

Musterlösung - Institut für Kommunikationsnetze und ...
Musterlösung - Institut für Kommunikationsnetze und ...
Musterlösung - Institut für Kommunikationsnetze und ...

Erfolgreiche ePaper selbst erstellen
Machen Sie aus Ihren PDF Publikationen ein blätterbares Flipbook mit unserer einzigartigen Google optimierten e-Paper Software.
Universität Stuttgart<br />
INSTITUT FÜR<br />
KOMMUNIKATIONSNETZE<br />
UND RECHNERSYSTEME<br />
Prof. Dr.-Ing. Dr. h. c. mult. P. J. Kühn<br />
<strong>Musterlösung</strong><br />
Termin:<br />
Technische Informatik I<br />
7. April 2008<br />
Aufgabe 1<br />
Digitale Bitmustererkennung<br />
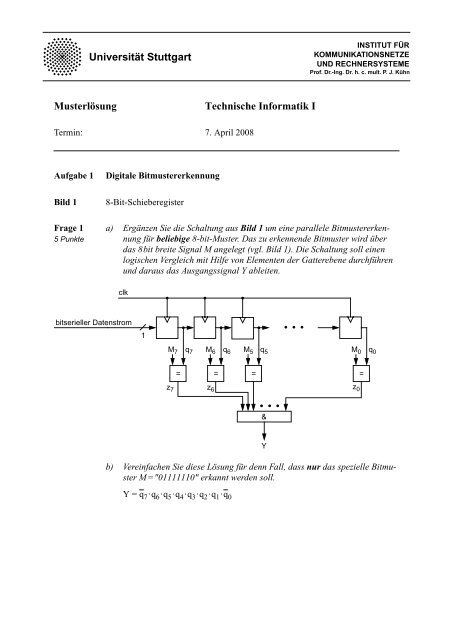
Bild 1<br />
8-Bit-Schieberegister<br />
Frage 1<br />
5 Punkte<br />
a) Ergänzen Sie die Schaltung aus Bild 1 um eine parallele Bitmustererkennung<br />
<strong>für</strong> beliebige 8-bit-Muster. Das zu erkennende Bitmuster wird über<br />
das 8bit breite Signal M angelegt (vgl. Bild 1). Die Schaltung soll einen<br />
logischen Vergleich mit Hilfe von Elementen der Gatterebene durchführen<br />
<strong>und</strong> daraus das Ausgangssignal Y ableiten.<br />
clk<br />
bitserieller Datenstrom<br />
1<br />
q 7 q 6 q 5 q 0<br />
M 7 M 6 M 5<br />
= = =<br />
z 7 z 6 z 0<br />
M 0<br />
=<br />
&<br />
b) Vereinfachen Sie diese Lösung <strong>für</strong> denn Fall, dass nur das spezielle Bitmuster<br />
M="01111110" erkannt werden soll.<br />
Y = q 7·q 6·q 5·q 4·q 3·q 2·q 1·q 0<br />
Y
Frage 2 a) Entwickeln Sie das komplette Zustandsübergangsdiagramm des Moore-<br />
9 Punkte Automaten.<br />
1<br />
start<br />
Y=0<br />
0<br />
0<br />
0<br />
0<br />
0<br />
0<br />
0<br />
1<br />
1<br />
A<br />
Y=0<br />
1<br />
B<br />
Y=0<br />
1<br />
C<br />
Y=0<br />
1<br />
D<br />
Y=0<br />
1<br />
E<br />
Y=0<br />
1<br />
F<br />
Y=0<br />
1<br />
G<br />
Y=0<br />
0<br />
H<br />
Y=1<br />
0<br />
b) Wie viele Zustände benötigt der Moore-Automat? Wie viele Flipflops sind<br />
demnach zur Realisierung mindestens notwendig?<br />
Zustände: 9<br />
FlipFlops: 4 (ld9 = 3,17)<br />
Frage 3<br />
3 Punkte<br />
Wie viele Zustände würde eine Realisierung als Mealy-Automat mindestens<br />
benötigen?<br />
8 Zustände<br />
(Zustand "H" <strong>und</strong> "start" können zu einem Zustand zusammengefasst werden.)<br />
Aufgabe 1 Seite 2
Frage 4<br />
34 Punkte<br />
Realisierung des Moore-Automaten<br />
a) Codieren Sie die Zustände ausgehend vom Startzustand aufsteigend in<br />
binärer Form, wie in der folgenden Tabelle dargestellt.<br />
Zustand Q 3 n+1 Q 2 n+1 Q 1 n+1 Q 0<br />
n+1<br />
start 0 0 0 0<br />
A 0 0 0 1<br />
