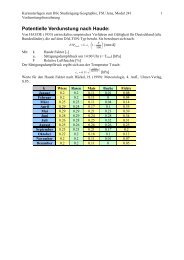
Hausarbeit - Friedrich-Schiller-Universität Jena
Hausarbeit - Friedrich-Schiller-Universität Jena
Hausarbeit - Friedrich-Schiller-Universität Jena

Sie wollen auch ein ePaper? Erhöhen Sie die Reichweite Ihrer Titel.
YUMPU macht aus Druck-PDFs automatisch weboptimierte ePaper, die Google liebt.
<strong>Friedrich</strong> – <strong>Schiller</strong> - <strong>Universität</strong><br />
Institut für Geographie<br />
Wintersemester 2004/2005<br />
<strong>Hausarbeit</strong> zum Hauptseminar:<br />
Analyse und Modellierung räumlicher Daten<br />
Leiter: Dr. Martin Herold<br />
Thema:<br />
Räumliche Autokorrelation und deskriptive Methoden<br />
Verfasser:<br />
Christian Pfeifer<br />
Wanderslebenstr. 7, 07745 <strong>Jena</strong><br />
E-mail: christian_pfeifer@gmx.net<br />
Abgegeben am 22.10.2004
Inhalt<br />
1 Einleitung 2<br />
2 Allgemeine deskriptive Methoden 2<br />
2.1 Mittelwerte 2<br />
2.1.1 Arithmetische Mittel 2<br />
2.1.2 Median und Modus 3<br />
2.2 Streuungsmaße 3<br />
2.2.1 Standartabweichung und Varianz 3<br />
2.2.2 Schiefe und Exzess 4<br />
2.3 „Nearest Neighbor“-Analyse 4<br />
2.4 Histogramm 5<br />
2.5 Datenniveaus 6<br />
2.6 Objektarten 7<br />
3 Räumliche Autokorrelation 7<br />
3.1 Hinführung 7<br />
3.2 Das erste Gesetz der Geographie 8<br />
3.3 Berechnung der räumliche Autokorrelation 10<br />
3.3.1 Geary’s (c) Index 11<br />
3.3.2 Moran’s (I) Index 12<br />
3.4 Probleme 12<br />
3.4.1 Datenherkunft 12<br />
3.4.2 MAUP 13<br />
3.5 Spatial Sampling 13<br />
4 Schlussbemerkung 15<br />
Literatur 15<br />
1
1 Einleitung<br />
Um herauszufinden wie bestimmte Eigenschaften im Raum verteilt sind bedarf es spezieller<br />
statistischer Methoden, besonders dann, wenn die zu untersuchenden Eigenschaften in<br />
Beziehung zum Raum oder zu anderen Merkmalen stehen. Um diese Beziehungen für den<br />
Betrachter sichtbar zu machen werden diese durch deskriptive Methoden analysiert und in<br />
Form einer einzigen oder weniger Zahlen ausgedrückt. In dieser Arbeit soll dabei ein<br />
Hauptaugenmerk auf die Datenanalyse in Bezug auf die räumliche Autokorrelation gelegt<br />
werden. Diese, soviel soll schon gesagt werden, beschäftigt sich mit der räumlichen<br />
Beziehung zwischen Objekten und ihren Nachbarn. Oder wie MORAN schon 1948 schrieb<br />
„The presence, absence, or characteristics of some spatial objects may sometimes have<br />
significant impacts on the presence, absence, or characteristics of the neighboring objects.”<br />
( LO & YEUNG 2002: 117)<br />
Aber bevor auf diese spezielle deskriptive Methode der räumlichen Autokorrelation<br />
eingegangen wird, sollen zuvor ausgewählte, grundlegende Verfahren und Sachverhalte der<br />
traditionellen deskriptiven Statistik erläutert werden.<br />
2 Allgemeine deskriptive Methoden<br />
Die deskriptive bzw. beschreibende Statistik befasst sich mit der Analyse und Darstellung von<br />
räumlichen und zeitlichen Daten. Die Methoden der deskriptiven Statistik haben das Ziel, die<br />
oft großen Datenmengen mit nur wenigen Zahlen zu charakterisieren, so dass sie für den<br />
Betrachter gut interpretierbar sind. Dabei zählt die Visualisierung der Daten, wie z.B. in einer<br />
Karte, zu den besten Methoden bestimmte Muster in den Daten zu erfassen. Zu den<br />
deskriptiven Methoden gehört der Mittelwert und die Streuung, welche nun kurz vorgestellt<br />
werden (LO & YEUNG 2002: 350 & HELMSCHROT & FINK 2001).<br />
2.1 Mittelwerte<br />
Durch die Mittelwerte (engl. central tendency) wird das Zentrum der Verteilung<br />
charakterisiert. Mittelwerte können u.a. durch das arithmetische Mittel, den Median oder den<br />
Modus angeben werden (HELMSCHROT & FINK 2001).<br />
2.1.1 Arithmetische Mittel<br />
Das arithmetische Mittel berechnet man aus der Summe aller<br />
Einzelwerte, dividiert durch die Gesamtzahl aller Stichprobenfälle<br />
(siehe Formel 1). Man sollte diese Formel anwenden, wenn die<br />
Formel 1: Mittelwert x m<br />
Werte hauptsächlich um das arithmetische Mittel verteilt sind. Ist (HELMSCHROT & FINK 2001)<br />
die Stichprobe zu heterogen (weicht zu sehr von der Glockenform<br />
