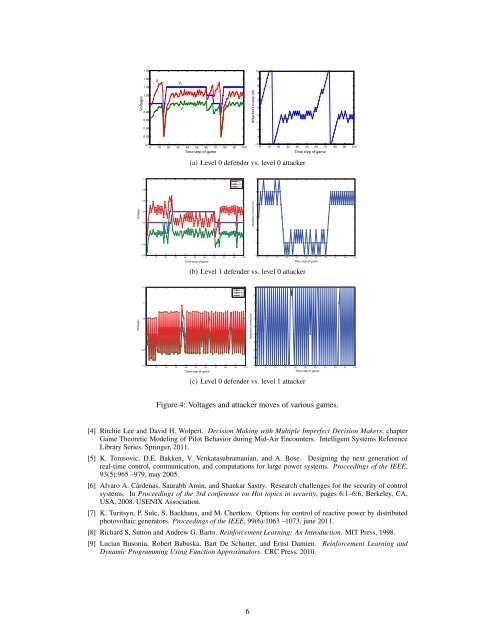
1.081.06108V 3Voltages1.041.0210.980.960.94V 1V 2Attacker’s move (m)6420−2−4−60.92−80.90 10 20 30 40 50 60 70 80 90 100Time step <strong>of</strong> game−100 10 20 30 40 50 60 70 80 90 100Time step <strong>of</strong> game(a) Level 0 defender vs. level 0 attacker1.11.08V1V2V343Voltages1.061.041.02Attacker’s move (m)21100.98−10.960 10 20 30 40 50 60 70 80 90 100Time step <strong>of</strong> game−20 10 20 30 40 50 60 70 80 90 100Time step <strong>of</strong> game(b) Level 1 defender vs. level 0 attacker1.15V1V2V3541.132Voltages1.0510.95VoltagesAttacker’s move (m) Attacker’s move (m)10−1−2−3−40.90 10 20 30 40 50 60 70 80 90 100Time step <strong>of</strong> game−50 10 20 30 40 50 60 70 80 90 100Time step <strong>of</strong> game(c) Level 0 defender vs. level 1 attackerFigure 4: Voltages and attacker moves <strong>of</strong> various games.[4] Ritchie Lee and David H. Wolpert. Decision Making <strong>with</strong> Multiple Imperfect Decision Makers, chapterGame Theoretic Modeling <strong>of</strong> Pilot Behavior during Mid-Air Encounters. Intelligent Systems ReferenceLibrary Series. Springer, 2011.[5] K. Tomsovic, D.E. Bakken, V. Venkatasubramanian, and A. Bose. Designing the next generation <strong>of</strong>real-time control, communication, and computations for large power systems. Proceedings <strong>of</strong> the IEEE,93(5):965 –979, may 2005.[6] Alvaro A. Cárdenas, Saurabh Amin, and Shankar Sastry. Research challenges for the security <strong>of</strong> controlsystems. In Proceedings <strong>of</strong> the 3rd conference on Hot topics in security, pages 6:1–6:6, Berkeley, CA,USA, 2008. USENIX Association.[7] K. Turitsyn, P. Sulc, S. Backhaus, and M. Chertkov. Options for control <strong>of</strong> reactive power by distributedphotovoltaic generators. Proceedings <strong>of</strong> the IEEE, 99(6):1063 –1073, june 2011.[8] Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction. MIT Press, 1998.[9] Lucian Busoniu, Robert Babuska, Bart De Schutter, and Ernst Damien. Reinforcement Learning andDynamic Programming Using Function Approximators. CRC Press, 2010.6
Automated Explanations for MDP PoliciesOmar Zia Khan, Pascal Poupart and James P. BlackDavid R. Cheriton School <strong>of</strong> Computer ScienceUniversity <strong>of</strong> Waterloo200 University Avenue West, Waterloo, ON, N2L 3G1, Canada{ozkhan, ppoupart, jpblack}@cs.uwaterloo.caAbstractExplaining policies <strong>of</strong> Markov Decision Processes (MDPs) is complicated dueto their probabilistic and sequential nature. We present a technique to explainpolicies for factored MDP by populating a set <strong>of</strong> domain-independent templates.We also present a mechanism to determine a minimal set <strong>of</strong> templates that, viewedtogether, completely justify the policy. We demonstrate our technique using theproblems <strong>of</strong> advising undergraduate students in their course selection and evaluateit through a user study.1 IntroductionSequential <strong>decision</strong> <strong>making</strong> is a notoriously difficult problem especially when there is uncertainty inthe effects <strong>of</strong> the actions and the objectives are complex. MDPs [10] provide a principled approachfor automated planning under uncertainty. State-<strong>of</strong>-the-art techniques provide scalable algorithmsfor MDPs [9], but the bottleneck is gaining user acceptance as it is harder to understand why certainactions are recommended. Explanations can enhance the user’s understanding <strong>of</strong> these plans (whenthe policy is to be used by humans like in recommender systems) and help MDP designers to debugthem (even when the policy is to be used by machines, like in robotics). Our explanations highlightkey factors through a set <strong>of</strong> explanation templates. The set <strong>of</strong> templates are sufficient, such that theyjustify the recommended action, yet also minimal, such that the size <strong>of</strong> the set cannot be smaller. Wedemonstrate our technique