Auswertung von Messwerten (PDF) - Netzmafia
Auswertung von Messwerten (PDF) - Netzmafia
Auswertung von Messwerten (PDF) - Netzmafia
WENIGER ANZEIGEN

Sie wollen auch ein ePaper? Erhöhen Sie die Reichweite Ihrer Titel.
YUMPU macht aus Druck-PDFs automatisch weboptimierte ePaper, die Google liebt.
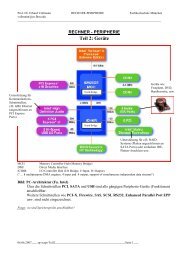
10 1 Datenauswertung<br />
for (i = 0; i = 3<br />
Stichprobe 2: 2.8, 2.9, 3.1, 3.2 -> = 3