Kommentierter SPSS-Ausdruck zur logistischen Regression
Kommentierter SPSS-Ausdruck zur logistischen Regression
Kommentierter SPSS-Ausdruck zur logistischen Regression

Erfolgreiche ePaper selbst erstellen
Machen Sie aus Ihren PDF Publikationen ein blätterbares Flipbook mit unserer einzigartigen Google optimierten e-Paper Software.
R.Niketta Logistische <strong>Regression</strong><br />
Daten: POK V – AG 3 (POKV_AG3_V07.SAV)<br />
<strong>Kommentierter</strong> <strong>SPSS</strong>-<strong>Ausdruck</strong> <strong>zur</strong> <strong>logistischen</strong> <strong>Regression</strong><br />
Fragestellung: Welchen Einfluss hat die Fachnähe und das Geschlecht auf die interpersonale Attraktion einer Stimulusperson, bei der nur das<br />
Studienfach variiert wurde?<br />
AV: ipa_dicho 1 (interpersonale Attraktion -dichotomisiert über einen Mediansplit; 1 = niedrig, 2 = hoch)<br />
UV: fachinter (Fachinteresse, ein hoher Wert bedeutet hohes Interesse an dem Studienfach der Stimulusperson), geschl (Geschlecht; 1 = weiblich<br />
2 = männlich)<br />
1 <strong>SPSS</strong> Version 12 akzeptiert auch Variablenbezeichnungen mit mehr als acht Zeichen, wie ipa_dicho. In den Ausgaben wurde aber die Variable wieder auf acht<br />
Zeichen reduziert, damit die Variablenbenennungen mit anderen Programmen kompatibel sind.<br />
Beispiel_logistische_<strong>Regression</strong>.doc
R.Niketta Logistische <strong>Regression</strong><br />
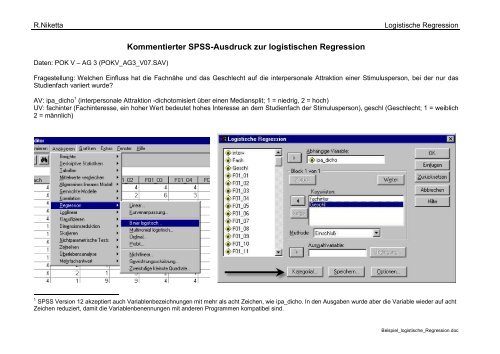
Über „<strong>Regression</strong>“ wird die Prozedur „Binär logistisch“ aufgerufen Die Variablen werden in die jeweiligen Fenster übertragen. Die Prädiktoren<br />
(unabhängige Variablen) heißen hier „Kovariaten“.<br />
Es ist eine kategoriale Variable, das Geschlecht vorhanden.<br />
Es wird die Indikator-Kodierung gewählt (Voreinstellung).<br />
Dies entspricht der „Dummy-Codierung“ bei der<br />
<strong>Regression</strong>sanalyse.<br />
Es kann auch gewählt werden, ob die erste oder die letzte<br />
Kategorie als Referenzkategorie gewählt wird, d.h. mit<br />
welcher Stufe verglichen wird.<br />
Unter den „Optionen“ sind die Klassifikationsdiagramme<br />
und die Hosmer-Lemeshow-Anpassungsstatistik von<br />
Interesse. Auch sollten Sie, wenn Sie keine schrittweise<br />
logistische <strong>Regression</strong> rechnen, nur die die Ergebnisse<br />
beim letzten Schritt anzeigen lassen.<br />
Für eine etwaige logistische Funktionskurve können die<br />
Wahrscheinlichkeiten der vorhergesagten Werte gespeichert<br />
werden.<br />
Beispiel_logistische_<strong>Regression</strong>.doc
R.Niketta Logistische <strong>Regression</strong><br />
Zusammenfassung der Fallverarbeitung<br />
Ungewichtete Fälle(a) N Prozent<br />
Ausgewählte Fälle Einbezogen in Analyse 149 89.8<br />
Fehlende Fälle 17 10.2<br />
Gesamt 166 100.0<br />
Nicht ausgewählte Fälle 0 .0<br />
Gesamt 166 100.0<br />
a Wenn die Gewichtung wirksam ist, finden Sie die Gesamtzahl der Fälle in der Klassifizierungstabelle.<br />
Codierung abhängiger Variablen<br />
Ursprünglicher Wert Interner Wert<br />
