<br />
◦ El control puede ser c<strong>en</strong>tralizado o distribuido.<br />
◦ El grado de paralelismo es muy alto, pero no aparece <strong>en</strong> todas<br />
las aplicaciones.<br />
24<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Diseño de programas paralelos 24/40
Partición<br />
• Descomposición funcional:<br />
◦ Se descompone el problema de acuerdo al trabajo a realizar.<br />
◦ Cada tarea realiza una parte del trabajo total.<br />
◦ G<strong>en</strong>eralm<strong>en</strong>te cada tarea ti<strong>en</strong>e un nivel de paralelismo bajo.<br />
◦ Inher<strong>en</strong>te a todas las aplicaciones.<br />
25<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Diseño de programas paralelos 25/40
Comunicaciones<br />
• Algunos tipos de problemas se pued<strong>en</strong> descomponer y ejecutar<br />
<strong>en</strong> paralelo sin que virtualm<strong>en</strong>te las tareas necesit<strong>en</strong> compartir<br />
datos: embarrassingly parallel<br />
• Coste de las comunicaciones<br />
◦ Las comunicaciones <strong>en</strong>tre tareas siempre supon<strong>en</strong> una<br />
sobrecarga.<br />
◦ Las comunicaciones requier<strong>en</strong> da algún tipo de sincronización<br />
<strong>en</strong>tre tareas, lo que puede suponer que haya tareas que pierd<strong>en</strong><br />
tiempo esperando <strong>en</strong> lugar de haci<strong>en</strong>do trabajo activo.<br />
• Comunicaciones síncronas vs. asíncronas<br />
◦ Comunicaciones síncronas (o bloqueantes ): otra tarea debe<br />
esperar hasta que las comunicaciones se han completado.<br />
◦ Comunicaciones asíncronas (o no bloqueantes ): se pued<strong>en</strong><br />
realizar otros trabajos mi<strong>en</strong>tras las comunicaciones ti<strong>en</strong><strong>en</strong> lugar.<br />
◦ El gran b<strong>en</strong>eficio de utilizar comunicaciones asíncronas es<br />
intercalar comunicaciones y cómputo.<br />
26<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Diseño de programas paralelos 26/40
Comunicaciones<br />
• Lat<strong>en</strong>cia fr<strong>en</strong>te a ancho de banda<br />
◦ Lat<strong>en</strong>cia: tiempo de una comunicación mínima punto a punto.<br />
◦ Ancho de banda es la cantidad de información transmitida por<br />
unidad de tiempo.<br />
◦ El <strong>en</strong>vío de muchos m<strong>en</strong>sajes muy pequeños puede causar que la<br />
lat<strong>en</strong>cia sea determinante <strong>en</strong> la sobrecarga de comunicaciones.<br />
◦ Muchas veces es más efici<strong>en</strong>te empaquetar varios m<strong>en</strong>sajes pequeños<br />
<strong>en</strong> uno más grande, increm<strong>en</strong>tando de esta forma el ancho de banda<br />
efectivo de las comunicaciones.<br />
• Ámbito de las comunicaciones<br />
◦ Punto a punto: involucran a<br />
dos tareas; una actúa como<br />
emisora y otra como receptora.<br />
◦ Colectivas: conllevan la<br />
compartición de datos <strong>en</strong>tre<br />
más de dos tareas, que son<br />
miembros de un mismo grupo.<br />
27<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Diseño de programas paralelos 27/40
Sincronización<br />
• La sincronización es la aplicación de determinados mecanismos<br />
que aseguran que dos hilos que ejecutan de manera concurr<strong>en</strong>te no<br />
ejecutan a la vez partes específicas de un programa.<br />
• Si un hilo a com<strong>en</strong>zado la ejecución de una parte secu<strong>en</strong>cial<br />
(sección crítica), cualquier otro hilo debe esperar hasta que aquél<br />
ha terminado.<br />
• Barrera<br />
◦ Típicam<strong>en</strong>te implica que todas las tareas están involucradas.<br />
◦ Las tareas trabajan hasta que alcanzan la barrera. Entonces se paran<br />
o bloquean.<br />
◦ Cuando la última tarea alcanza la barrera, todas las tareas están<br />
sincronizadas.<br />
28<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Diseño de programas paralelos 28/40
Sincronización<br />
• Cerrojo / Semáforo<br />
◦ Puede implicar a cualquier número de tareas.<br />
◦ Típicam<strong>en</strong>te utilizado para hacer secu<strong>en</strong>cial el acceso a datos globales<br />
o a una sección de código.<br />
◦ Sólo una tarea <strong>en</strong> cada mom<strong>en</strong>to utiliza el cerrojo/semáforo/señal<br />
◦ La primera tarea que obti<strong>en</strong>e el cerrojo lo “marca”.<br />