B 0 0 1 0<br />
C 0 0 1 1<br />
D 0 1 0 0<br />
E 0 1 0 1<br />
F 0 1 1 0<br />
G 0 1 1 1<br />
H 1 0 0 0<br />
b) Geben Sie die Ausgangsfunktion Y des Moore-Automaten an.<br />
Y = Q 3<br />
weil Q 3 nur im Zustand "H" gesetzt ist<br />
Aufgabe 1 Seite 3
c) Beschreiben Sie das Folgeschaltverhalten des Moore-Automaten in Form<br />
einer Wahrheitstabelle.<br />
Zust. X n Q<br />
n<br />
3 Q<br />
n<br />
2 Q<br />
n<br />
1 Q<br />
n<br />
0 Q n+1 3 Q n+1 2 Q n+1 1 Q<br />
n+1<br />
0<br />
start 0 0 0 0 0 0 0 0 1<br />
A 0 0 0 0 1 0 0 0 1<br />
B 0 0 0 1 0 0 0 0 1<br />
C 0 0 0 1 1 0 0 0 1<br />
D 0 0 1 0 0 0 0 0 1<br />
E 0 0 1 0 1 0 0 0 1<br />
F 0 0 1 1 0 0 0 0 1<br />
G 0 0 1 1 1 1 0 0 0<br />
H 0 1 0 0 0 0 0 0 1<br />
- 0 1 0 0 1 x x x x<br />
- 0 1 0 1 x x x x x<br />
- 0 1 1 x x x x x x<br />
start 1 0 0 0 0 0 0 0 0<br />
A 1 0 0 0 1 0 0 1 0<br />
B 1 0 0 1 0 0 0 1 1<br />
C 1 0 0 1 1 0 1 0 0<br />
D 1 0 1 0 0 0 1 0 1<br />
E 1 0 1 0 1 0 1 1 0<br />
F 1 0 1 1 0 0 1 1 1<br />
G 1 0 1 1 1 0 0 0 0<br />
H 1 1 0 0 0 0 0 0 0<br />
- 1 1 0 0 1 x x x x<br />
- 1 1 0 1 x x x x x<br />
- 1 1 1 x x x x x x<br />
d) Ermitteln Sie die Übergangsfunktion <strong>für</strong> das D-Flipflop Q 0 in minimierter<br />
Form. Verwenden Sie ein Karnaugh-Diagramm zur Minimierung.<br />
X<br />
Q 3<br />
Q 2<br />
x x 1 1<br />
x x 0 0<br />
Q 3<br />
1 1 x x<br />
1 0 x x<br />
Q 0<br />
1 1 x x<br />
Q 1<br />
Q 0 n+1 = (XQ 2 +XQ 1 +Q 1 Q 0 +Q 2 Q 0 ) n<br />
x x 0 0<br />
0 x 1 0<br />
1 1 x 1<br />
Q 1<br />
Aufgabe 1 Seite 4
e) Geben Sie die Übergangsfunktionen der anderen D-Flipflops Q n-1 …Q 1 in<br />
minimierter Form an. Minimieren Sie die Übergangsfunktionen mit Hilfe<br />
der Axiome <strong>und</strong> Sätze der Schaltalgebra.<br />
Q 1 n+1 =XQ 3 Q 2 Q 1 Q 0 + XQ 3 Q 2 Q 1 Q 0 + XQ 3 Q 2 Q 1 Q 0 + XQ 3 Q 2 Q 1 Q 0<br />
=XQ 3 Q 1 Q 0 + XQ 3 Q 1 Q 0 + XQ 3 Q 1 Q 0 + XQ 3 Q 1 Q 0<br />
=XQ 1 Q 0 + XQ 1 Q 0<br />
don’t cares<br />
Q n+1 2 =XQ 3 Q 2 Q 1 Q 0 + XQ 3 Q 2 Q 1 Q 0 + XQ 3 Q 2 Q 1 Q 0 + XQ 3 Q 2 Q 1 Q 0<br />
=XQ 3 Q 2 Q 1 Q 0 + XQ 3 Q 2 Q 1 + XQ 3 Q 2 Q 0<br />
+ XQ 3 Q 2 Q 1 Q 0 + XQ 3 Q 2 Q 1 + XQ 3 Q 2 Q 0 don’t cares<br />
=XQ 2 Q 1 Q 0 + XQ 2 Q 1 + XQ 2 Q 0<br />
Q 3 n+1 = XQ 3 Q 2 Q 1 Q 0 + XQ 3 Q 2 Q 1 Q 0<br />
= XQ 2 Q 1 Q 0 don’t cares<br />
Aufgabe 1 Seite 5
Aufgabe 2<br />
IKR-CISC Modellprozessor: Assemblerprogrammierung<br />
Frage 1 a) Geben Sie die Assemblerbefehlszeile an, mit welcher der Inhalt des Feldes<br />
3 Punkte LEN in myArray ausgelesen <strong>und</strong> in Register D0 geschrieben wird. Die<br />
Startadresse von myArray sei in Adressregister A0 abgelegt.<br />