1 niedrig 0<br />
2 hoch 1<br />
Geschl Geschlecht<br />
der<br />
Stimulusperson<br />
_<br />
Codierungen kategorialer Variablen<br />
Parametercodierung<br />
Häufigkeit (1)<br />
1 weiblich 77 1.000<br />
2 männlich 72 .000<br />
Durch fehlende Werte reduziert sich der Datensatz<br />
auf 149 Personen.<br />
Protokoll der Kodierung der AV. Wenn die abhängige<br />
Variable nicht 0-1 codiert ist, wählt <strong>SPSS</strong> automatisch<br />
die erste Stufe als Referenzkategorie. Es<br />
können auch andere Originalcodes als 0 und 1 gewählt<br />
werden (Rekodierung in eine neue Variable).<br />
Protokollierung der kategorialen Variablen Geschlecht.<br />
Die Stufe „männlich“ ist die Referenzkategorie.<br />
Beispiel_logistische_<strong>Regression</strong>.doc
R.Niketta Logistische <strong>Regression</strong><br />
Schritt 1<br />
Omnibus-Tests der Modellkoeffizienten<br />
Chi-Quadrat df Sig.<br />
Schritt 9.053 2 .011<br />
Block 9.053 2 .011<br />
Modell 9.053 2 .011<br />
Modellzusammenfassung<br />
-2 Log- Cox & Snell Nagelkerkes<br />
Schritt Likelihood R-Quadrat R-Quadrat<br />
1 196.961(a) .059 .079<br />
a Schätzung beendet bei Iteration Nummer 3, weil die Parameterschätzer sich um weniger als .001 änderten.<br />
Hosmer-Lemeshow-Test<br />
Schritt Chi-Quadrat df Sig.<br />
1 9.934 7 .192<br />
Der Modell-Chi-Quadrat-Wert ist die Differenz<br />
zwischen dem Null-Modell und dem Prädiktoren-Modell.<br />
Es wird die H0 überprüft, dass die<br />
Prädiktoren gleich null sind. Die H0 muss abgelehnt<br />
werden (p < .05). Die Prädiktoren<br />
liefern einen signifikanten Zuwachs bei der<br />
Modellanpassung. Das untersuchte Modell ist<br />
also besser als das „Null-Modell“ nur mit der<br />
Konstanten.<br />
„Block“ und „Schritt“ sind bei schrittweisen<br />
<strong>Regression</strong>sanalysen von Bedeutung.<br />
Die Ableitungen für die ML-Schätzwerte sind<br />
nicht linear, daher ist eine iterative Schätzung<br />
notwendig, die abbricht, wenn der Zuwachs<br />
ein voreingestelltes Kriterium unterschreitet.<br />
Dies ist der Wert für das Modell, das die Prädiktoren<br />
einschließt.<br />
Die R 2 -Werte setzen das „Nullmodell“ mit dem<br />
gewählten Modell in Beziehung, sie können in<br />
etwa als PRE-Koeffizienten aufgefasst werden<br />
und geben die proportionale Fehlerreduktion<br />
an. Sie sind selten hoch. Nagelkerke<br />
R 2 sollte interpretiert werden (korr. R 2 ). Die<br />
Fehlerreduktion („erklärte Varianz“) beträgt<br />
also 7.9 %.<br />
Der Hosmer-Lemeshow-Test teilt die Stichprobe<br />
in max. 10 Gruppen und überprüft die<br />
Differenzen zwischen beobachteten und erwarteten<br />
Werten. Je geringer die Differenz,<br />
umso besser die Modellanpassung. Gesucht<br />
wird daher eine Bestätigung der H0 (also kein<br />
signifikantes Ergebnis). Dies ist hier der Fall.<br />
Beispiel_logistische_<strong>Regression</strong>.doc
R.Niketta Logistische <strong>Regression</strong><br />
Schritt<br />
1<br />
Schritt 1<br />
Kontingenztabelle für Hosmer-Lemeshow-Test<br />
