- Page 1:
Department of Computer Science and
- Page 11 and 12:
9 Preface Meet the new boss Same as
- Page 13:
11 Then there is my dear Xi, who, s
- Page 16 and 17:
14 2.3.3 InterruptsandPreemption...
- Page 18 and 19:
16 4.1.1 Implementation Effort ....
- Page 20 and 21:
18 Appendix C Patches to the 5.99.4
- Page 22 and 23:
20 ISA LGPL LRU LWP MD MI MMU NIC O
- Page 25 and 26:
23 List of Figures 2.1 Rumpkernelhi
- Page 27:
25 4.14 Time to execute 5M system c
- Page 31 and 32:
29 1 Introduction In its classic ro
- Page 33 and 34:
31 and application-level drivers. T
- Page 35 and 36:
33 We define an anykernel to be an
- Page 37 and 38:
35 Our implementation supports rump
- Page 39 and 40:
37 The project was done in small in
- Page 41 and 42:
39 2 The Anykernel and Rump Kernels
- Page 43 and 44:
41 building on top of the entities
- Page 45 and 46:
43 Drivers in a rump kernel remain
- Page 47 and 48:
45 Figure 2.1: Rump k
- Page 49 and 50:
47 in Section 3.2.3. Whenever discu
- Page 51 and 52:
49 int rumpns_bpfopen(dev_t, int, i
- Page 53 and 54:
51 Figure 2.4:
- Page 55 and 56:
53 while the application logic stil
- Page 57 and 58:
55 We must solve the lack of a rump
- Page 59 and 60:
57 2.3.1 Kernel threads Up until no
- Page 61 and 62:
59 void * pool_cache_get_paddr(pool
- Page 63 and 64:
61 2.3.4 An Example We present an e
- Page 65 and 66:
63 Figure 2.6: Prov
- Page 67:
65 The straightforward use of exist
- Page 70 and 71:
68 We identified three obstacles fo
- Page 72 and 73:
70 for loadable kernel modules (dis
- Page 74 and 75:
72 e.g. the routine for mapping a p
- Page 76 and 77:
74 3.2.1 C Symbol Namespaces In the
- Page 78 and 79:
76 the double underscore namespace
- Page 80 and 81:
78 since the representation might n
- Page 82 and 83:
80 The following rumpuser interface
- Page 84 and 85:
82 The entry point rump_schedule()
- Page 86 and 87:
84 3.3.1 CPU Scheduling Recall from
- Page 88 and 89:
86 The fastpath is taken in cases w
- Page 90 and 91:
88 Releasing a CPU requires the fol
- Page 92 and 93:
90 10 8 seconds 6 4 2 0 1CPU 2CPU n
- Page 94 and 95:
92 Hardware interrupt handlers are
- Page 96 and 97:
94 Due to the design choice that a
- Page 98 and 99:
96 in. Therefore, we should critica
- Page 100 and 101:
98 Pager window create+access time
- Page 102 and 103:
100 A rump kernel can be configured
- Page 104 and 105:
102 Since all pages managed by the
- Page 106 and 107:
104 not in control of thread schedu
- Page 108 and 109:
106 synchronization part of the alg
- Page 110 and 111:
108 /* * Run a cross call to cycle
- Page 112 and 113:
110 kernel needs to do is make sure
- Page 114 and 115:
112 The kernel with uniprocessor lo
- Page 116 and 117:
114 the header file while open() c
- Page 118 and 119:
116 The same wrapper works both for
- Page 120 and 121:
118 5. Some calling conventions (e.