through a course-advising MDP and evaluate our explanations through auser study. A more detailed description <strong>of</strong> our work can be found in [6].2 BackgroundA Markov <strong>decision</strong> process (MDP) is defined by a set S <strong>of</strong> states s, a set A <strong>of</strong> actions a, a transitionmodel (the probability P r (s ′ |s, a) <strong>of</strong> an action a in state s leading to state s ′ ), a reward model (theutility/reward R (s, a) for executing action a in state s), and a discount factor γ ∈ [0, 1). FactoredMDPs [1] are typically used for MDPs <strong>with</strong> large state space where states are determined by values<strong>of</strong> some variables. A scenario sc is defined as the set <strong>of</strong> states obtained by assigning values to asubset <strong>of</strong> state variables. A policy π : S → A is a mapping from states to actions. The value V π (s)<strong>of</strong> a policy π when starting in state s is the sum <strong>of</strong> the expected discounted rewards earned byexecuting policy π. A policy can be evaluated by using Bellman’s equation V π (s) = R (s, π (s)) +γ ∑ s ′ ∈S P r (s′ |s, π (s)) · V π (s ′ ). We shall use an alternative method to evaluate a policy basedon occupancy frequencies. The discounted occupancy frequency (hereafter referred as occupancyfrequency) λ π s 0(s ′ ) is the expected (discounted) number <strong>of</strong> times we reach state s ′ from starting states 0 by executing policy π. Occupancy frequencies can be computed by solving Eq. 1.λ π s 0(s ′ ) = δ (s ′ , s 0 ) + γ ∑ s∈SP r (s ′ |s, π (s)) · λ π s 0(s) ∀s ′ (1)1
- Page 1 and 2: The 2nd International Workshop onDE
- Page 3 and 4: The 2nd International Workshop onDE
- Page 5 and 6: Time Title Authors7:30—7:50 Openi
- Page 7 and 8: Modeling Humans as Reinforcement Le
- Page 9 and 10: solution concept used to predict th
- Page 11: an ɛ-greedy policy parameterizatio
- Page 15 and 16: V E = ∑ i∈Eλ π∗s 0(sc i )
- Page 17 and 18: Figure 1: User Perception of MDP-Ba
- Page 19 and 20: [9] Warren B. Powell. Approximate D
- Page 21 and 22: information (technological knowledg
- Page 23 and 24: The complete fulfilment of preferen
- Page 25 and 26: References[1] J.O. Berger. Statisti
- Page 27 and 28: (happiness, anger, fear, disgust, s
- Page 30 and 31: David H Wolpert, editors, Decision
- Page 32 and 33: on some of their concepts, we devel
- Page 34 and 35: We assume that they are evaluated t
- Page 36 and 37: AcknowledgmentsResearch supported b
- Page 38 and 39: Bayesian Combination of Multiple, I
- Page 40 and 41: is not in closed form [5], requirin
- Page 42 and 43: where α (k)j is updated by adding
- Page 44 and 45: Figure 3: Prototypical confusion ma
- Page 46 and 47: Artificial Intelligence Designfor R
- Page 48 and 49: the game. Each has its own attribut
- Page 50 and 51: 4.3 Experimental Results and Limita
- Page 52 and 53: Distributed Decision Making byCateg
- Page 54 and 55: q 1a 1 (1) b 1(1)a 2(1)b 2(1)a K(1)
- Page 56 and 57: Bayes risk0.250.20.150.10.05Collabo
- Page 58 and 59: Decision making and working memory
- Page 60 and 61: in WM as well as inhibitory tasks [
- Page 62 and 63:
Difficulty level will be automatica
- Page 64 and 65:
Overall, the current literature lea
- Page 66 and 67:
[31] W K Bickel, R Yi, R D Landes,
- Page 68 and 69:
Each time instant, the agents first
- Page 70 and 71:
Figure 2: Two basic decentralized a
- Page 72 and 73:
[11] M. Kárný and T.V. Guy. Shari
- Page 74 and 75:
these results yields a design metho
- Page 76 and 77:
Minimum of (16) is well known from
- Page 78 and 79:
Algorithm 2 VB-DP variant of the di
- Page 80 and 81:
Further simplications can be achiev
- Page 82 and 83:
The basic terms we use are as follo
- Page 84 and 85:
3 Connection to the Bayesian soluti
- Page 86 and 87:
4 ConclusionThis paper brings an im
- Page 88 and 89:
2 Dynamic programming and revisions
- Page 90 and 91:
The possible way how to recognize t
- Page 92 and 93:
The data used for experiment are da
- Page 95:
T.V. Guy, Institute of Information