◦ Dicha tarea puede <strong>en</strong>tonces acceder (secu<strong>en</strong>cialm<strong>en</strong>te) de forma<br />
segura al código o los datos protegidos.<br />
◦ El resto esperan hasta que la tarea que obtuvo el cerrojo lo libera.<br />
• Operaciones de comunicación síncronas<br />
◦ Cuando una tarea realizar una operación de comunicación, es<br />
necesaria alguna forma de coordinación con las otras tarea(s)<br />
implicada(s) <strong>en</strong> ella.<br />
29<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Diseño de programas paralelos 29/40
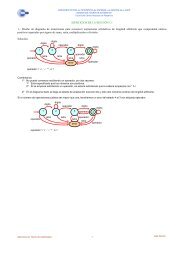
Dep<strong>en</strong>d<strong>en</strong>cias de datos<br />
• Existe una dep<strong>en</strong>d<strong>en</strong>cia <strong>en</strong>tre acciones realizadas <strong>en</strong> un<br />
programa cuando el ord<strong>en</strong> de ejecución de dichas acciones<br />
afecta al resultado del programa.<br />
• Si difer<strong>en</strong>tes tareas hac<strong>en</strong> uso múltiple de la(s) misma(s)<br />
dirección(es) de almac<strong>en</strong>ami<strong>en</strong>to aparece una dep<strong>en</strong>d<strong>en</strong>cia<br />
de datos<br />
• Las dep<strong>en</strong>d<strong>en</strong>cias son uno de los principales inhibidores del<br />
paralelismo.<br />
• Las dep<strong>en</strong>d<strong>en</strong>cias que se acarrean d<strong>en</strong>tro de los bucles son<br />
particularm<strong>en</strong>te importantes, dado que los bucles son<br />
posiblem<strong>en</strong>te uno de los principales objetivos de los trabajos de<br />
paralelización de un código.<br />
30<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Diseño de programas paralelos 30/40
Dep<strong>en</strong>d<strong>en</strong>cias de datos<br />
Esta transpar<strong>en</strong>cia me gustaría hacerla como Dios manda<br />
31<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Diseño de programas paralelos 31/40
Equilibrio de carga<br />
• El equilibrio de carga se refiere a la práctica de distribuir el<br />
trabajo <strong>en</strong>tre todas las tareas de forma que todas las tareas<br />
están ocupadas todo el tiempo<br />
• Se puede considerar como una minimización del tiempo que<br />
una tarea permanece ociosa.<br />
• El equilibrio de carga es importante <strong>en</strong> los programas paralelos<br />
por motivos relacionados con el r<strong>en</strong>dimi<strong>en</strong>to.<br />
Por ejemplo, si todas las tareas<br />
están sometidas a una barrera<br />
de sincronización, la tarea más<br />
l<strong>en</strong>ta determinará el r<strong>en</strong>dimi<strong>en</strong>to<br />
global.<br />
32<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Diseño de programas paralelos 32/40
Cómo alcanzar el equilibrio de carga<br />
• Partición equitativa del trabajo que recibe cada tarea<br />
◦ En el caso de operaciones sobre vectores o matrices <strong>en</strong> los que cada<br />
tarea realiza un trabajo similar, se pued<strong>en</strong> repartir los datos <strong>en</strong>tre las<br />
tareas de manera uniforme.<br />
◦ Cuando se trata de bucles <strong>en</strong> los que el trabajo realizado <strong>en</strong> cada<br />
iteración es similar, se pued<strong>en</strong> distribuir uniformem<strong>en</strong>te las iteraciones<br />
sobre las tareas.<br />
◦ En <strong>en</strong>tornos heterogéneos se deber realizar un análisis de r<strong>en</strong>dimi<strong>en</strong>to<br />
para detectar desequilibrios de carga de trabajo. Se podrán realizar<br />
ajustes de acuerdo a los resultados.<br />
• Asignación dinámica de trabajo<br />
◦ En algunos problemas aparec<strong>en</strong> desequilibrios de carga de trabajo<br />
incluso si se hace una distribución equitativa de los datos.<br />
◦ Cuando la carga de trabajo que realizará cada tarea es variable o<br />
impredecible, puede ser útil un <strong>en</strong>foque basado <strong>en</strong> un planificador<br />
• Cuando una tarea completa su carga de trabajo asignada, queda <strong>en</strong>colada para<br />
obt<strong>en</strong>er un nuevo paquete de trabajo.<br />
◦ Puede llegar a ser necesario diseñar un algoritmo que detecte y<br />
gestione desequilibrios locales según van apareci<strong>en</strong>do de forma<br />
dinámica <strong>en</strong> el código.<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Diseño de programas paralelos<br />
33<br />
/40<br />
33/40
Tamaño de grano (granularidad)<br />
• Ratio computación/comunicación<br />
