

A Framework for Evaluating Early-Stage Human - of Marcus Hutter
A Framework for Evaluating Early-Stage Human - of Marcus Hutter
A Framework for Evaluating Early-Stage Human - of Marcus Hutter

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
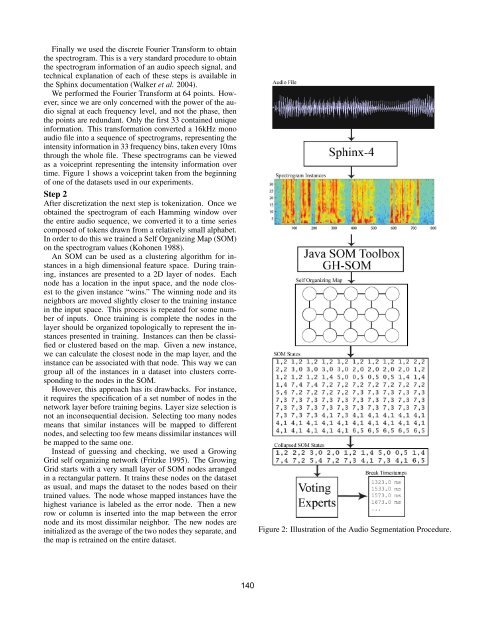
FinallyweusedthediscreteFourierTrans<strong>for</strong>mtoobtain<br />
thespectrogram.Thisisaverystandardproceduretoobtain<br />
thespectrogramin<strong>for</strong>mation<strong>of</strong>anaudiospeechsignal,and<br />
technicalexplanation<strong>of</strong>each<strong>of</strong>thesestepsisavailablein<br />
theSphinxdocumentation(Walkeretal.2004).<br />
Weper<strong>for</strong>medtheFourierTrans<strong>for</strong>mat64points.However,sinceweareonlyconcernedwiththepower<strong>of</strong>theaudiosignalateachfrequencylevel,andnotthephase,then<br />
thepointsareredundant.Onlythefirst33containedunique<br />
in<strong>for</strong>mation.Thistrans<strong>for</strong>mationconverteda16kHzmono<br />
audi<strong>of</strong>ileintoasequence<strong>of</strong>spectrograms,representingthe<br />
intensityin<strong>for</strong>mationin33frequencybins,takenevery10ms<br />
throughthewholefile. Thesespectrogramscanbeviewed<br />
asavoiceprintrepresentingtheintensityin<strong>for</strong>mationover<br />
time.Figure1showsavoiceprinttakenfromthebeginning<br />
<strong>of</strong>one<strong>of</strong>thedatasetsusedinourexperiments.<br />
Step2<br />
Afterdiscretizationthenextstepistokenization. Oncewe<br />
obtainedthespectrogram<strong>of</strong>eachHammingwindowover<br />
theentireaudiosequence,weconvertedittoatimeseries<br />
composed<strong>of</strong>tokensdrawnfromarelativelysmallalphabet.<br />
InordertodothiswetrainedaSelfOrganizingMap(SOM)<br />
onthespectrogramvalues(Kohonen1988).<br />
AnSOMcanbeusedasaclusteringalgorithm<strong>for</strong>instancesinahighdimensionalfeaturespace.Duringtraining,instancesarepresentedtoa2Dlayer<strong>of</strong>nodes.<br />
Each<br />
nodehasalocationintheinputspace,andthenodeclosesttothegiveninstance“wins.”Thewinningnodeandits<br />
neighborsaremovedslightlyclosertothetraininginstance<br />
intheinputspace.Thisprocessisrepeated<strong>for</strong>somenumber<strong>of</strong>inputs.<br />
Oncetrainingiscompletethenodesinthe<br />
layershouldbeorganizedtopologicallytorepresenttheinstancespresentedintraining.Instancescanthenbeclassifiedorclusteredbasedonthemap.<br />
Givenanewinstance,<br />
wecancalculatetheclosestnodeinthemaplayer,andthe<br />
instancecanbeassociatedwiththatnode.Thiswaywecan<br />
groupall<strong>of</strong>theinstancesinadatasetintoclusterscorrespondingtothenodesintheSOM.<br />
However,thisapproachhasitsdrawbacks.Forinstance,<br />
itrequiresthespecification<strong>of</strong>asetnumber<strong>of</strong>nodesinthe<br />
networklayerbe<strong>for</strong>etrainingbegins.Layersizeselectionis<br />
notaninconsequentialdecision.Selectingtoomanynodes<br />
meansthatsimilarinstanceswillbemappedtodifferent<br />
nodes,andselectingto<strong>of</strong>ewmeansdissimilarinstanceswill<br />
bemappedtothesameone.<br />
Instead<strong>of</strong>guessingandchecking,weusedaGrowing<br />
Gridsel<strong>for</strong>ganizingnetwork(Fritzke1995).TheGrowing<br />
Gridstartswithaverysmalllayer<strong>of</strong>SOMnodesarranged<br />
inarectangularpattern.Ittrainsthesenodesonthedataset<br />
asusual,andmapsthedatasettothenodesbasedontheir<br />
trainedvalues.Thenodewhosemappedinstanceshavethe<br />
highestvarianceislabeledastheerrornode. Thenanew<br />
roworcolumnisinsertedintothemapbetweentheerror<br />
nodeanditsmostdissimilarneighbor. Thenewnodesare<br />
initializedastheaverage<strong>of</strong>thetwonodestheyseparate,and<br />
themapisretrainedontheentiredataset.<br />
140<br />
Figure2:Illustration<strong>of</strong>theAudioSegmentationProcedure.