MOVE (2,A0),D0<br />
b) Geben Sie die genaue Bezeichnung der verwendeten Adressierungsart an.<br />
Adressregister indirekt mit Offset<br />
Frage 2<br />
6 Punkte<br />
Schreiben Sie die Routine ARRAY_GET. Falls der Index auf einen Wert außerhalb<br />
des Arrays verweist, soll in D1 der Wert 1 zurückgegeben werden.<br />
ARRAY_GET: CMP (2,A0),D0 ;Index zu groß?<br />
BCC ARRAY_ERROR ;CC? = Higher or Same?<br />
LSL D0<br />
;Byte-Index berechnen<br />
MOVE (4,A0,D0),D0 ;Datenwert auslesen<br />
CLR D1<br />
;Fehlerflag loeschen<br />
RTS<br />
ARRAY_ERROR: MOVE #1,D1<br />
RTS<br />
;Fehlerflag setzen<br />
Frage 3<br />
9 Punkte<br />
Schreiben Sie die vollständige Routine LLIST_GET.<br />
LLIST_GET: MOVE (2,A0),A0 ;A0 := HEAD<br />
LLIST_LOOP: CMP #0,A0 ;Element-Adresse = 0 ?<br />
BEQ LLIST_ERROR<br />
TST D0<br />
;Position erreicht?<br />
BEQ LLIST_FOUND<br />
SUB #1,D0<br />
;Zaehler dekrementieren<br />
MOVE (2,A0),A0 ;A0 := NEXT<br />
BRA LLIST_LOOP<br />
LLIST_FOUND: MOVE (4,A0),D0 ;VALUE auslesen<br />
CLR D1<br />
;Fehlerflag loeschen<br />
RTS<br />
LLIST_ERROR: MOVE #1,D1<br />
RTS<br />
;Fehlerflag setzen<br />
Aufgabe 2 Seite 6
Frage 4<br />
13 Punkte<br />
Schreiben Sie das Unterprogramm SUM3.<br />
SUM3: MOVE D2,-(SP) ;Register sichern<br />
MOVE A2,-(SP)<br />
MOVE (A0),A1<br />
MOVE (8,A1),A2<br />
;A1 := Klassenpointer<br />
;A2 := Pointer auf GET<br />
CLR D0 ;Position 0<br />
MOVE A0,-(SP) ;A0 sichern<br />
JSR (A2)<br />
;dynamischer Aufruf GET<br />
TST D1<br />
;Fehler?<br />
BNE SUM3_END<br />
MOVE D0,D2 ;D2 = Summe<br />
MOVE #1,D0 ;Position 1<br />
MOVE (SP),A0 ;A0 wiederherstellen<br />
JSR (A2)<br />
;dynamischer Aufruf GET<br />
TST D1<br />
;Fehler?<br />
BNE SUM3_END<br />
ADD D0,D2 ;zu Summe addieren<br />
MOVE #2,D0 ;Position 2<br />
MOVE (SP),A0 ;A0 wiederherstellen<br />
JSR (A2)<br />
;dynamischer Aufruf GET<br />
TST D1<br />
;Fehler?<br />
BNE SUM3_END<br />
ADD D2,D0 ;Summe hinzuaddieren<br />
SUM3_END: ADD #2,SP ;gesichertes A0 loeschen<br />
MOVE (SP)+,A2 ;Register wiederherst.<br />
MOVE (SP)+,D2<br />
RTS<br />
Aufgabe 2 Seite 7
Aufgabe 3<br />
Direct-Mapped Cache<br />
Frage 1<br />
2 Punkte<br />
Was bedeutet "Cache Hit"? Was bedeutet "Cache Miss"?<br />
Cache Hit: adressiertes Datum im Cache enthalten<br />
Cache Miss: adressiertes Datum nicht im Cache enthalten<br />
Frage 2 a) Geben Sie die Breite W einer Cache-Zeile in Byte sowie die Tiefe D des<br />
7 Punkte Cache-Speichers in Cache-Zeilen an.<br />
W = 2 (Bitbreite Offset) Bytes = 2 3 Bytes = 8 Bytes<br />
D = 2 (Bitbreite Index) Zeilen = 2 7 Zeilen = 128 Zeilen<br />