◦ El tamaño de grano es una medida de la ratio<br />
computación/comunicación.<br />
◦ Los períodos de computación y los de comunicación están<br />
g<strong>en</strong>eralm<strong>en</strong>te separados por ev<strong>en</strong>tos de sincronización.<br />
• Paralelismo de grano fino<br />
◦ Pequeñas cantidades de cómputo <strong>en</strong>tre ev<strong>en</strong>tos de<br />
comunicación.<br />
◦ Baja ratio computación/comunicación y elevada sobrecarga de<br />
comunicaciones.<br />
◦ Facilita el equilibrio de carga.<br />
• Paralelismo de grano grueso<br />
◦ Gran cantidad de cómputo <strong>en</strong>tre ev<strong>en</strong>tos de comunicación.<br />
◦ Elevada ratio computación/comunicación.<br />
◦ Supone una mayor oportunidad de mejorar el r<strong>en</strong>dimi<strong>en</strong>to.<br />
◦ Más difícil de conseguir efici<strong>en</strong>tem<strong>en</strong>te un equilibrio de carga.<br />
34<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Diseño de programas paralelos 34/40
Métricas de r<strong>en</strong>dimi<strong>en</strong>to<br />
• Objetivo del paralelismo: mejorar el r<strong>en</strong>dimi<strong>en</strong>to de los<br />
programas<br />
◦ Elapsed time: tiempo transcurrido desde que comi<strong>en</strong>za la<br />
ejecución de la tarea hasta que se completa.<br />
◦ <strong>Tiempo</strong> de CPU: tiempo durante el que la tarea ejecuta <strong>en</strong> el<br />
procesador (no incluye E/S o tiempos de espera)<br />
• <strong>Tiempo</strong> de usuario: tiempo invertido <strong>en</strong> el programa <strong>en</strong> modo<br />
usuario.<br />
• <strong>Tiempo</strong> de sistema: tiempo invertido <strong>en</strong> el programa <strong>en</strong> modo<br />
kernel. La CPU ejecuta tareas del SO<br />
◦ <strong>Tiempo</strong> de comunicaciones: tiempo empleado por la aplicación<br />
<strong>en</strong> operaciones de comunicación.<br />
◦ Sobrecarga: tiempo total <strong>en</strong> el que la aplicación paralela no<br />
hace trabajo útil.<br />
35<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Métricas de r<strong>en</strong>dimi<strong>en</strong>to 35/40
Métricas de r<strong>en</strong>dimi<strong>en</strong>to<br />
• Speedup: ganancia del sistema paralelo, <strong>en</strong> oposición al<br />
secu<strong>en</strong>cial.<br />
Speedup = Tsecu<strong>en</strong>cial<br />
Tparalelo<br />
= T1<br />
TN<br />
• Efici<strong>en</strong>cia: % de tiempo invertido <strong>en</strong> el proceso actual.<br />
Efici<strong>en</strong>cia =<br />
Speedup<br />
Nmerodeprocesadores<br />
= T1<br />
TN · N<br />
36<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Métricas de r<strong>en</strong>dimi<strong>en</strong>to 36/40
Ley de Amdahl<br />
• La Ley de Amdahl establece que el speedup de un programa<br />
queda definido por la fracción de código (P) que se puede<br />
paralelizar<br />
◦ P=fracción paralela; N=número de procesadores; S=fracción<br />
serie<br />
37<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Métricas de r<strong>en</strong>dimi<strong>en</strong>to 37/40
Ley de Amdahl<br />
• Resulta obvio que la escalabilidad del paralelismo ti<strong>en</strong>e límites.<br />
38<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Métricas de r<strong>en</strong>dimi<strong>en</strong>to 38/40
Ley de Amdahl<br />
• Corolario a la ley de Amdahl:<br />
◦ Dada la fracción paralela p de un programa, el máximo speedup<br />
alcanzable es 1/(1 − p)<br />
Speedup =<br />
(1 − p) + p<br />
(1 − p) + p<br />
N<br />
= lim<br />
n→∞<br />
=<br />
1<br />
(1 − p) + p<br />
N<br />
1<br />
(1 − p) + p<br />
N<br />
=<br />
1<br />
(1 − p)<br />
(0.0)<br />
39<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Métricas de r<strong>en</strong>dimi<strong>en</strong>to 39/40
Ley de Gustafson<br />
• Determinados problemas increm<strong>en</strong>tan el r<strong>en</strong>dimi<strong>en</strong>to<br />
aum<strong>en</strong>tando el tamaño del problema.<br />
◦ Por ejemplo: cálculos <strong>en</strong> Grids 2D.<br />
◦ Los problemas que aum<strong>en</strong>tan el porc<strong>en</strong>taje de tiempo paralelo<br />
con su tamaño son más escalables que los problemas que<br />
manti<strong>en</strong><strong>en</strong> un tiempo paralelo fijo.<br />
40<br />
/40<br />
c○GMRV 2013 Tipos de paralelismo y su reflejo <strong>en</strong> las GPUs Métricas de r<strong>en</strong>dimi<strong>en</strong>to 40/40