ab) bringt dieses Verfahren zu große Nachteile mit sich (HELMSCHROT & FINK 2001).<br />
2
2.1.2 Median und Modus<br />
Der Median ist der Wert, der die nach der Größe geordnete Verteilung in 2 gleichgroße<br />
Bereiche teilt. Beispiel: Gegeben ist ein beliebige Zahlenreihe mit den Werten 1, 3, 5, 7, 66.<br />
Der mittlere Wert also der Median ist hier 5.<br />
Bei einer ungeraden Anzahl von Stichproben wird der Median von den beiden in der Mitte<br />
stehenden Zahlen gebildet. Der Median hat den Vorteil, dass er sich im Gegensatz zum<br />
arithmetischen Mittel nicht durch einzelne hohe Werte beeinflussen lässt.<br />
Der Modus hingegen zeigt den am häufigsten vorkommenden Merkmalswert einer Datenreihe<br />
oder einer Klasse auf (LO & YEUNG 2002: 351 & HELMSCHROT & FINK 2001).<br />
2.2 Streuungsmaße<br />
Die Streuung (engl.: dispersion) gibt an, wie weit die Merkmalswerte um das Zentrum verteilt<br />
sind. Um die Streuung anzugeben gibt es vier gebräuchliche Möglichkeiten.<br />
2.2.1 Standartabweichung und Varianz<br />
Nach LO & YEUNG (2002: 351) ist die Standartabweichung die wichtigste Maßeinheit um die<br />
Streuung zu charakterisieren. Um die Standartabweichung berechnen zu können, muss vorher<br />
die Varianz gebildet werden. Denn die Standartabweichung ergibt sich, aus der Wurzel der<br />
Varianz (siehe Fromel 3). Die Varianz selbst wird nach der Formel 2 berechnet. Hier muss die<br />
Summe der quadrierten Abweichungen vom Mittelwert x m , durch die Gesamtzahl der<br />
Elemente n dividiert werden.<br />
Formel 3: Varianz s² (HELMSCHROT & FINK 2001)<br />
Formel 2: Standartabweichung s<br />
(HELMSCHROT & FINK 2001)<br />
Die Standartabweichung gibt an, wie sich die Streuung einer Verteilung um den Mittelwert<br />
verhält. Allerdings hat sie den Nachteil, dass man die Standartabweichungen zweier<br />
verschiedener Stichproben nur vergleichen kann, wenn deren arithmetische Mittel in etwa<br />
gleichgroß sind (LO & YEUNG 2002: 351 & HELMSCHROT & FINK 2001).<br />
3
2.2.2 Schiefe und Exzess<br />
Die Schiefe (engl.: skewness) wie der Exzess (engl.: kurtosis) sind Formenparameter, d.h. sie<br />
geben Auskunft über die Form der Verteilung.<br />
„Die Schiefe […] stellt ein Maß für die Symmetrie der Verteilung um das arithmetische<br />
Mittel dar und errechnet sich…“ (HELMSCHROT & FINK 2001) aus der Differenz des<br />
Mittelwert x m vom Median Me, welche durch die Standartabweichung s dividiert wird, wie in<br />
Formel 4 abgebildet. Wenn die Form der Verteilung symmetrisch ist, dann hat die Schiefe g<br />
einen Wert von 0, ist g größer als 0 handelt es sich um eine positive Schiefe, der Median ist<br />
links vom Mittel. Bei einer negativen Schiefe hingegen ist g kleiner als 0 und der Median<br />
rechts vom Mittel.<br />
Formel 4: Schiefe g (HELMSCHROT & FINK 2001) Formel 5: Exzess Ez (HELMSCHROT & FINK 2001)<br />
Der Exzess hingegen ist ein Maß für die Steilheit der Verteilung. So beschreibt er, ob die<br />
Merkmalsverteilung spitz oder flach um das Zentrum verteilt ist. Berechnet wird er, wie in<br />
Formel 5 aufgezeigt. Von einer spitzen Verteilung spricht man, wenn der Exzess Ez größer<br />
als eins ist und damit steiler zuläuft als eine Normalverteilung. Keinen Exzess (Ez = 1) findet<br />
man bei einer Normalverteilung vor. Ist der Exzess kleiner als eins (negativer Exzess) ist die<br />
Verteilung flacher als eine Normalverteilung (LO & YEUNG 2002: 351).<br />
2.3 „Nearest Neighbor“-Analyse<br />
Bei der „Nearest Neighbor“-Analyse werden Verteilungsmuster von Punkten auf einer Fläche<br />
untersucht. Dabei kann bestimmt werden, ob die Messpunkte regelmäßig, unregelmäßig oder<br />
in Clustern (Gruppen) auftreten. „Diese Einordnung [in regelmäßig, unregelmäßig oder in<br />
Clustern] erfolgt über das Messen der Distanzen zwischen gepaarten Datenpunkten. Gepaart<br />
werden dabei die Punkte mit der geringsten räumlichen Distanz zueinander - die ‚Nearest<br />
Neighbor’.“ (DUMFARTH & LORUP 2000)<br />
Um Verwechslungen mit der räumliche Autokorrelation aus dem Weg zu gehen, muss klar<br />
festgestellt werden, dass bei der „Nearest Neighbor“-Analyse nur die räumliche Verteilung<br />