b) Geben Sie die Kapazität des Cache in Byte an.<br />
Kapazität = D·W = 1024 Bytes = 1 kByte<br />
c) Welche zusätzlichen Informationen müssen pro Cachezeile gespeichert werden?<br />
Wieviele Bits E werden hier<strong>für</strong> pro Zeile benötigt? Gehen Sie davon<br />
aus, dass ein Dirty-Bit pro Wort gespeichert werden soll.<br />
Tag:<br />
Valid-Bit:<br />
Dirty-Bits:<br />
Gesamt:<br />
6 Bit pro Zeile<br />
1 Bit pro Zeile<br />
4 Bit pro Zeile (da 1 Bit pro Wort)<br />
E = 11 Bit pro Zeile<br />
Aufgabe 3 Seite 8
Frage 3<br />
10 Punkte<br />
a) Skizzieren Sie, wie der Speicher <strong>für</strong> die Nutzdaten <strong>und</strong> der Speicher mit den<br />
Zusatzinformationen (Tag, Dirty-Bits, etc.) <strong>für</strong> Lesezugriffe beschaltet werden<br />
muss. Verwenden Sie hier<strong>für</strong> zusätzlich Elemente der Register-Transfer-Ebene.<br />
[0]<br />
3<br />
[2..1]<br />
Tag Index Offset<br />
rd_addr N<br />
rd_addr Z<br />
7 64 rd_data N 16<br />
Nutzdaten-<br />
Speicher<br />
7 11 Valid<br />
Tag-, Valid-,<br />
Dirty-Bit- rd_data N<br />
6<br />
Speicher<br />
Tag c<br />
6<br />
=?<br />
&<br />
equal<br />
DATA<br />
MISS<br />
b) Erläutern Sie die Funktionsweise des Direct-Mapped Cache im Falle eines<br />
solchen Lesevorgangs. Gehen Sie dabei auf die Bedeutung der Bereiche<br />
Tag, Index <strong>und</strong> Offset ein.<br />
Der Index adressiert die beiden Speicher zum Auslesen der Nutzdaten<br />
sowie der Zusatzinformationen der entsprechenden Cachezeile.<br />
Der Offset wählt danach über einen Multiplexer das gewünschte Wort aus<br />
den vier ausgelesenen Worten der Cachezeile aus.<br />
Parallel dazu vergleicht ein Komparator den angelegten Tag mit dem ausgelesenen<br />
Tag. Sind die Tags identisch <strong>und</strong> ist außerdem das Valid-Bit gesetzt,<br />
war das geforderte Wort im Cache enthalten <strong>und</strong> liegt am Ausgang des Multiplexers<br />
an (Cache Hit, MISS=0).<br />
Aufgabe 3 Seite 9
Frage 4 Skizzieren Sie die Schaltung, um die der Lese-Ausgang des Cache aus Frage 3<br />
6 Punkte ergänzt werden muss. Verwenden Sie hier<strong>für</strong> Multiplexer <strong>und</strong> Verdrahtungsschemata<br />
jeweils unter Angabe der angeschlossenen Bits, z.B.<br />
15..0 15..8<br />
7..0<br />
<strong>und</strong><br />
15..8 15..0<br />
7..0<br />
Minimale Schaltung:<br />
WORD<br />
$00<br />
0<br />
15..0<br />
15..8<br />
1<br />
15..8<br />
15..0<br />
7..0<br />
0<br />
7..0<br />
1<br />
≥1<br />
Offset(0)<br />
WORD<br />
Alternative Schaltung:<br />
15..0<br />
15..8<br />
7..0<br />
