- Page 1 and 2: Proceedings of the 2nd Internationa
- Page 3 and 4: Contents Paper Title Author(s) Page
- Page 5 and 6: Paper Title Author(s) Page No. The
- Page 7 and 8: Preface Following on from the conti
- Page 9 and 10: Idisemi Apulu is currently a PhD st
- Page 11 and 12: Waldo Rocha Flores received his B.S
- Page 13: Ari Riabacke, Ph.D. in Risk- and De
- Page 16 and 17: 2. Mental health care services in U
- Page 18 and 19: Kwesi Korsa Aggrey One possibility
- Page 20 and 21: Kwesi Korsa Aggrey generate mutual
- Page 22 and 23: Kwesi Korsa Aggrey Stacey, R. (2006
- Page 24 and 25: Jaflah Al-Ammary technology and man
- Page 26 and 27: 3.3.1 Computer self efficacy Jaflah
- Page 28 and 29: Jaflah Al-Ammary Teacher Percentage
- Page 30 and 31: Jaflah Al-Ammary both perceived use
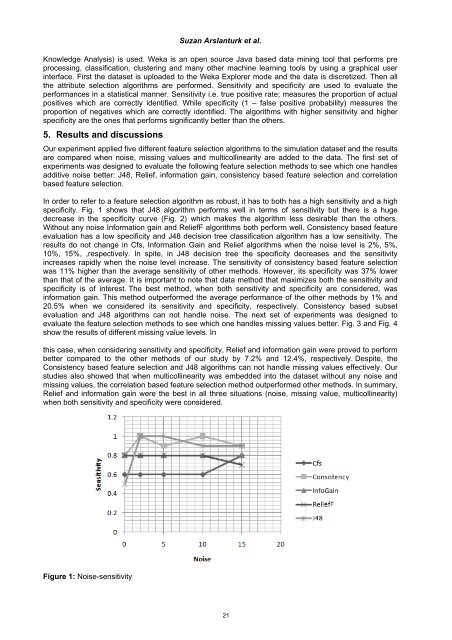
- Page 32 and 33: Comparison of Feature Selection Tec
- Page 36 and 37: Figure 2: Noise - specificity Figur
- Page 38 and 39: A Delphi-Multi-Criteria Decision Ma
- Page 40 and 41: Tridip Bardhan et al. evaluating di
- Page 42 and 43: Tridip Bardhan et al. major integra
- Page 44 and 45: Tridip Bardhan et al. Figure 3: Int
- Page 46 and 47: Where Tridip Bardhan et al. RI = co
- Page 48 and 49: Figure 8: Stochastic (weighted) sup
- Page 50 and 51: Tridip Bardhan et al. Figure 11: Cr
- Page 52 and 53: Selection, Implementation and Post
- Page 54 and 55: Imran Batada and Asmita Rahman requ
- Page 56 and 57: 8. ERP implementation process Imran
- Page 58 and 59: 11. Post production of an ERP syste
- Page 60 and 61: 2. Literature review Clara Benevolo
- Page 62 and 63: Clara Benevolo and Renata Paola Dam
- Page 64 and 65: Clara Benevolo and Renata Paola Dam
- Page 66 and 67: Clara Benevolo and Renata Paola Dam
- Page 68 and 69: ICTs as Weapons of Mass Interaction
- Page 70 and 71: Kofi Agyenim Boateng suitability of
- Page 72 and 73: Kofi Agyenim Boateng From the viewp
- Page 74 and 75: Kofi Agyenim Boateng effect of empl
- Page 76 and 77: Investigating the Factors Inhibitin
- Page 78 and 79: Gino Bougaardt and Michael Kyobe ba
- Page 80 and 81: Gino Bougaardt and Michael Kyobe ad
- Page 82 and 83: Table 3: Assessment of reliability
- Page 84 and 85:
Gino Bougaardt and Michael Kyobe Mo
- Page 86 and 87:
Sharing knowledge - The CoP way She
- Page 88 and 89:
Sheryl Buckley and Apostolos Gianna
- Page 90 and 91:
Table 1: Informing participants abo
- Page 92 and 93:
Sheryl Buckley and Apostolos Gianna
- Page 94 and 95:
References Sheryl Buckley and Apost
- Page 96 and 97:
An Empirical Framework of key Succe
- Page 98 and 99:
Nuntarat Bunditwongrat et al. for S
- Page 100 and 101:
3.4 Organizational size Nuntarat Bu
- Page 102 and 103:
Nuntarat Bunditwongrat et al. Measu
- Page 104 and 105:
Nuntarat Bunditwongrat et al. depth
- Page 106 and 107:
Andy Bytheway managers' willingness
- Page 108 and 109:
Andy Bytheway However, this notion
- Page 110 and 111:
Andy Bytheway rational, right-brain
- Page 112 and 113:
Figure 6: The results for the refer
- Page 114 and 115:
Andy Bytheway available to the mana
- Page 116 and 117:
Andy Bytheway DeLone, W. & McLean,
- Page 118 and 119:
Supaporn Chai-Arayalert and Keiichi
- Page 120 and 121:
3.2 Peirce’s triadic model of sem
- Page 122 and 123:
Supaporn Chai-Arayalert and Keiichi
- Page 124 and 125:
Supaporn Chai-Arayalert and Keiichi
- Page 126 and 127:
Exploring the Emotional Exhaustion
- Page 128 and 129:
Cheng-Yi Chiang et al. 3. “Perce
- Page 130 and 131:
Cheng-Yi Chiang et al. minutes will
- Page 132 and 133:
Cheng-Yi Chiang et al. the motivati
- Page 134 and 135:
The Implementation of RSS-Based Cli
- Page 136 and 137:
Wen-Chou Chi et al. database server
- Page 138 and 139:
Wen-Chou Chi et al. Figure 4: An ex
- Page 140 and 141:
6. Conclusion Wen-Chou Chi et al. R
- Page 142 and 143:
Taurai Chikotie et al. factors espe
- Page 144 and 145:
Taurai Chikotie et al. Figure 1: Pr
- Page 146 and 147:
Taurai Chikotie et al. Herselman, 2
- Page 148 and 149:
Evaluation of Application Embedded
- Page 150 and 151:
Mitchell Cochran the level of knowl
- Page 152 and 153:
Mitchell Cochran reporting system i
- Page 154 and 155:
Mitchell Cochran However, as the ap
- Page 156 and 157:
Michael Cox et al. suggest that you
- Page 158 and 159:
Michael Cox et al. Council Descript
- Page 160 and 161:
Recruitment Issues Flexibility Focu
- Page 162 and 163:
5. Conclusion Michael Cox et al. Th
- Page 164 and 165:
Documenting Innovation: A Methodolo
- Page 166 and 167:
Stefano De Falco These applications
- Page 168 and 169:
1) Buying (e-Sourcing, e-Catalog) S
- Page 170 and 171:
Stefano De Falco 2) operational ac
- Page 172 and 173:
Stefano De Falco management and e-l
- Page 174 and 175:
Stefano De Falco The pursuit of thi
- Page 176 and 177:
Nomusa Dlodlo users, which is alloc
- Page 178 and 179:
Nomusa Dlodlo Virtualisation is the
- Page 180 and 181:
7. Regulatory issues Nomusa Dlodlo
- Page 182 and 183:
Nomusa Dlodlo 1. Privileged user a
- Page 184 and 185:
Badr Elmir et al. delivery. Finally
- Page 186 and 187:
Badr Elmir et al. The Enterprise Ar
- Page 188 and 189:
3.4 Delineating the scope of the st
- Page 190 and 191:
Badr Elmir et al. The metamodel is
- Page 192 and 193:
Badr Elmir et al. oriented eService
- Page 194 and 195:
Badr Elmir et al. Gupta, K.M., Zang
- Page 196 and 197:
Turan Erman Erkan company a real-ti
- Page 198 and 199:
Turan Erman Erkan In this phase you
- Page 200 and 201:
Turan Erman Erkan Bingi, P. S. Shar
- Page 202 and 203:
Francesc Estanyol The objectives of
- Page 204 and 205:
Francesc Estanyol Co-evolution. De
- Page 206 and 207:
Francesc Estanyol Government regul
- Page 208 and 209:
Francesc Estanyol Finally, a positi
- Page 210 and 211:
Ideas About Profitability in Resear
- Page 212 and 213:
Albrecht Fritzsche As the genetic m
- Page 214 and 215:
Albrecht Fritzsche later turn out t
- Page 216 and 217:
Albrecht Fritzsche on the solutions
- Page 218 and 219:
Case Study on Information Evaluatio
- Page 220 and 221:
Hiroatsu Fukuda et al. As shown in
- Page 222 and 223:
4.3 Share-ride taxi Hiroatsu Fukuda
- Page 224 and 225:
Hiroatsu Fukuda et al. After 10 yea
- Page 226 and 227:
Hiroatsu Fukuda et al. Commerce: co