der Punkte bestimmt wird, nicht aber im Zusammenhang mit den Ausmaß der Werte, den<br />
diese Punkte haben<br />
4
Abbildung 1: Mögliche Verteilungsmuster (a) regelmäßig, (b) unregelmäßig, (c) gruppiert<br />
(DUMFARTH & LORUP 2000)<br />
Bei der „Nearest Neighbor“-Analyse gibt es einige Dinge zu beachten, um mögliche<br />
Ungenauigkeiten und Fehlmessungen so gering wie möglich zu halten. Weil es notwendig ist,<br />
die Punktdichte in dem Gebiet zu kennen, muss die Größe der Fläche, in dem die Analyse<br />
durchgeführt werden soll, genau festgelegt werden. Ist nämlich die zu untersuchende Fläche<br />
zu groß im Verhältnis zur Anzahl der Punkte, erhält man eine viel geringere Punktdichte als<br />
wenn man für die gleiche Anzahl von Punkten eine kleineres Gebiet für die Untersuchung<br />
verwendet.<br />
Auch das Problem des Kanteneffektes (engl.: edge effect) sollte nicht vernachlässigt werden.<br />
Das Problem liegt hier darin, dass es unter Umständen auch Punkte außerhalb der Grenzen<br />
der Untersuchungsmatrix gibt, zu denen aber von den Punkten am Rande der Matrix keine<br />
Distanz gemessen werden kann, obwohl diese am nächsten liegen. Um dies zu verhindern,<br />
sollte auch eine Messung zu Punkten außerhalb der Untersuchungsmatrix zugelassen werden<br />
(LO & YEUNG 2002: 357).<br />
2.4 Histogramm<br />
Neben der Karte ist das Histogramm<br />
(siehe Diagramm 1) eine der verbreitesten<br />
Möglichkeiten Daten visuell darzustellen.<br />
Ein Histogramm zeigt an, wie viele<br />
Merkmalsausprägungen in einer<br />
bestimmten vorher festgelegten Klasse<br />
sind. Dabei gibt die y-Achse Auskunft<br />
über die Häufigkeit der Variable (z.B.:<br />
Anzahl von Temperaturwerten) und die x-<br />
Achse zeigt die Klassen, in denen die<br />
Werte eingeordnet werden (z.B.: in der<br />
Klasse 0-5°C liegen 3 Werte). Es liegt also<br />
eine Klassenhäufigkeitsverteilung vor,<br />
durch die man erkennen kann, wie sich die<br />
Diagramm 1: Histogramm [rot] mit<br />
Normalverteilung [schwarz] (DUMFARTH & LORUP 2000)<br />
5
Werte über das gestammte Wertespektrum verteilen. Die wichtigste Form einer<br />
Häufigkeitsverteilung ist die glockenförmige Normalverteilung. Diese ist so bedeutend, da<br />
viele statistische Methoden auf Daten angewiesen sind, die aus einer normalverteilten<br />
Grundgesamtheit kommen. Bei einer Normalverteilung liegt das arithmetisches Mittel und<br />
Median nahe beieinander (oder sind gleich) und repräsentieren die Mitte der Datenmenge<br />
(HELMSCHROT & FINK 2001).<br />
2.5 Datenniveaus<br />
Da bestimmte deskriptive Methoden nur bei Daten bestimmter Skalenart angewendet werden<br />
können, sollen hier die verschieden Skalen kurz vorgestellt werden. Das Problem liegt hier in<br />
dem Umstand, dass Daten verschiedenste Merkmalsausprägungen repräsentieren, die in<br />
unterschiedlichsten Maßeinheiten gemessen werden. So kann ein Datensatz aus<br />
Temperaturdaten bestehen, die in °C gespeichert werden oder aber die Entfernungen<br />
repräsentieren, die in Metern gemessen werden. Dabei muss beachtet werden, dass man zwar<br />
sagen kann, 2m sind doppelt so viel wie 4m, aber 10 °C sind nicht doppelt so warm wie 5°C,<br />
weil die Maßeinheit Grad Celsius einen zufälligen Nullpunkt hat, im Gegensatz zu Kelvin<br />
oder dem metrischen System (HELMSCHROT & FINK 2001).<br />
• Nominalskalierte Daten sind mit Werten unterschiedlicher Merkmale besetzt und eine<br />
Rangfolge der Merkmale kann nicht gebildet werden. Beispiele hierfür sind Namen,<br />
Religionszugehörigkeit aber auch bei Ja-Nein-Fragen wie „Hat der Haushalt einen<br />
PKW?“.<br />
• Die Ordinalskala gilt für Werte, deren Merkmale in eine Rangfolge gebracht werden<br />
kann und die Abstände zwischen benachbarten Werten sind nicht immer identisch.<br />
Beispiele sind Erdzeitalter, Zensuren oder das Einkaufsverhalten (oft, regelmäßig,<br />
selten).<br />
• Bei intervallskalierten Daten sind die Abstände zwischen benachbarten Werten<br />
identisch, aber es gibt keinen definierten Nullpunkt. Darunter fällt die schon oben<br />
erwähnte Maßeinheit Grad Celsius, aber auch der Intelligenzquotient.<br />
• Ratioskalen unterscheiden sich von der intervallskalierten nur in dem Punkt, dass hier<br />
