Kommentierter SPSS-Ausdruck zur logistischen Regression
Kommentierter SPSS-Ausdruck zur logistischen Regression
Kommentierter SPSS-Ausdruck zur logistischen Regression

Sie wollen auch ein ePaper? Erhöhen Sie die Reichweite Ihrer Titel.
YUMPU macht aus Druck-PDFs automatisch weboptimierte ePaper, die Google liebt.
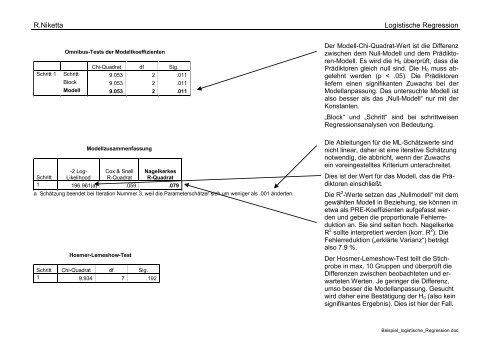
R.Niketta Logistische <strong>Regression</strong><br />
Schritt 1<br />
Omnibus-Tests der Modellkoeffizienten<br />
Chi-Quadrat df Sig.<br />
Schritt 9.053 2 .011<br />
Block 9.053 2 .011<br />
Modell 9.053 2 .011<br />
Modellzusammenfassung<br />
-2 Log- Cox & Snell Nagelkerkes<br />
Schritt Likelihood R-Quadrat R-Quadrat<br />
1 196.961(a) .059 .079<br />
a Schätzung beendet bei Iteration Nummer 3, weil die Parameterschätzer sich um weniger als .001 änderten.<br />
Hosmer-Lemeshow-Test<br />
Schritt Chi-Quadrat df Sig.<br />
1 9.934 7 .192<br />
Der Modell-Chi-Quadrat-Wert ist die Differenz<br />
zwischen dem Null-Modell und dem Prädiktoren-Modell.<br />
Es wird die H0 überprüft, dass die<br />
Prädiktoren gleich null sind. Die H0 muss abgelehnt<br />
werden (p < .05). Die Prädiktoren<br />
liefern einen signifikanten Zuwachs bei der<br />
Modellanpassung. Das untersuchte Modell ist<br />
also besser als das „Null-Modell“ nur mit der<br />
Konstanten.<br />
„Block“ und „Schritt“ sind bei schrittweisen<br />
<strong>Regression</strong>sanalysen von Bedeutung.<br />
Die Ableitungen für die ML-Schätzwerte sind<br />
nicht linear, daher ist eine iterative Schätzung<br />
notwendig, die abbricht, wenn der Zuwachs<br />
ein voreingestelltes Kriterium unterschreitet.<br />
Dies ist der Wert für das Modell, das die Prädiktoren<br />
einschließt.<br />
Die R 2 -Werte setzen das „Nullmodell“ mit dem<br />
gewählten Modell in Beziehung, sie können in<br />
etwa als PRE-Koeffizienten aufgefasst werden<br />
und geben die proportionale Fehlerreduktion<br />
an. Sie sind selten hoch. Nagelkerke<br />
R 2 sollte interpretiert werden (korr. R 2 ). Die<br />
Fehlerreduktion („erklärte Varianz“) beträgt<br />
also 7.9 %.<br />
Der Hosmer-Lemeshow-Test teilt die Stichprobe<br />
in max. 10 Gruppen und überprüft die<br />
Differenzen zwischen beobachteten und erwarteten<br />
Werten. Je geringer die Differenz,<br />
umso besser die Modellanpassung. Gesucht<br />
wird daher eine Bestätigung der H0 (also kein<br />
signifikantes Ergebnis). Dies ist hier der Fall.<br />
Beispiel_logistische_<strong>Regression</strong>.doc