ipa_dich Interpersonale<br />
Attraktion ((Mediansplit) =<br />
1 niedrig<br />
ipa_dich Interpersonale<br />
Attraktion ((Mediansplit) =<br />
2 hoch<br />
Beobachtet Erwartet Beobachtet Erwartet Gesamt<br />
1 12 13.849 8 6.151 20<br />
2 14 11.606 4 6.394 18<br />
3 18 15.245 7 9.755 25<br />
4 11 11.150 9 8.850 20<br />
5 3 5.724 8 5.276 11<br />
6 5 6.532 9 7.468 14<br />
7 4 3.436 4 4.564 8<br />
8 4 6.044 12 9.956 16<br />
9 8 5.414 9 11.586 17<br />
a Der Trennwert lautet .500<br />
Interpersonale<br />
Attraktion ((Mediansplit)<br />
Klassifizierungstabelle(a)<br />
niedrig<br />
Vorhergesagt<br />
Interpersonale Attraktion<br />
((Mediansplit)<br />
niedrig hoch<br />
Prozentsatz<br />
der Richtigen<br />
58 21 73.4<br />
hoch 36 34 48.6<br />
Gesamtprozentsatz 61.7<br />
Diese Tabelle zeigt die neun Stufen des<br />
Hosmer-Lemeshow-Tests mit den beobachteten<br />
und erwarteten Häufigkeiten in der Tradition<br />
des klassischen chi²-Tests.<br />
Tabelle der korrekten Zuordnungen (Vorhersagen)<br />
Die Gruppen sind nicht gleich verteilt (79 vs.<br />
70), die maximale Zufallswahrscheinlichkeit<br />
beträgt 79/149 = 53 %. Das Ergebnis ist nicht<br />
sonderlich gut (62 %), vor allem in der Bedingung<br />
hohe Attraktion werden mehr Personen<br />
falsch als richtig vorhergesagt.<br />
Beispiel_logistische_<strong>Regression</strong>.doc
R.Niketta Logistische <strong>Regression</strong><br />
<strong>Regression</strong>skoeffizientB<br />
Variablen in der Gleichung<br />
Standardfehler<br />
Wald df Sig. Exp(B)<br />
Schritt<br />
1(a)<br />
Geschl(1)<br />
fachinter<br />
.215<br />
.365<br />
.340<br />
.131<br />
.401<br />
7.780<br />
1<br />
1<br />
.527<br />
.005<br />
1.240<br />
1.441<br />
Konstante<br />
-.812 .311 6.810 1 .009 .444<br />
a In Schritt 1 eingegebene Variablen: Geschl, fachinter.<br />
Dies ist neben der Überprüfung des Gesamtmodells (Modell-Chi² und Nagelkerke R²) die<br />
wichtigste Tabelle, da hier überprüft wird, welche Prädiktoren für das statistisch signifikante<br />
Modell verantwortlich sind.<br />
Die logistische <strong>Regression</strong>sgleichung sieht also wie folgt aus:<br />
logit = -0.812 + 0.215 · Geschlecht + 0.365 · fachinter<br />
Die b-Koeffizienten können aber nur schlecht interpretiert werden, da es sich hier um logits<br />
handelt. Ein Wert von null würde „kein Einfluss“ bedeuten. Innerhalb der <strong>Regression</strong>sgleichung<br />
kann ausgerechnet werden, was eine Veränderung um eine Einheit für die Wahrscheinlichkeit,<br />
die Stimulusperson als attraktiv zu bewerten, bedeuten würde. Über den Antilogarithmus<br />
kann die Zuordnungswahrscheinlichkeit einer Person berechnet werden<br />
(e logit /(1+e logit ))<br />
Die statistische Absicherung geht über den Wald-Test, der dem t-Test äquivalent ist. Über<br />
den Standardfehler prüft der Wald-Test, ob die einzelnen Prädiktoren einen signifikanten<br />
Einfluss haben. Über den Wald-Test können auch die Prädiktoren des Modells untereinander<br />