ein definierter Nullpunkt festgelegt ist. Dazu gehört die Angabe von Entfernung in<br />
Metern, das Gewicht in Kilogramm oder das Einkommen in Euro.<br />
(HELMSCHROT & FINK 2001)<br />
6
2.6 Objektarten<br />
Ähnlich wie bei den Skalenarten ist die Anwendung von statistischen Methoden nur an<br />
bestimmte Objektarten gekoppelt (siehe Geary’s (c) Index ). Geographische Objekte werden<br />
nach ihrer Topologieausdehnung, also der Art wie sie den Raum ausfüllen gemessen.<br />
• Punkte haben keine dimensionale Ausbreitung, also auch keine Länge, Breite oder<br />
Höhe. Punkte können verwendet werden um die räumliche Verteilung von<br />
Ereignissen und deren Muster wiederzugeben.<br />
• Linien haben genau eine Dimension, die Länge. Sie werden verwendet, um Distanzen<br />
zu messen oder lineare Objekte darzustellen, beispielsweise Strassen.<br />
• Flächenobjekte haben eine zwei dimensionale Ausdehnung, die Länge und Breite,<br />
aber keine Höhe. Sie werden verwendet, um natürliche Objekte wie Felder oder<br />
künstliche Objekte wie Bevölkerungsverteilungen darzustellen.<br />
• Oberflächen und Volumen sind dreidimensional. Sie finden Verwendung bei der<br />
Darstellung von natürlichen Objekten wie digitalen Geländemodellen oder bei<br />
Phänomenen wie das Besucherpotential eines Einkaufszentrums.<br />
• Zeit wird oft als eine weitere Dimension angesehen, kann aber nach LONGLEY et al.<br />
(2002: 101) im GIS nur schwer simuliert werden.<br />
Wichtig ist noch zu wissen, wie sich die einzelnen Dimensionen zueinander verhalten. So<br />
kann man ein höher dimensionales Objekt auf eine niederes Herunterrechnen, aber nicht<br />
umgekehrt. Wie man ein Objekt letztendlich im GIS darstellt, hängt auch von dem Maßstab<br />
ab. „For example, on a less-detailed map of the world, New York is represented as zerodimensional<br />
point. On a more-detailed map such as a road atlas it will be represented as twodimensional<br />
point.” (LONGLEY et al. 2001: 101) In Wirklichkeit ist die Stadt aber dreidimensional<br />
und kann als solche auch von bestimmten Softwaresystemen wiedergegeben<br />
werden (LONGLEY et al. 2001: 101).<br />
3 Räumliche Autokorrelation<br />
3.1 Hinführung<br />
Das Problem der traditionellen statistischen Analysen ist, dass es bei der Untersuchung von<br />
Zusammenhängen, die eine stochastische Abhängigkeit aufweisen, zu fehlerhaften Resultaten<br />
kommt. So sind Fehlschätzungen der Korrelation zwischen stochastisch abhängigen Variablen<br />
möglich, wodurch Test- und Schätzverfahren verzerrte Ergebnisse liefern und<br />
Fehlinterpretationen die Folge sind. Allerdings kommen stochastische abhängige Variablen in<br />
der Statistik, sehr oft vor und ihre genaue Analyse ist meist von großem Interesse.<br />
(BAHRENBERG et al. 2003²: 360-362) Stochastische Abhängigkeit heißt, dass bestimmte<br />
statistische Ereignisse nicht unabhängig voneinander auftreten.<br />
7
Die Ursache für das Unvermögen der traditionellen Statistik mit Daten umzugehen, die<br />
stochastische Abhängig sind, liegt darin, dass sie auf Zufallsvariablen basiert. Darunter<br />
versteht man, dass die verschiednen Datenwerte der Zufallsvariable rein zufällig zustande<br />
kommen und somit unabhängig voneinander sind (ABLER et al. 1992: 154). Am Beispiel eines<br />
Würfelexperiments soll dies verdeutlicht werden. Würfelt man eine 6 hat dies keinerlei<br />
Einfluss auf den nächsten Würfeldurchgang. Die Wahrscheinlichkeit wieder eine 6 zu würfeln<br />
ist bei jeden Durchgang gleich groß. Vorherige Ereignisse haben keinen Einfluss auf<br />
nachfolgende Ereignisse.<br />
„In Hinblick auf die räumliche Verteilung von Datenpunkten bedeutet dies, daß die<br />
verschiedenen Werte einer Variablen unabhängig von ihrer räumlichen Position zustande<br />
kommen. Erscheinungen wie Distanz der Werte zueinander, Nachbarschaft, Nähe, Richtung<br />
und dergleichen haben also keinen Einfluß auf den Wert eines bzw. aller Datenwerte.“<br />
(DUMFARTH & LORUP 2000) Dass dies aber nicht den Gegebenheiten der Realität entspricht,<br />
ist leicht erkennbar und wird am Beispiel des Bodenmarktes deutlich. Denn dann würde die<br />
