VzorÄenje in statistiÄno zakljuÄevanje
VzorÄenje in statistiÄno zakljuÄevanje
VzorÄenje in statistiÄno zakljuÄevanje
- No tags were found...

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
22.11.2011<br />
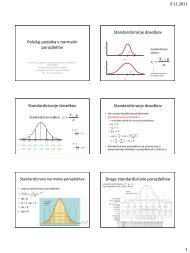
Vzorčne porazdelitve<br />
Vzorčne porazdelitve<br />
• Če iz def<strong>in</strong>irane populacije izberemo vse možne vzorce<br />
velikosti N, lahko za vsak vzorec določimo statistike (npr. M,<br />
SD). Statistike se od vzorca do vzorca sprem<strong>in</strong>jajo.<br />
Vzorci se<br />
razlikujejo.<br />
statistika statistika statistika<br />
Vzorčna<br />
porazdelitev<br />
… je porazdelitev<br />
statistike<br />
neskončnega<br />
števila vzorcev<br />
7<br />
vzorčne porazdelitve statistik<br />
– opisnih statistik vzorca, npr. M, var, p, r…<br />
– drugih izrazov, npr.<br />
M1<br />
M 2<br />
SE M 1M<br />
2<br />
• Vsako vzorčno porazdelitev lahko opišemo:<br />
M statistike<br />
SD = SE statistike<br />
8<br />
Vzorčne porazdelitve<br />
Standardna napaka<br />
frekvenčna<br />
porazdelitev<br />
spremenljivke<br />
vzorčna<br />
porazdelitev<br />
statistike<br />
za manjše /<br />
večje vzorce<br />
SD<br />
M<br />
SE statistike<br />
M statistike<br />
Če je vzorec velik, bo<br />
statistika vzorca bolj<br />
podobna parametru.<br />
Razpršenost vzorčne<br />
porazdelitve se<br />
z večanjem vzorca<br />
manjša.<br />
9<br />
σ<br />
M<br />
SE M<br />
SE<br />
p<br />
SE<br />
M<br />
<br />
σ<br />
N<br />
= standardni odklon vzorčnih<br />
aritmetičnih sred<strong>in</strong><br />
= standardna napaka ocene m<br />
<br />
p(1<br />
p)<br />
N<br />
SE<br />
σ<br />
<br />
Standardna napaka se z<br />
večanjem vzorca manjša.<br />
σ<br />
2N<br />
10<br />
Verjetnost pojavljanja vzorčne<br />
statistike pri velikih vzorcih<br />
• Če poznamo parameter v populaciji, lahko:<br />
– določimo verjetnost pojavljanja določene<br />
vrednosti vzorčne statistike.<br />
z = statistika−parameter<br />
SE statistike<br />
p<br />
– določimo <strong>in</strong>terval vrednosti statistike, ki jo<br />
pričakujemo v srednjih k % vzorcev.<br />
vzorčna porazdelitev G je N.D.<br />
Gvz<br />
G<br />
z<br />
p<br />
<br />
SE<br />
Verjetnost pojavljanja vzorčne<br />
statistike pri velikih vzorcih<br />
G<br />
pop<br />
N (0,1)<br />
G pop<br />
11 12<br />
0<br />
SE G<br />
1<br />
G vz<br />
z<br />
2