- Page 122 and 123:
120 int rump_pub_lwproc_rfork(int a
- Page 124 and 125:
122 By convention, file system devi
- Page 126 and 127:
124 ule directory tree from /stand
- Page 128 and 129:
126 After these steps have been per
- Page 130 and 131:
128 Host Dynamic Linker Using the h
- Page 132 and 133:
130 for (i = 0; i < SYS_NSYSENT; i+
- Page 134 and 135:
132 into a rump kernel and the driv
- Page 136 and 137:
134 sys/arch/x86/include/cpu.h: #de
- Page 138 and 139:
136 3.8.4 Rump Component Init Routi
- Page 140 and 141:
138 RUMP_COMPONENT(RUMP_COMPONENT_N
- Page 142 and 143:
140 We have three distinct cases we
- Page 144 and 145:
142 # ifconfig tap0 create # ifconf
- Page 146 and 147:
144 Unprivileged use of host’s ne
- Page 148 and 149:
146 DOMAIN_DEFINE(sockindomain); co
- Page 150 and 151:
148 issue another write before the
- Page 152 and 153:
150 using an interface called USBDI
- Page 154 and 155:
152 The kernel device configuration
- Page 156 and 157:
154 # $NetBSD: UMASS.ioconf,v 1.4 2
- Page 158 and 159:
156 USB Host Controller Hub0 (root)
- Page 160 and 161:
158 Figure 3.30: File s
- Page 162 and 163:
160 in-kernel mount: /dev/sd0e /m/u
- Page 164 and 165:
162 structure being created by rump
- Page 166 and 167:
164 3.12.1 Client-Kernel Locators B
- Page 168 and 169:
166 A tmpfs server listening on INA
- Page 170 and 171:
168 Request Arguments Response Desc
- Page 172 and 173:
170 Host syscall rump syscall 1. op
- Page 174 and 175:
172 A client’s initial connection
- Page 176 and 177: 174 their system calls to a rump ke
- Page 178 and 179: 176 stdin/stdout, the new file desc
- Page 180 and 181: 178 Supporting fork() Recall, the f
- Page 182 and 183: 180 As with fork, most of the kerne
- Page 184 and 185: 182 Anecdotal analysis For several
- Page 186 and 187: 184
- Page 188 and 189: 186 SLOC 8000 7000 6000 5000 4000 3
- Page 190 and 191: 188 Total commits to the kernel 9,6
- Page 192 and 193: 190 120 build time (minutes) 100 80
- Page 194 and 195: 192 4.2.2 makefs For a source tree
- Page 196 and 197: 194 not include later debugging [76
- Page 198 and 199: 196 the necessary tools such as mak
- Page 200 and 201: 198 proach of supplying alternate c
- Page 202 and 203: 200 are not out-of-the-box compatib
- Page 204 and 205: 202 golem> mount -t msdos -o rump /
- Page 206 and 207: 204 Full OS By a full OS we mean a
- Page 208 and 209: 206 • Rapid prototyping: One of t
- Page 210 and 211: 208 4.5.3 Testing: Case Studies We
- Page 212 and 213: 210 static void scsitest_request(st
- Page 214 and 215: 212 waits for the timeout and check
- Page 216 and 217: 214 • We noticed that even in sup
- Page 218 and 219: 216 which were discovered during wr
- Page 220 and 221: 218 version swap no swap NetBSD 5.1
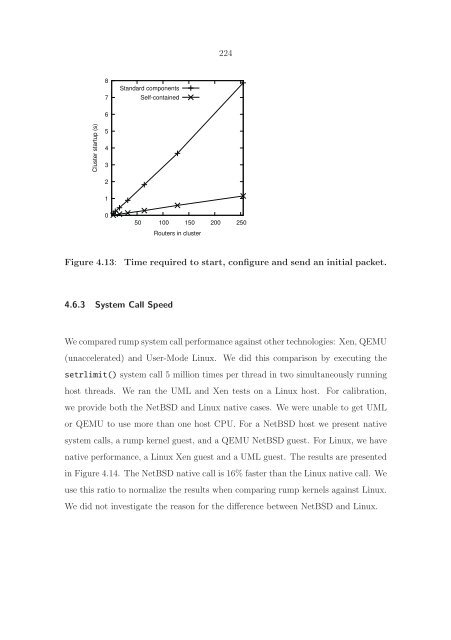
- Page 222 and 223: 220 It needs to be stressed that Ta
- Page 224 and 225: 222 Network clusters Bootstrapping
- Page 228 and 229: 226 Rump kernel calls, as expected,
- Page 230 and 231: 228 Traditional FFS We measure the
- Page 232 and 233: 230 80 70 60 seconds 50 40 30 20 10
- Page 234 and 235: 232 The results are presented in Fi
- Page 236 and 237: 234 behavior is required by the act
- Page 238 and 239: 236
- Page 240 and 241: 238 Rialto [29] is an operating sys
- Page 242 and 243: 240 One argument for partitioned op
- Page 244 and 245: 242 View OS The View OS [37] approa
- Page 246 and 247: 244 OSKit Instead of making system
- Page 248 and 249: 246 discussing the type incompatibi
- Page 250 and 251: 248 difference to the abovementione
- Page 252 and 253: 250 At runtime, a rump kernel can a
- Page 254 and 255: 252 For testing and development we
- Page 256 and 257: 254
- Page 258 and 259: 256 Art of Virtualization. In: Proc
- Page 260 and 261: 258 [30] Adam Dunkels. 2001. Design
- Page 262 and 263: 260 [47] Galen C. Hunt and James R.