räumliche Verteilung der Grundstückspreise keinerlei Muster aufzeigen, da ja alles<br />
zufallsverteilt ist. Im Stadtzentrum beispielsweise würden sich willkürlich sehr teure<br />
Grundstücke mit sehr billigen oder mittelteuren abwechseln.<br />
Bei der Geostatistik geht man daher den Ansatz an, dass die Werte, die eine Variable<br />
annehmen kann, durch eine Funktion gesteuert wird, weshalb man von regionalisierten<br />
Variablen spricht. Das heißt, dass die Werte eines Gebietes bzw. einer Region einander<br />
ähnlich sind, weil sie sich ja untereinander beeinflussen können und dass mit zunehmender<br />
Entfernung die Ähnlichkeit abnimmt. Dies beschrieb W. TOBLER mit dem ersten Gesetz der<br />
Geographie, welches im nächsten Abschnitt erläutert werden wird.<br />
Weiterhin geht man davon aus, dass die Verbreitung eines Phänomens nur ausreichend mit zu<br />
Hilfenahme von räumlichen Eigenschaften (z.B.: Distanz oder Nachbarschaft) erklärt werden<br />
kann (DUMFARTH & LORUP 2000).<br />
3.2 Das erste Gesetz der Geographie und mehr (und seine Folgen)<br />
W. TOBER formulierte 1970 das erste gesetzt der Geographie und beschrieb somit das schon<br />
seit langem bekannte Phänomen, das sich benachbarte Objekte oft ähnlicher waren als weit<br />
entfernte. „The first law of geography is that everything is related to everything else, but near<br />
things are more related than distant things.”(TOBLER 1970 in ABLER 1992: 155) Dieses Gesetz<br />
der Geographie ist, so LONGLEY et al. (2001: 99), die allgemeinste Formulierung über die<br />
Verteilung räumlicher Erscheinungen.<br />
Mit seinem Gesetzt beschreibt TOBLER die räumliche Autokorrelation, also den Grad, mit<br />
dem nahe und entfernte Dinge miteinander verbunden sind (LONGLEY et al. 2001: 99).<br />
Die räumliche Autokorrelation ist eine Bezeichnung für die Abhängigkeit zwischen<br />
benachbarten Orten, wie es überall auf der Erdoberfläche vorkommt. „In practice, the<br />
8
existence of spatial autocorrelation means that if A and B are close together, what happens at<br />
A is related to what happens at B, and vice-versa.”(ABLER et al 1992: 287) Obwohl es logisch<br />
erscheint, dass Dinge die sich räumlich nahe sind, auch ähnliche Merkmale aufweisen, kann<br />
der Umkehrschluss, dass sich die Merkmale von Objekten, die weit entfernt von einander<br />
sind, stark unterscheiden, nicht so einfach gezogen werden. Für ABLER et al. (1992: 287) ist<br />
vielmehr die Frage entscheidend, wie weit zwei Orte von einander entfernt sein müssen,<br />
damit sich diese nicht gegenseitig beeinflussen, sie also unabhängig voneinander sind. Es soll<br />
nur kurz erwähnt werden, dass der gleiche Umstand auf die Zeit bezogen zeitliche<br />
Autokorrelation genannt wird (LONGLEY et al. 2001: 99).<br />
Bei der Bestimmung der räumliche Autokorrelation sind die Lage der Objekte zueinander und<br />
ihre Merkmalsausprägung die wichtigsten Faktoren. Dabei werden gleichzeitig die<br />
Gemeinsamkeiten im Ort und in der Eigenschaft miteinander verglichen (siehe Abschnitt 3.3<br />
Berechnung der räumlichen Autokorrelation). Wenn Objekte nahe beieinander liegen bzw.<br />
benachbart sind und sie das gleichen Merkmal beinhalten, dann spricht man von einem<br />
Muster mit positiver räumlichen Autokorrelation.<br />
„Conversely, negative Spatial autocorrelation is said to exist when features which are close<br />
together in space tend to be more dissimilar in attributes than features which are further apart<br />
(in opposition to Tobler’s Law).“ (LONGLEY et al. 2001: 100,101) Eine räumliche<br />
Autokorrelation ist nicht vorhanden, wenn die Merkmale unabhängig vom Ort sind (LONGLEY<br />
et al. 2001: 101).<br />
Abbildung 2: Typen der räumlichen Autokorrelation (LO & YEUNG 2002: 117)<br />
An Abbildung 2 sind die drei wichtigsten Typen von räumliche Autokorrelationen aufgezeigt.<br />
Die Klassifizierung richtet sich nach der relativen Verteilung räumlicher Objekte und ihrer<br />
Nachbarn. Feld A zeigt die extremste Form positiver Autokorrelation zwischen benachbarten<br />
Zellen. Hier liegen jeweils die schwarzen und weißen Zellen in einer homogenen Fläche<br />
