Paper - Hogeschool Gent
Paper - Hogeschool Gent
Paper - Hogeschool Gent

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
Hoofdstuk 5. Resultaten 51<br />
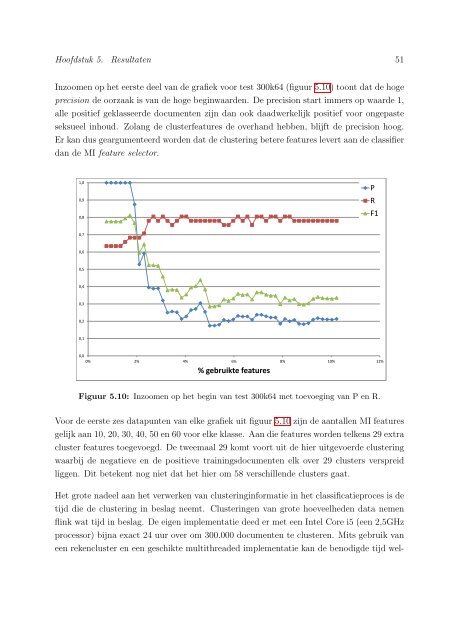
Inzoomen op het eerste deel van de grafiek voor test 300k64 (figuur 5.10) toont dat de hoge<br />
precision de oorzaak is van de hoge beginwaarden. De precision start immers op waarde 1,<br />
alle positief geklasseerde documenten zijn dan ook daadwerkelijk positief voor ongepaste<br />
seksueel inhoud. Zolang de clusterfeatures de overhand hebben, blijft de precision hoog.<br />
Er kan dus geargumenteerd worden dat de clustering betere features levert aan de classifier<br />
dan de MI feature selector.<br />
1,0<br />
0,9<br />
0,8<br />
0,7<br />
0,6<br />
0,5<br />
0,4<br />
0,3<br />
0,2<br />
0,1<br />
0,0<br />
0% 2% 4% 6% 8% 10% 12%<br />
% gebruikte features<br />
Figuur 5.10: Inzoomen op het begin van test 300k64 met toevoeging van P en R.<br />
Voor de eerste zes datapunten van elke grafiek uit figuur 5.10 zijn de aantallen MI features<br />
gelijk aan 10, 20, 30, 40, 50 en 60 voor elke klasse. Aan die features worden telkens 29 extra<br />
cluster features toegevoegd. De tweemaal 29 komt voort uit de hier uitgevoerde clustering<br />
waarbij de negatieve en de positieve trainingsdocumenten elk over 29 clusters verspreid<br />
liggen. Dit betekent nog niet dat het hier om 58 verschillende clusters gaat.<br />
Het grote nadeel aan het verwerken van clusteringinformatie in het classificatieproces is de<br />
tijd die de clustering in beslag neemt. Clusteringen van grote hoeveelheden data nemen<br />
flink wat tijd in beslag. De eigen implementatie deed er met een Intel Core i5 (een 2,5GHz<br />
processor) bijna exact 24 uur over om 300.000 documenten te clusteren. Mits gebruik van<br />
een rekencluster en een geschikte multithreaded implementatie kan de benodigde tijd wel-<br />
P<br />
R<br />
F1