verglichen werden. Im vorliegenden Falle kann der Einfluss des Geschlechts nicht gegen<br />
den Zufall abgesichert werden (p > .05). Der Einfluss des Fachinteresses kann hingegen<br />
statistisch signifikant abgesichert werden.<br />
Die Exp(B) geben die entlogarithmierten logit-<br />
Koeffizienten als Odd ratios wieder. Eine 1<br />
bedeutet keine Veränderung, somit kein Einfluss<br />
des Prädiktors. So verbessert sich das<br />
Wahrscheinlichkeitsverhältnis zwischen Niedrig-<br />
und Hochbewerten um das 1.4fache,<br />
wenn eine Veränderung um eine Skaleneinheit<br />
eintritt (hier 5er-Skala).Also: Die Wahrscheinlichkeit,<br />
die Stimulusperson als hoch<br />
attraktiv einzuschätzen, steigt mit jeder Skaleneinheit<br />
des Fachinteresses um das<br />
1.4fache. Die Chancen steigen demnach um<br />
100 * (1.1441 – 1) = 44 %. Die Änderungen<br />
hängen von den Skalenbreiten ab.<br />
Dass das Geschlecht keine Rolle spielt, lässt<br />
sich auch an der einfachen Kreuztabelle ablesen:<br />
ipa_dich Interpersonale Attraktion ((Mediansplit) * Geschl Geschlecht der<br />
Stimulusperson Kreuztabelle<br />
Anzahl<br />
ipa_dich Interpersonale<br />
Attraktion ((Mediansplit)<br />
Gesamt<br />
1 niedrig<br />
2 hoch<br />
Geschl Geschlecht der<br />
Stimulusperson<br />
1 weiblich 2 männlich Gesamt<br />
44 43 87<br />
40 34 74<br />
84 77 161<br />
Beispiel_logistische_<strong>Regression</strong>.doc
R.Niketta Logistische <strong>Regression</strong><br />
Das Histogramm der vorhergesagten Wahrscheinlichkeiten<br />
zeigt links die Gruppe der<br />
niedrig Attraktiven und rechts die der hoch<br />
Attraktiven. Eine falsche Zuordnung ist dann<br />
zu erkennen, wenn ein “hoch” Attraktiver (h)<br />
im Feld der niedrig Attraktiven auftaucht.<br />
Beispiel_logistische_<strong>Regression</strong>.doc
R.Niketta Logistische <strong>Regression</strong><br />
p_attrak<br />
0,80<br />
0,60<br />
0,40<br />
0,20<br />
-1,00000 0,00000 1,00000 2,00000<br />
Z-Wert(logits)<br />
Über den Antilogarithmus kann die Zuordnungswahrscheinlichkeit<br />
einer Person berechnet<br />
werden (e logit /(1+e logit )). Es werden<br />
über die <strong>Regression</strong>sgleichung die logits berechnet<br />
und z-transformiert. Diese z-logits<br />
werden dann in die obige Formel eingesetzt<br />
und die Zuordnungswahrscheinlichkeiten berechnet.<br />
Die Syntaxdatei:<br />
** Berechnung der Zuordnungswahrscheinlichkeiten.<br />
COMPUTE logits = -0.812 + 0.215 *<br />
Geschl + 0.365 * fachinter.<br />
execute.<br />
DESCRIPTIVES<br />
VARIABLES=logits /SAVE<br />
/STATISTICS=MEAN STDDEV MIN MAX .<br />
Diese Variable muss nur berechnet werden,<br />
wenn Sie die Wahrscheinlichkeiten der vorhergesagten<br />
Werte nicht speichern ließen.<br />
COMPUTE p_attrak =<br />
EXP(zlogits)/(1+EXP(zlogits)) .<br />
EXECUTE .<br />
Das Streudiagramm zeigt die zu erwartende<br />
logistische Funktionskurve. Das Ergebnis ist<br />
nicht eindeutig, da eher nur geringe Abweichungen<br />
von der Linearität zu verzeichnen<br />
sind.<br />
Beispiel_logistische_<strong>Regression</strong>.doc