zusammen bzw. räumliche Objekte, die die gleichen Eigenschaften haben, liegen räumlich<br />
nah beieinander. Das genaue Gegenteil, also eine extrem negative räumliche Autokorrelation,<br />
zeigt das Feld C. Hier grenzen an jedes schwarze Feld jeweils nur weiße Felder und<br />
9
Abbildung 3: Bevölkerungsverteilung in Kalifornien und Iowa (ABLER et al. 1992: 84)<br />
umgekehrt. Eine zufällige räumliche Autokorrelation sieht man im Feld B. Dort gibt es keine<br />
größeren Cluster von Objekten mit den gleichen Werten.( LONGLEY et al. 2001: 101 & LO &<br />
YEUNG 2002: 117)<br />
In Abbildung 3 sieht man ein praktisches Beispiel für die unterschiedliche Typen räumliche<br />
Autokorrelation. Hier wird auch deutlich, dass weniger die durchschnittliche<br />
Bevölkerungsdichte von Interesse ist (was auch in der traditionellen Statistik berechnet<br />
werden kann), sondern dass es für eine Interpretation viel interessanter (aber auch<br />
schwieriger) zu wissen ist, wo Ballungen und wo ländliche Gebiete sind. Beide Regionen sind<br />
von der Fläche her in etwa gleich groß, haben aber eine vollkommen unterschiedliche<br />
Bevölkerungsverteilung. In San Bernardino herrscht aufgrund des nur in wenigen Teilen<br />
erreichbaren Grundwassers eine starke räumliche Autokorrelation der Bevölkerung. Im<br />
Gegensatz dazu steht das Gebiet in Iowa, das nur eine schlechte räumliche Autokorrelation<br />
aufweist, was u.a. auf die gleichmäßig vorkommenden Ressourcen zurückzuführen ist (ABLER<br />
et al. 1992: 83).<br />
3.3 Berechnung der räumliche Autokorrelation<br />
Bei der Berechnung der räumliche Autokorrelation werden zwei Werte miteinander<br />
verglichen. Erstens die Gleichwertigkeit der Attribute und zweitens die Ähnlichkeit des Ortes<br />
der Objekte, welche mit den Attributen besetzt sind. Dabei hängt es von dem verwendeten<br />
Datentyp ab, mit welcher Methode die Attribute miteinander verglichen werden können und<br />
von dem Objekttyp,<br />
10
wie die Nachbarschaft festgestellt werden kann (LONGLEY et al. 2001: 114). Zwei der<br />
wichtigsten Methoden, die räumliche Autokorrelation anzugeben, ist der Geary’s (c) Index<br />
und der Moran’s (I) Index (LO & YEUNG 2002: 351).<br />
3.3.1 Geary’s (c) Index<br />
Der von Geary entwickelte Index ist eine Maß zur Angabe der räumliche Autokorrelation für<br />
Objekte mit intervallskalierten Attributdaten. Deshalb kann man diesen Index gut bei der<br />
Analyse von Datenansammlungen verwenden, die von Erhebungsgebieten<br />
(engl. census tracts) stammen.<br />
Der Geary’s (c) Index misst die Ähnlichkeit der Werte von i und j (siehe Formel 6).<br />
Die Variable z i entspricht dem Wert des Objektes c i . Die Ähnlichkeit des Ortes, wo sich i und<br />
j befinden, wird durch die boolesche Variable w ij angegeben, wobei w ij = 1 ist, wenn sie<br />
benachbart sind und wij = 0, wenn sie es nicht sind (LO & YEUNG 2002: 351,352). Aber das<br />
ist nur eine von vielen Möglichkeiten, w ij zu definieren, denn w ij repräsentiert die<br />
Nachbarschaftsbeziehungen und da diese je nach Aufgabe anders festgelegt werden können,<br />
muss diese auch in der Formel entsprechend definiert werden<br />
(BAHRENBERG et al. 2003²: 381-383). Daraus ergibt sich dann der Index (c) wie in Formel 7<br />
beschrieben, wobei s ² die Varianz des Merkmale z i ist.<br />
Wenn das Ergebnis von c = 1 ist, dann sind die Merkmale der Objekte unabhängig von ihrer<br />
Lage verteilt. Der Index (c) ist kleiner als eins, wenn gleiche Merkmale an gleichen Orten<br />
vorkommen, es also eine positive räumliche Autokorrelation gibt. Und schließlich kann (c)<br />
auch größer als eins sein, wenn sich Merkmale und Lage der Objekte unterscheiden, also eine<br />
negative räumliche Autokorrelation vorliegt (LO & YEUNG 2002: 351,352).<br />
Formel 6: Berechnung des Geary’s<br />
(c) Index (LO & YEUNG 2002: 351)<br />
Formel 7: Berechnung des Geary’s (c) Index<br />
(LO & YEUNG 2002: 351)<br />
11
3.3.2 Moran’s (I) Index<br />
Der Moran’s (I) Index hat starke Ähnlichkeit mit Geary’s Index mit dem Unterschied, dass<br />
hier die Ergebnisse dem Betrachter wahrscheinlich logischer erscheinen. Denn hier stehen<br />