Offset(0)<br />
0 $00<br />
1<br />
15..8<br />
7..0<br />
15..0<br />
WORD<br />
0 15..0<br />
1<br />
Frage 5<br />
4 Punkte<br />
Warum wird bei einem Cache mit "pipelined write" Forwarding benötigt?<br />
Daten, deren Schreibvorgang im Takt n beginnt, werden erst am Ende des Taktintervalls<br />
n+1 in den Nutzdaten-Speicher des Cache geschrieben.<br />
Um im Takt n+1 diese Daten bereits auslesen zu können, müssen diese durch<br />
Forwarding aus dem Pipeline-Register in die erste Stufe geleitet werden.<br />
Aufgabe 3 Seite 10
Frage 6 a) Welche Daten <strong>und</strong> Signale werden im zweiten Takt eines Schreibvorgangs<br />
19 Punkte benötigt <strong>und</strong> müssen daher in einem Pipeline-Register gespeichert werden?<br />
• Index<br />
• wr_wena<br />
• zu schreibende Daten WrData<br />
• ausgelesene Zusatzinformationen (Tag, Dirty-Bits, Valid-Bit)<br />
b) Entwerfen <strong>und</strong> zeichnen Sie den Aufbau des Cache auf Register-Transfer-<br />
Ebene. Die Lösungen aus Frage 3 <strong>und</strong> Frage 4 können hierbei wiederverwendet<br />
werden <strong>und</strong> müssen nicht mehr im Detail gezeichnet werden.<br />
In der Zeichnung sollten alle notwendigen Daten- <strong>und</strong> Steuerleitungen enthalten<br />
<strong>und</strong> beschriftet sein. Logische Verknüpfungen auf Gatterebene (z.B.<br />
zum Setzen eines Dirty-Bits) können abstrahiert als Block mit aussagekräftigem<br />
Namen gezeichnet werden.<br />
Hinweis: Die Signale wr_wena <strong>und</strong> wr_data <strong>für</strong> den Nutzdaten-Speicher<br />
sowie wr_data <strong>für</strong> den Speicher mit den Zusatzinformationen<br />
können nicht direkt angeschlossen werden, sondern müssen aus<br />
anderen Signalen generiert werden.<br />
4<br />
64<br />
Index 1<br />
Mux &<br />
Byte-<br />
Select<br />
rd_addr<br />
wr_addr<br />
wr_wena<br />
wr_data<br />
Nutzdaten-<br />
Speicher<br />
WORD 1<br />
Offset 1<br />
64<br />
Frage 3+4<br />
RdData<br />
16<br />
WrData 1<br />
WRDATA 2<br />
Offset 1<br />
Create wr_wena 4<br />
1<br />
MODE 1 wr_wena<br />
wr_wena 2<br />
16<br />
16<br />
16<br />
16<br />
16<br />
≥1<br />
rd_addr<br />
wr_addr<br />
wr_wena<br />
wr_data<br />
Tag-,<br />
Valid-Bit-,<br />
Dirty-Bit-,<br />
Speicher<br />
Tag, Valid<br />
11<br />
Tag,Valid-,Dirty-Bits 1<br />
MISS<br />
Hit or Index 1<br />
Miss?<br />
Tag,Val,Dirty 2<br />
Index 2<br />
Set<br />
Dirty-B.<br />
Frage 3<br />
7<br />
11<br />
1<br />
Signale mit Index 1 sind Signale der ersten Stufe (d.h. vor dem<br />
Pipeline-Register), Signale mit Index 2 sind Signale der zweiten Stufe.<br />