- Page 228 and 229:
Distortion Free Algorithm to Handle
- Page 230 and 231:
Sajid Iqbal et al. have more precis
- Page 232 and 233:
Table: 1. Notations used in this pa
- Page 234 and 235:
Sajid Iqbal et al. In our experimen
- Page 236 and 237:
Engineering Change Through the Doma
- Page 238 and 239:
3. Analysis of the case studies Tik
- Page 240 and 241:
Tiko Iyamu between the business and
- Page 242 and 243:
5.5 Strategic alignment Tiko Iyamu
- Page 244 and 245:
Tiko Iyamu Buy of robust applicatio
- Page 246 and 247:
Veit Jahns etc. In general, these a
- Page 248 and 249:
Veit Jahns Social dimension: Here
- Page 250 and 251:
Veit Jahns to complete as task with
- Page 252 and 253:
Veit Jahns Gupta, M. P. and Jana, D
- Page 254 and 255:
1.2 Research objectives Srimal Jaya
- Page 256 and 257:
2.2 Success in Enterprise Systems S
- Page 258 and 259:
2.4.2 Choice set Srimal Jayawardena
- Page 260 and 261:
Trilingual Support Support and Mai
- Page 262 and 263:
Srimal Jayawardena and Gihan Dias c
- Page 264 and 265:
6.3 Licensed software Srimal Jayawa
- Page 266 and 267:
Appendix D Srimal Jayawardena and G
- Page 268 and 269:
Farnoosh Khodakarami and Yolande Ch
- Page 270 and 271:
Farnoosh Khodakarami and Yolande Ch
- Page 272 and 273:
System quality: Customer informatio
- Page 274 and 275:
Farnoosh Khodakarami and Yolande Ch
- Page 276 and 277:
Farnoosh Khodakarami and Yolande Ch
- Page 278 and 279:
Mouhsine Lakhdissi and Bouchaib Bou
- Page 280 and 281:
Mouhsine Lakhdissi and Bouchaib Bou
- Page 282 and 283:
4.1 TOGAF metamodel Mouhsine Lakhdi
- Page 284 and 285:
Function elements: like services or
- Page 286 and 287:
Mouhsine Lakhdissi and Bouchaib Bou
- Page 288 and 289:
Applying Innovative Information Sys
- Page 290 and 291:
3.2 System design and implementatio
- Page 292 and 293:
Chih-Yu Lin et al. The user's satis
- Page 294 and 295:
Chih-Yu Lin et al. The results of t
- Page 296 and 297:
2. Literature review 2.1 Risk manag
- Page 298 and 299:
Chishala Lukwesa and Christopher Up
- Page 300 and 301:
Recommendations Chishala Lukwesa an
- Page 302 and 303:
Poor staff awareness Poor asset id
- Page 304 and 305:
Chishala Lukwesa and Christopher Up
- Page 306 and 307:
Negar Madani et al. management proc
- Page 308 and 309:
Negar Madani et al. Major change:
- Page 310 and 311:
Table 2: An optimized change manage
- Page 312 and 313:
Instructions for determining standa
- Page 314 and 315:
The use of RFID and Web 2.0 Technol
- Page 316 and 317:
Sizakele Mathaba et al. readers, an
- Page 318 and 319:
Fraud and counterfeit products. Siz
- Page 320 and 321:
Sizakele Mathaba et al. (Object Nam
- Page 322 and 323:
Modeling the Genetic Schemes of Hum
- Page 324 and 325:
Fatemeh Mohammadi et al. 1960). But
- Page 326 and 327:
8. Objectives of the model Fatemeh
- Page 328 and 329:
Fatemeh Mohammadi et al. The analys
- Page 330 and 331:
Acknowledgement Fatemeh Mohammadi e
- Page 332 and 333:
Amer Sedeeq Mustafa The detection a
- Page 334 and 335:
Amer Sedeeq Mustafa ⎡1 1 ⎤ H2=
- Page 336 and 337:
Amer Sedeeq Mustafa where n, m are
- Page 338 and 339:
Evaluation of IT Investment Methods
- Page 340 and 341:
Shirin Nasher et al. Nevertheless,
- Page 342 and 343:
Shirin Nasher et al. i.e., operatio
- Page 344 and 345:
Table 3: Evaluation criteria and st
- Page 346 and 347:
Shirin Nasher et al. order to consi
- Page 348 and 349:
Mário Carrilho Negas and Paulo Ram
- Page 350 and 351:
Mário Carrilho Negas and Paulo Ram
- Page 352 and 353:
Mário Carrilho Negas and Paulo Ram
- Page 354 and 355:
Mário Carrilho Negas and Paulo Ram
- Page 356 and 357:
Phathutshedzo Nemutanzhela and Tiko
- Page 358 and 359:
Phathutshedzo Nemutanzhela and Tiko
- Page 360 and 361:
Phathutshedzo Nemutanzhela and Tiko
- Page 362 and 363:
Phathutshedzo Nemutanzhela and Tiko
- Page 364 and 365:
Phathutshedzo Nemutanzhela and Tiko
- Page 366 and 367:
Jonathan Oni et al. Yet, it has bee
- Page 368 and 369:
Jonathan Oni et al. over the years,
- Page 370 and 371:
Jonathan Oni et al. they agreed to
- Page 372 and 373:
Jonathan Oni et al. one organisatio
- Page 374 and 375:
Towards a Comprehensive Evaluation
- Page 376 and 377:
Caroline Pade-Khene and Dave Sewry
- Page 378 and 379:
Caroline Pade-Khene and Dave Sewry
- Page 380 and 381:
Caroline Pade-Khene and Dave Sewry
- Page 382 and 383:
Caroline Pade-Khene and Dave Sewry
- Page 384 and 385:
User Adoption of the New Health Inf
- Page 386 and 387:
Bahlol Rahimi To summarize, social
- Page 388 and 389:
Bahlol Rahimi 2. In fact, perhaps
- Page 390 and 391:
Bahlol Rahimi From another perspect
- Page 392 and 393:
Relationship Between Organizational
- Page 394 and 395:
Farnaz Rahimi and Gholamabas Arabsh
- Page 396 and 397:
Farnaz Rahimi and Gholamabas Arabsh
- Page 398 and 399:
Business Intelligence as Decision S
- Page 400 and 401:
Ari Riabacke et al. their own perce
- Page 402 and 403:
3.2 Modal scores Ari Riabacke et al
- Page 404 and 405:
Ari Riabacke et al. contrast to ope
- Page 406 and 407:
References Ari Riabacke et al. Baja
- Page 408 and 409:
Waldo Rocha Flores et al. To answer
- Page 410 and 411:
Waldo Rocha Flores et al. to an inv
- Page 412 and 413:
Waldo Rocha Flores et al. (UB) and
- Page 414 and 415:
5.1.3 Deliver and support Waldo Roc
- Page 416 and 417:
Waldo Rocha Flores et al. The mean
- Page 418 and 419:
Klaokanlaya Silachan and Panjai Tan
- Page 420 and 421:
Klaokanlaya Silachan and Panjai Tan
- Page 422 and 423:
Klaokanlaya Silachan and Panjai Tan
- Page 424 and 425:
Klaokanlaya Silachan and Panjai Tan
- Page 426 and 427:
Optimizing Information Technology V
- Page 428 and 429:
Ali Suzangar et al. The risk manage
- Page 430 and 431:
Ali Suzangar et al. Table 1, these
- Page 432 and 433:
4.3 Value management Ali Suzangar e
- Page 434 and 435:
Developing an Outpatient Electronic
- Page 436 and 437:
Hsiao-Ting Tseng et al. development
- Page 438 and 439:
Hsiao-Ting Tseng et al. The OEMRS i
- Page 440 and 441:
Table 4: Usage of OEMRS by intervie
- Page 442 and 443:
MTN Foundation's Digital Library Pr
- Page 444 and 445:
The scope of the project is as foll
- Page 446 and 447:
Ngozi Blessing Ukachi The librarian
- Page 448 and 449:
Ngozi Blessing Ukachi Daniel, J. O.