positive Ergebnisse auch für eine positive räumliche Autokorrelation und negative für eine<br />
negative räumliche Autokorrelation. Wenn der Index 0 ist, weist dies auf unabhängige<br />
unkorrelierte Daten hin, mit zufälliger Anordnung.<br />
Die Variablen in der unteren Formel 8 zur Berechnung des Index (I) werden fast genauso<br />
definiert wie bei Geary’s (c) Index. Allerdings wird c ij nach der oberen Formel 8 beschrieben.<br />
z i steht wieder für den Wert des Objektes i und j. Die Variable ist der Mittelwert, s²<br />
entspricht der Varianz von z i . Die räumliche Nähe für i und j wird wieder durch w ij,<br />
angegeben (LO & YEUNG 2002:352).<br />
Moran’s and Gearie’s Index kann man nur bei<br />
flächenhaften Objekten anwenden. Es gibt aber<br />
Punkt, Linien und Rasterobjekte für die auch<br />
über Umwege eine Berechnung der räumliche<br />
Autokorrelation möglich ist.<br />
Bei Punktdaten kann man beispielsweise die<br />
Punkte in Flächen umwandeln und dann so die<br />
oben erwähnten Indizes anwenden. Die<br />
räumliche Autokorrelation zwischen<br />
linienförmigen Objekte kann man berechen,<br />
Formel 8: Berechnung des Moran’s (I) Index wenn die Linien Verbindungen zwischen<br />
(LO & YEUNG 2002: 352)<br />
Punkten repräsentieren, die mit Merkmalen<br />
besetzt sind. So wird dann die<br />
Merkmalsähnlichkeit von den Punktpaaren mit anderen Punktpaaren verglichen und die<br />
räumliche Nähe wird dadurch gemessen ob es eine direkte Verbindung zwischen den<br />
Punktpaaren gibt. Bei Rasterdaten wird einfach verglichen, ob einzelne Rasterzellen gleiche<br />
Außengrenzen haben (LO & YEUNG 2002: 352).<br />
3.4 Probleme<br />
3.4.1 Datenherkunft<br />
Ein allgemeines Problem, das viele Analysen betrifft, ist, dass man nicht weiß, ob die<br />
Ergebnisse stimmen, weil man nicht sicher sein kann, dass die Daten, die diesen zu Grunde<br />
liegen, korrekt sind. Mit den Worten von LONGLEY et al. (2001: 137) ausgedrückt: „<br />
Uncertainties in data lead to uncertainties in the result of analysis.“ Die Ursache liegt u.a. in<br />
der Generalisierung und Bündelung der rohen Ausgangsdaten (welche die Realität<br />
widerspiegeln sollen), z.B.: wenn Krankheitsfälle nur pro Bezirk angegeben werden oder<br />
12
Bevölkerungszahlen nur für ein bestimmtes Gebiet angeboten werden. Obwohl man die<br />
Ursache für dieses Problem nicht beheben kann, ist es doch möglich, es genau zu<br />
quantifizieren, um so zumindest die schlimmsten Effekte zu verringern. Die Probleme<br />
kommen auch daher, weil in einen GIS Daten unterschiedlichster Herkunft, Maßstabes,<br />
Detailgenauigkeit und Klassifizierung miteinander verschmelzt werden<br />
(LONGLEY et al. 2001: 137).<br />
3.4.2 MAUP<br />
Das „modifiable areal unit problem“ (MAUP) tritt auf, wenn willkürlich festgelegte Grenzen<br />
für die Berechnung von räumlichen Ereignissen genutzt werden. Dies tritt z.B. bei<br />
Volkszählungsdaten auf, die in bestimmten Flächen angegeben werden, oder die Angabe des<br />
Wahlergebnisses wird höchstens in der Größe von Stadtvierteln gemacht, nicht aber in der<br />
von Einzelpersonen. Vom statistischen Standpunkt her sind diese Grenzen beliebig festgelegt<br />
worden weil, „They do not necessarily consider with breaks in the data. Thus, changing the<br />
boundaries of units […] can affect the appearance of the data.“ (HEYWOOD et al. 2002²: 125)<br />
Deshalb ist es sehr problematisch, zwei Karten oder Datensätze miteinander zu vergleichen,<br />
die denselben Ausschnitt zeigen, aber deren Flächeneinheiten sich unterscheiden (HEYWOOD<br />
et al. 2002²: 125 & LONGLEY et al. 2001: 138).<br />
3.5 Spatial Sampling<br />
Als letztes soll noch kurz auf das spatial sampling eingegangen werden, da die durch das<br />
sampling reduzierten Daten auch bei der Analyse der räumliche Autokorrelation verwendet<br />
werden. Sampling ist ein Prozess, bei dem aus einem Feld mit vielen Objekten, einige wenige<br />
herausgesucht werden. Dies ist nötig, da die reale Welt unendlich komplex ist, ein GIS aber<br />
nicht unendlich viele Daten verarbeiten kann. Daher braucht es eine Reduzierung der Daten,<br />
wie es durch das sampling geschieht. Die sampling Modelle (engl.: sampling scheme, siehe<br />