Aufgabe 3 Seite 11
Frage 7<br />
8 Punkte<br />
Ergänzen Sie die Zeichnung aus Frage 6 um einen Forwarding-Multiplexer <strong>für</strong><br />
den Fall eines Lesezugriffs nach einem Wort-Schreibzugriff auf dieselbe Adresse.<br />
Geben Sie in einer gesonderten Skizze die Ansteuerlogik <strong>für</strong> den Forwarding-<br />
Multiplexer an.<br />
4<br />
64<br />
Index 1<br />
wr_addr<br />
wr_wena<br />
wr_data<br />
Ansteuerung<br />
siehe unten<br />
Mux &<br />
Byte-<br />
Select<br />
rd_addr<br />
Nutzdaten-<br />
Speicher<br />
WORD 1<br />
Offset 1<br />
1<br />
0<br />
Frage 3+4<br />
RdData<br />
16<br />
WrData 1<br />
WRDATA 2<br />
Offset 1<br />
Create wr_wena 4<br />
1<br />
MODE 1 wr_wena<br />
wr_wena 2<br />
16<br />
16<br />
16<br />
16<br />
16<br />
≥1<br />
rd_addr<br />
wr_addr<br />
wr_wena<br />
wr_data<br />
Tag-,<br />
Valid-Bit-,<br />
Dirty-Bit-,<br />
Speicher<br />
Tag, Valid<br />
11<br />
Tag,Valid-,Dirty-Bits 1<br />
MISS<br />
Hit or Index 1<br />
Miss?<br />
Tag,Val,Dirty 2<br />
Index 2<br />
Set<br />
Dirty-B.<br />
Frage 3<br />
7<br />
11<br />
1<br />
Ansteuerung des Forwarding-Multiplexers<br />
(<strong>für</strong> Lesezugriff nach Wort-Schreibzugriff):<br />
MODE 1 [0]<br />
MODE 1 [1]<br />
&<br />
read 1<br />
&<br />
equal<br />
write 2<br />
≥1<br />
wr_wena 2 [3..0]<br />
wr_wena 2<br />
Address 1 [15..1]<br />
CMP<br />
Address 2 [15..1]<br />
Address 2<br />
Aufgabe 3 Seite 12
Frage 8 a) Wie muss die Schaltung aus Frage 6 (ohne Forwarding) hier<strong>für</strong> ergänzt<br />
9 Punkte werden? Es wird keine Skizze verlangt.<br />
• Im ersten Takt des Schreibvorgangs muss auch das zu verändernde<br />
Wort aus dem Nutzdatenspeicher ausgelesen werden.<br />
• Im zweiten Takt muss abhängig von Offset(0) das zu schreibende Wort<br />
aus dem ausgelesenen Wort <strong>und</strong> dem zu schreibenden Byte zusammengestellt<br />
werden.<br />
• Das erstellte Wort kann nun wie in Frage 6 in den Speicher geschrieben<br />
werden.<br />
• Der Rest kann unverändert bleiben.<br />
b) Wie muss die Forwarding-Logik aus Frage 7 ergänzt werden? Es wird wiederum<br />
keine Skizze verlangt.<br />
Das zusammengestellte Wort – aus a) zweiter Punkt – muss zum Forwarding-Multiplexer<br />
geleitet werden. Sonst sind keine Änderungen notwendig.<br />
Aufgabe 3 Seite 13
Aufgabe 4<br />
Virtueller Speicher<br />
Frage 1<br />
2 Punkte<br />
Nennen Sie die zwei wesentlichen Probleme, die durch den Einsatz von virtuellem<br />
Speicher gelöst werden.<br />
Begrenzte Kapazität des Arbeitsspeichers<br />
Fehlender Schutz innerhalb des Arbeitsspeichers<br />