- Page 264 and 265: 262 [67] Steven McCanne and Van Jac
- Page 266 and 267: 264 [87] NetBSD Project. URL http:/
- Page 268 and 269: 266 of the 6th Workshop on Programm
- Page 270 and 271: 268
- Page 272 and 273: A-2 RUMP.DHCPCLIENT(1) NetBSD Gener
- Page 274 and 275: A-4 RUMP.HALT(1) NetBSD General Com
- Page 276 and 277:
A-6 RUMP_SERVER(1) NetBSD General C
- Page 278 and 279:
A-8 RUMP_SERVER(1) NetBSD General C
- Page 280 and 281:
A-10 SHMIF_DUMPBUS(1) NetBSD Genera
- Page 282 and 283:
A-12 P2K(3) NetBSD Library Function
- Page 284 and 285:
A-14 P2K(3) NetBSD Library Function
- Page 286 and 287:
A-16 RUMP(3) NetBSD Library Functio
- Page 288 and 289:
A-18 RUMP(3) NetBSD Library Functio
- Page 290 and 291:
A-20 RUMP_ETFS(3) NetBSD Library Fu
- Page 292 and 293:
A-22 RUMP_ETFS(3) NetBSD Library Fu
- Page 294 and 295:
A-24 RUMP_LWPROC(3) NetBSD Library
- Page 296 and 297:
A-26 RUMP_LWPROC(3) NetBSD Library
- Page 298 and 299:
A-28 RUMPCLIENT(3) NetBSD Library F
- Page 300 and 301:
A-30 RUMPCLIENT(3) NetBSD Library F
- Page 302 and 303:
A-32 RUMPHIJACK(3) NetBSD Library F
- Page 304 and 305:
A-34 RUMPHIJACK(3) NetBSD Library F
- Page 306 and 307:
A-36 RUMPHIJACK(3) NetBSD Library F
- Page 308 and 309:
A-38 UKFS(3) NetBSD Library Functio
- Page 310 and 311:
A-40 UKFS(3) NetBSD Library Functio
- Page 312 and 313:
A-42 UKFS(3) NetBSD Library Functio
- Page 314 and 315:
A-44 UKFS(3) NetBSD Library Functio
- Page 316 and 317:
A-46 UKFS(3) NetBSD Library Functio
- Page 318 and 319:
A-48 SHMIF(4) NetBSD Kernel Interfa
- Page 320 and 321:
A-50 RUMP_SP(7) NetBSD Miscellaneou
- Page 322 and 323:
A-52 RUMP_SP(7) NetBSD Miscellaneou
- Page 324 and 325:
B-2 TCP connections use standard TC
- Page 326 and 327:
B-4 rump clients. This means that j
- Page 328 and 329:
B-6 ponents. That can be done simpl
- Page 330 and 331:
B-8 Our goal is to add another part
- Page 332 and 333:
B-10 golem> export RUMP_SERVER=unix
- Page 334 and 335:
B-12 golem> rump.dd if=/dev/rcgd0d
- Page 336 and 337:
B-14 demogorgon# cgdconfig cgd0 /de
- Page 338 and 339:
B-16 rump_server -lrumpnet -lrumpne
- Page 340 and 341:
B-18 golem> rump.ifconfig virt0 cre
- Page 342 and 343:
B-20 Congratulations, that’s it.
- Page 344 and 345:
B-22 purely in userspace, it does n
- Page 346 and 347:
B-24 We then proceed to create a mo
- Page 348 and 349:
B-26 Then, the only thing left is t
- Page 350 and 351:
B-28 -d key=/dk,hostpath=${NFSX}/ff
- Page 352 and 353:
B-30 configuration. golem> sh rumpn
- Page 354 and 355:
B-32
- Page 356 and 357:
C-2 This is a quick fix for making
- Page 358 and 359:
C-4 This fixes the conditionally co
- Page 362:
Aalto-DD 171/2012 9HSTFMG*aejbgi+ I