Abbildung 4) bestimmen die räumliche Verteilung der einzelnen Stichprobenpunkte im<br />
Untersuchungsgebiet (LONGLEY et al. 2001: 103).<br />
• Das Feld A in Abbildung 4 zeigt eine einfache zufällige Stichprobe, also eine, in der<br />
jeder Punkt die gleiche Wahrscheinlichkeit hatte, gezogen zu werden. Dieses Modell<br />
hat den Vorteil, dass es statistisch völlig korrekt ist, aber es weist in der Praxis einige<br />
Schwierigkeiten auf. So kann es vorkommen, das kleine, aber wichtige Bereiche<br />
unterpräsentiert werden, es sei denn es handelt sich um eine sehr große Anzahl von<br />
Stichproben.<br />
• Bei einer systematischen Stichprobe wird der erste Punkt zufällig ermittelt und an<br />
diesem dann die restlichen entlang eines festen Schemas ausgerichtet, wie in Feld B zu<br />
sehen. Diese Methode ist einfach durchzuführen, kann aber bei Daten die periodischen<br />
Änderungen unterliegen, starke Fehler verursachen.<br />
13
• Eine strategische Zufallstichprobe findet man dann vor, wenn man das<br />
Untersuchungsgebiet in bestimmte Teilgebiete gliedert und dann in jedem Teilgebiet<br />
eine zufällige Stichrobe nimmt (siehe Abbildung 4, Feld C).Dieses Modell scheint am<br />
geeignetsten, weil nur eine geringe Anzahl von Stichproben gezogen werden muss.<br />
Allerdings leidet dieses Modell auch unter denselben Problemen wie die<br />
Zufallsstichprobe.<br />
• Das letzte hier aufgeführte sampling Modell zeigt ein strategisches, systematisches<br />
und unangepasstes Modell. Wie der Name schon sagt, vereinigt es die<br />
Vorgehensweise und auch Vorteile der drei vorher genannten Modelle (LO & YEUNG<br />
2002: 118,119).<br />
Zur Stichprobenanzahl lässt sich sagen, dass je heterogener räumliche Phänomene verteilt<br />
sind, desto mehr Stichproben sollten genommen werden, um die ganze breite des Umfanges<br />
zu erfassen. Und je homogener die Verteilung desto weniger Stichproben müssen genommen<br />
werden. Zu beachten ist, dass aus Gründen der Repräsentativität eine gewisse Mindestanzahl<br />
an Stichproben gesammelt werden müssen (LONGLEY et al. 2001: 118).<br />
Abbildung 4: Vier geographische sampling Modelle (LO & YEUNG 2002: 118 )<br />
14
4 Schlussbemerkung<br />
Wie hoffentlich gezeigt werden konnte ist die Analyse räumlich korrelierter Daten eine<br />
komplexe, aber aufschlussreiche Methodik mit vielfachen Anwendungsmöglichkeiten.<br />
Trotzdem ist mir beim lesen der vielfältigen Literatur aufgefallen, dass immer wieder erwähnt<br />
wird, dass die Methoden zur Analyse räumlichen korrelierter Daten nur schlecht oder gar<br />
nicht in GIS integriert sind, wie auch LO & YEUNG (2002: 350) bemängeln. Lediglich mit<br />
Idris32 so LO & YEUNG (2002: 350) ist es möglich räumlichen Autokorrelation mit den<br />
Modul „AUTOCORR“ zu bestimmen. Hingegen bietet das weit verbreitet ArcInfo keine<br />
direkte Unterstützung bei der Analyse von räumlichen Autokorrelation. Nur durch eine<br />
Kopplung mit anderen Statistikprogrammen (z.B.: SPSS) kann diese Funktion implementiert<br />
werden.<br />
Bleibt zu hoffen, dass in Zukunft diesem Gebiet der Datenanalyse mehr Aufmerksamkeit<br />
geschenkt wird, um deren Bedeutung gerecht zu werden.<br />
Literatur<br />
ABLER R.F., MARCUS G. M. & J. M. OLSEN (1992): Geography’s inner worlds, Pervasive<br />
Themes in Contemporary American Geography. New Jersey.<br />
BAHRENBERG G., GIESE E. & J. NIPPER (2003²): Statistische Methoden in der Geographie,<br />
Bd. 2. Berlin, Stuttgart.<br />
HEYWOOD I., CORNELIUS S. & S. CARVER (2002²): An Introduction to Geographical<br />
Information Systems. Essex.<br />
LO C. P. & A. K.W. YEUNG (2002): Concepts and Techniques of Geographic Information<br />
Systems. New Jersey.<br />
LONGLEY P. A., GOODCHILD M.F., MAGUIRE D. J. & D.W. RHIND (2001): Geographic<br />
Information, Systems and Science. Chichester, New York.<br />
Internetliteratur<br />
HELMSCHROT J. & M. FINK (2001): Skript zum Proseminar Statistik,<br />
www.geogr.uni-jena.de/~c8firma/Statistik/ (letzter Aufruf 2002)<br />
DUMFARTH E. & E. J. LORUP (2000): Geostatistik I - Theorie und Praxis,<br />
www.geo.sbg.ac.at/staff/lorup/lv/geostats2000/ (letzter Aufruf 21.10.04)<br />
15