Frage 2 a) Bei Paging tritt interne Fragmentierung auf. Was versteht man darunter?<br />
4 Punkte<br />
Es gibt Speicherblöcke, die nur teilweise belegt sind. Der unbelegte Speicher<br />
innerhalb dieser Blöcke kann nicht mehr genutzt werden.<br />
b) Welche andere Art der Fragmentierung gibt es noch? Geben Sie ein Beispiel,<br />
wo diese Art der Fragmentierung auftritt.<br />
Externe Fragmentierung<br />
Beispiel: Speicherverwaltung mit variabler Blockgröße<br />
Frage 3<br />
4 Punkte<br />
Frage 4<br />
2 Punkte<br />
Frage 5<br />
4 Punkte<br />
Geben Sie die Breite von Offset, Seitennummer <strong>und</strong> Rahmennummer in Bit an.<br />
Offset:<br />
Seitennummer:<br />
12bit<br />
20bit<br />
Rahmennummer: 20bit<br />
Wie viel Speicherplatz benötigt eine vollständige Seitentabelle?<br />
2 20·32bit = 2 20·2 2 byte = 4MByte<br />
Nennen Sie einen Vorteil <strong>und</strong> einen Nachteil der mehrstufigen tabellenbasierten<br />
Adressumsetzung. Begründen Sie diese jeweils stichwortartig.<br />
Vorteil: geringerer Speicherbedarf <strong>für</strong> Seitentabelle<br />
unvollständiger Baum belegt trotz Zwischenebenen wesentlich weniger<br />
Speicherplatz als vollständige Seitentabelle<br />
Nachteil: höhere Zugriffszeit<br />
ein Tabellenzugriff erfordert mehrere Speicherzugriffe<br />
Frage 6 a) Wie groß ist die Tabelle der ersten Stufe <strong>und</strong> eine Teiltabelle der zweiten<br />
5 Punkte Stufe jeweils?<br />
Seitentabelle der ersten Stufe:<br />
Teiltabelle der zweiten Stufe:<br />
2 10·32bit = 4KByte<br />
2 10·32bit = 4KByte<br />
Hinweis: Da es sich hier um ein 32-Bit-System handelt, wird die Breite des<br />
Eintrags einer Seitentabelle der ersten Stufen mit 32bit angenommen. Mindestens<br />
werden 22 bit <strong>für</strong> die Adressierung einer Tabelle der zweiten Stufe<br />
<strong>und</strong> 1 Valid-Bit benötigt.<br />
b) Welchen Vorteil hat diese Teiltabellengröße?<br />
Eine Tabelle füllt exakt einen Rahmen.<br />
Aufgabe 4 Seite 14
Frage 7 a) Geben Sie die Seitennummern der belegten virtuellen Seiten an.<br />
18 Punkte<br />
$00002, $00003, $00004<br />
$F07FE, $F07FF, $F0800, $F0801<br />
b) Geben Sie jeweils die zugehörigen physikalischen Rahmennummern an.<br />
$55551, $55552, $55553<br />
$ABCD2, $ABCD3, $ABCD4, $ABCD5<br />
c) Skizzieren Sie die zweistufige Seitentabelle (vgl. Skript Kapitel 6.3<br />
Blatt 12, unten) <strong>für</strong> den vorliegenden Fall. Geben Sie dabei den Inhalt aller<br />
verwendeten Einträge an.<br />
Valid-Bit<br />
Tabellen Ebene 2<br />
Tabellen Ebene 1<br />
$001<br />
