

High Availability Theoretical Basics - Schneider Electric
High Availability Theoretical Basics - Schneider Electric
High Availability Theoretical Basics - Schneider Electric

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
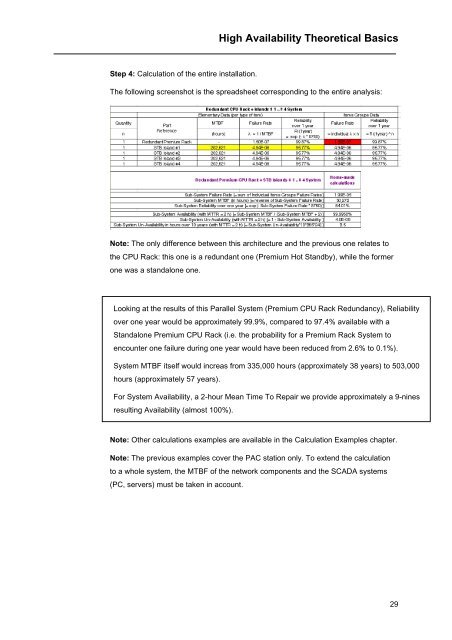
Step 4: Calculation of the entire installation.<br />
<strong>High</strong> <strong>Availability</strong> <strong>Theoretical</strong> <strong>Basics</strong><br />
The following screenshot is the spreadsheet corresponding to the entire analysis:<br />
Note: The only difference between this architecture and the previous one relates to<br />
the CPU Rack: this one is a redundant one (Premium Hot Standby), while the former<br />
one was a standalone one.<br />
Looking at the results of this Parallel System (Premium CPU Rack Redundancy), Reliability<br />
over one year would be approximately 99.9%, compared to 97.4% available with a<br />
Standalone Premium CPU Rack (i.e. the probability for a Premium Rack System to<br />
encounter one failure during one year would have been reduced from 2.6% to 0.1%).<br />
System MTBF itself would increas from 335,000 hours (approximately 38 years) to 503,000<br />
hours (approximately 57 years).<br />
For System <strong>Availability</strong>, a 2-hour Mean Time To Repair we provide approximately a 9-nines<br />
resulting <strong>Availability</strong> (almost 100%).<br />
Note: Other calculations examples are available in the Calculation Examples chapter.<br />
Note: The previous examples cover the PAC station only. To extend the calculation<br />
to a whole system, the MTBF of the network components and the SCADA systems<br />
(PC, servers) must be taken in account.<br />
29