- Page 450 and 451:
management plans, cost estimating a
- Page 452 and 453:
3.4 Hybrid cloud based solution to
- Page 454 and 455:
Harris Wang Brandic, I. (2009) Towa
- Page 456 and 457:
Yupeng Wang et al. To accommodate e
- Page 458 and 459:
Yupeng Wang et al. Figure 5 shows t
- Page 460 and 461:
Yupeng Wang et al. Furthermore, as
- Page 462 and 463:
Yupeng Wang et al. Figure 12: Popul
- Page 464 and 465:
The Impact of Software Test Constra
- Page 466 and 467:
Grafton Whyte and Donovan Lindsay M
- Page 468 and 469:
Grafton Whyte and Donovan Lindsay M
- Page 470 and 471:
Grafton Whyte and Donovan Lindsay M
- Page 472 and 473:
Grafton Whyte and Donovan Lindsay M
- Page 474 and 475:
Grafton Whyte and Donovan Lindsay M
- Page 476 and 477:
learning in an academic setting. Wh
- Page 478 and 479:
Table 3: Examples of barriers to ad
- Page 480 and 481:
Many academics do not attend learni
- Page 482 and 483:
3.4.4 Work plan issues It was consi
- Page 484 and 485:
470
- Page 486 and 487:
472
- Page 488 and 489:
Mona Althonayan and Anastasia Papaz
- Page 490 and 491:
Mona Althonayan and Anastasia Papaz
- Page 492 and 493:
Mona Althonayan and Anastasia Papaz
- Page 494 and 495:
Mona Althonayan and Anastasia Papaz
- Page 496 and 497:
Mona Althonayan and Anastasia Papaz
- Page 498 and 499:
Idisemi Apulu and Ann Latham 3. Sma
- Page 500 and 501:
Idisemi Apulu and Ann Latham “ICT
- Page 502 and 503:
Idisemi Apulu and Ann Latham confid
- Page 504 and 505:
Idisemi Apulu and Ann Latham stand
- Page 506 and 507:
Establishing the Suitability of Dyn
- Page 508 and 509:
Johnson Dehinbo 2.3 Studies emphasi
- Page 510 and 511:
Johnson Dehinbo Moreover, experienc
- Page 512 and 513:
Maintaining Session and Application
- Page 514 and 515:
Johnson Dehinbo When numeric values
- Page 516 and 517:
Human Resources Transformation Beyo
- Page 518 and 519:
Swathi Duppada and Rama Chandra Ary
- Page 520 and 521:
Swathi Duppada and Rama Chandra Ary
- Page 522 and 523:
Swathi Duppada and Rama Chandra Ary
- Page 524 and 525:
Swathi Duppada and Rama Chandra Ary
- Page 526 and 527:
Wakari Gikenye the following resear
- Page 528 and 529:
3.2 Size of MSEs in the study Wakar
- Page 530 and 531:
Wakari Gikenye respondents) reporte
- Page 532 and 533:
Wakari Gikenye 2. Age: (1) Below 25
- Page 534 and 535:
Wakari Gikenye 41. How often do you
- Page 536 and 537:
Sarmad Istephan and Mohammad Siadat
- Page 538 and 539:
Sarmad Istephan and Mohammad Siadat
- Page 540 and 541:
Sarmad Istephan and Mohammad Siadat
- Page 542 and 543:
Sarmad Istephan and Mohammad Siadat
- Page 544 and 545:
Siti Asma Mohammed and Maryati Mohd
- Page 546 and 547:
Siti Asma Mohammed and Maryati Mohd
- Page 548 and 549:
Table 4: Parameters for evaluation
- Page 550 and 551:
Siti Asma Mohammed and Maryati Mohd
- Page 552 and 553:
Siti Asma Mohammed and Maryati Mohd
- Page 554 and 555:
Maryam Nakhoda and Sirous Alidousti
- Page 556 and 557:
Maryam Nakhoda and Sirous Alidousti
- Page 558 and 559:
6. Discussion Maryam Nakhoda and Si
- Page 560 and 561:
Adding Action to the Information Au
- Page 562 and 563:
2.3 Information audit methodologies
- Page 564 and 565:
Huan Vo-Tran Focuses on a strategi
- Page 566 and 567:
Huan Vo-Tran AR typically makes use
- Page 568 and 569:
4. Preliminary findings Huan Vo-Tra
- Page 570 and 571:
Business Intelligence Best Practice
- Page 572 and 573:
3.1 Collaborative culture Joseph Wo
- Page 574 and 575:
Table 1: Summary of supporting work
- Page 576 and 577:
Joseph Woodside Ranjan, J. "Busines
- Page 578 and 579:
564
- Page 580 and 581:
3. Research findings Ganeshprasad C
- Page 582 and 583:
The Relationship Between Quality Ma
- Page 584 and 585:
2.1 QM and knowledge creation Amir
- Page 586 and 587:
Construction and Validation of eSch
- Page 588 and 589:
Hesbon Nyagowa et al. DeLone and Mc
- Page 590 and 591:
3.2 Validity Hesbon Nyagowa et al.