$000<br />
1<br />
1<br />
$ABCD5<br />
$ABCD4<br />
Valid-Bit<br />
$3C2<br />
$3C1<br />
1<br />
1<br />
$3FF<br />
$3FE<br />
1<br />
1<br />
$ABCD3<br />
$ABCD2<br />
$000<br />
1<br />
$004<br />
$003<br />
$002<br />
1<br />
1<br />
1<br />
$55553<br />
$55552<br />
$55551<br />
Frage 8 a) Wie viel Speicherplatz belegt die zweistufige Seitentabelle (d.h. inklusive<br />
6 Punkte aller Teiltabellen) im schlimmsten Fall?<br />
(1 + 2 10 )·4KByte = 4,004MByte<br />
b) Wann tritt dieser schlimmste Fall ein?<br />
Dieser schlimmste Fall tritt ein, wenn alle Teiltabellen der 2. Stufe angelegt<br />
werden müssen. Dazu muss ein Programm pro Teiltabelle der 2. Stufe auf<br />
mindestens ein Wort in einer Seite zugreifen.<br />
(Das entspricht mindestens 2 10 Speicherzugriffen, da 2 10 Teiltabellen der<br />
2. Stufe existieren.)<br />
Aufgabe 4 Seite 15
Frage 9<br />
3 Punkte<br />
Frage 10<br />
4 Punkte<br />
Warum kann dieser Cache deutlich kleiner ausgelegt werden als ein Daten- bzw.<br />
Befehlscache?<br />
Jeder Eintrag deckt den Adressbereich einer ganzen Seite ab.<br />
Programme greifen in einem betrachteten Zeitintervall nur auf eine kleine Untermenge<br />
der virtuellen Seiten zu (örtliche <strong>und</strong> zeitliche Lokalität).<br />
Welchen wesentlichen Vorteil hat ein Physically Addressed Cache gegenüber<br />
einem Virtually Addressed Cache?<br />
Ein Virtually Addressed Cache muss bei einem Wechsel des virtuellen Adressraums<br />
(Kontext-Switch) vollständig gelöscht werden. Beim Physically Adressed<br />
Cache ist das nicht notwendig.<br />
Frage 11<br />
8 Punkte<br />
a) Nennen Sie die Voraussetzung hier<strong>für</strong> <strong>und</strong> geben Sie ein Beispiel an.<br />
Zur Adressierung des Caches werden nur Index <strong>und</strong> Offset benötigt. Sind<br />
beide im Seitenoffset der virtuellen Adresse enthalten, so kann sofort auf<br />
den Cache zugegriffen werden. Hierzu muss folgende Bedingung erfüllt<br />
sein:<br />
Breite Seiten-/Rahmenoffset ≥ Breite Cache-Index + Breite Cache-Line-<br />
Offset<br />
Beispiel:<br />
31bit<br />
12bit<br />
virtuelle Adresse Seitennummer Seitenoffset<br />
physikalische Adresse<br />
20bit<br />
Rahmennummer<br />
12bit<br />
Rahmenoffset<br />
physikalische Adresse<br />
21bit<br />
Tag<br />
8bit<br />
Index<br />
3bit<br />
CLO<br />
b) Welche Abhängigkeit ergibt sich daraus <strong>für</strong> die Dimensionierung eines<br />
Direct-Mapped Daten- bzw. Befehlscache?<br />
Ein Direct-Mapped Cache kann nicht größer ausgelegt werden als die<br />
Seiten-/Rahmengröße.<br />
Aufgabe 4 Seite 16













