- Page 1:
C.I.F. G: 59069740 Universitat Ramo
- Page 5:
Resum En segmentar de forma no supe
- Page 9:
Abstract When facing the task of pa
- Page 12 and 13:
Contents 2.2.6 Consensus functions
- Page 14 and 15:
Contents A.5 Consensus functions .
- Page 16 and 17:
Contents D.2.5 WDBC data set . . .
- Page 18 and 19:
List of Tables 3.13 Relative percen
- Page 20 and 21:
List of Tables 5.15 Relative φ (NM
- Page 23 and 24:
List of Figures 1.1 Evolution of th
- Page 25 and 26:
List of Figures 4.2 Decreasingly or
- Page 27 and 28:
List of Figures C.18 Estimated and
- Page 29 and 30:
List of Figures C.49 φ (NMI) of th
- Page 31 and 32:
List of Figures D.22 φ (NMI) boxpl
- Page 33:
List of Algorithms 6.1 Symbolic des
- Page 36 and 37:
List of symbols OΛ: object co-asso
- Page 38 and 39:
Chapter 1. Framework of the thesis
- Page 40 and 41:
1.1. Knowledge discovery and data m
- Page 42 and 43:
1.1. Knowledge discovery and data m
- Page 44 and 45:
1.2. Clustering in knowledge discov
- Page 46 and 47:
1.2. Clustering in knowledge discov
- Page 48 and 49:
1.2. Clustering in knowledge discov
- Page 50 and 51:
1.2. Clustering in knowledge discov
- Page 52 and 53:
1.2. Clustering in knowledge discov
- Page 54 and 55:
1.3. Multimodal clustering in clust
- Page 56 and 57:
1.4. Clustering indeterminacies exe
- Page 58 and 59:
1.4. Clustering indeterminacies The
- Page 60 and 61:
1.4. Clustering indeterminacies Dat
- Page 62 and 63:
1.5. Motivation and contributions o
- Page 64 and 65:
Chapter 2. Cluster ensembles and co
- Page 66 and 67:
fuzzy consensus clustering solution
- Page 68 and 69:
2.1. Related work on cluster ensemb
- Page 70 and 71:
2.2. Related work on consensus func
- Page 72 and 73:
2.2. Related work on consensus func
- Page 74 and 75:
2.2. Related work on consensus func
- Page 76 and 77:
2.2. Related work on consensus func
- Page 78 and 79:
2.2. Related work on consensus func
- Page 80 and 81:
2.2. Related work on consensus func
- Page 82 and 83:
3.1. Motivation - the computational
- Page 84 and 85:
3.1. Motivation An additional and v
- Page 86 and 87:
3.2. Random hierarchical consensus
- Page 88 and 89:
3.2. Random hierarchical consensus
- Page 90 and 91:
3.2. Random hierarchical consensus
- Page 92 and 93:
3.2. Random hierarchical consensus
- Page 94 and 95:
3.2. Random hierarchical consensus
- Page 96 and 97:
3.2. Random hierarchical consensus
- Page 98 and 99:
3.2. Random hierarchical consensus
- Page 100 and 101:
3.2. Random hierarchical consensus
- Page 102 and 103:
3.2. Random hierarchical consensus
- Page 104 and 105:
3.2. Random hierarchical consensus
- Page 106 and 107:
3.3. Deterministic hierarchical con
- Page 108 and 109:
3.3. Deterministic hierarchical con
- Page 110 and 111:
3.3. Deterministic hierarchical con
- Page 112 and 113:
3.3. Deterministic hierarchical con
- Page 114 and 115:
3.3. Deterministic hierarchical con
- Page 116 and 117:
3.3. Deterministic hierarchical con
- Page 118 and 119:
3.3. Deterministic hierarchical con
- Page 120 and 121:
3.3. Deterministic hierarchical con
- Page 122 and 123:
3.3. Deterministic hierarchical con
- Page 124 and 125:
3.4. Flat vs. hierarchical consensu
- Page 126 and 127:
3.4. Flat vs. hierarchical consensu
- Page 128 and 129:
3.4. Flat vs. hierarchical consensu
- Page 130 and 131:
3.4. Flat vs. hierarchical consensu
- Page 132 and 133:
3.4. Flat vs. hierarchical consensu
- Page 134 and 135:
3.4. Flat vs. hierarchical consensu
- Page 136 and 137:
3.4. Flat vs. hierarchical consensu
- Page 138 and 139:
3.4. Flat vs. hierarchical consensu
- Page 140 and 141:
3.5. Discussion Consensus Consensus
- Page 142 and 143:
3.5. Discussion separate clustering
- Page 145 and 146:
Chapter 4 Self-refining consensus a
- Page 147 and 148:
Chapter 4. Self-refining consensus
- Page 149 and 150:
- What do we want to measure? Chapt
- Page 151 and 152:
φ (NMI) φ (NMI) φ (NMI) φ (NMI)
- Page 153 and 154:
Chapter 4. Self-refining consensus
- Page 155 and 156:
Chapter 4. Self-refining consensus
- Page 157 and 158:
φ (NMI) 0.8 0.78 0.76 0.74 0.72 0
- Page 159 and 160:
1. Given a cluster ensemble E conta
- Page 161 and 162:
Chapter 4. Self-refining consensus
- Page 163 and 164:
%of experiments relative % φ (NMI)
- Page 165 and 166:
Chapter 4. Self-refining consensus
- Page 167:
Publisher: Springer Series: Lecture
- Page 170 and 171:
5.1. Generation of multimodal clust
- Page 172 and 173:
5.2. Self-refining multimodal conse
- Page 174 and 175:
5.3. Multimodal consensus clusterin
- Page 176 and 177:
5.3. Multimodal consensus clusterin
- Page 178 and 179:
5.3. Multimodal consensus clusterin
- Page 180 and 181:
5.3. Multimodal consensus clusterin
- Page 182 and 183:
5.3. Multimodal consensus clusterin
- Page 184 and 185:
5.3. Multimodal consensus clusterin
- Page 186 and 187:
5.3. Multimodal consensus clusterin
- Page 188 and 189:
5.3. Multimodal consensus clusterin
- Page 190 and 191:
5.3. Multimodal consensus clusterin
- Page 192 and 193:
5.3. Multimodal consensus clusterin
- Page 194 and 195:
5.3. Multimodal consensus clusterin
- Page 196 and 197:
5.4. Discussion Data set Relative
- Page 198 and 199:
5.5. Related publications modes joi
- Page 200 and 201:
Chapter 6. Voting based consensus f
- Page 202 and 203:
6.2. Adapting consensus functions t
- Page 204 and 205:
6.2. Adapting consensus functions t
- Page 206 and 207:
6.2. Adapting consensus functions t
- Page 208 and 209:
6.3. Voting based consensus functio
- Page 210 and 211:
6.3. Voting based consensus functio
- Page 212 and 213:
6.3. Voting based consensus functio
- Page 214 and 215:
6.3. Voting based consensus functio
- Page 216 and 217:
6.3. Voting based consensus functio
- Page 218 and 219:
6.3. Voting based consensus functio
- Page 220 and 221:
6.4. Experiments λc = 1 1 1 3 3 3
- Page 222 and 223: 6.4. Experiments Data set Soft clus
- Page 224 and 225: 6.4. Experiments CSPA EAC HGPA MCLA
- Page 226 and 227: 6.5. Discussion solutions on hard c
- Page 229 and 230: Chapter 7 Conclusions The contribut
- Page 231 and 232: Chapter 7. Conclusions of-the-art c
- Page 233 and 234: Chapter 7. Conclusions Though put f
- Page 235 and 236: Chapter 7. Conclusions clustering r
- Page 237 and 238: Chapter 7. Conclusions hardened. Ou
- Page 239 and 240: References Ben-Hur, A., D. Horn, H.
- Page 241 and 242: References Deerwester, S., S.-T. Du
- Page 243 and 244: References Fred, A. and A.K. Jain.
- Page 245 and 246: References Ingaramo, D., D. Pinto,
- Page 247 and 248: References Li, S.Z. and G. GuoDong.
- Page 249 and 250: References Sebastiani, F. 2002. Mac
- Page 251 and 252: References Topchy, A., A.K. Jain, a
- Page 253 and 254: Appendix A Experimental setup A.1 T
- Page 255 and 256: Appendix A. Experimental setup g. s
- Page 257 and 258: A.2.1 Unimodal data sets Appendix A
- Page 259 and 260: A.2.2 Multimodal data sets Appendix
- Page 261 and 262: Appendix A. Experimental setup gene
- Page 263 and 264: Appendix A. Experimental setup orig
- Page 265 and 266: Appendix A. Experimental setup Data
- Page 267: Appendix A. Experimental setup or N
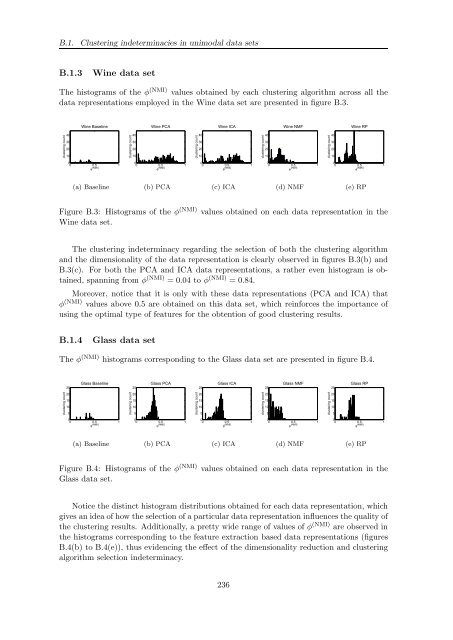
- Page 270 and 271: B.1. Clustering indeterminacies in
- Page 274 and 275: B.1. Clustering indeterminacies in
- Page 276 and 277: B.1. Clustering indeterminacies in
- Page 278 and 279: B.2. Clustering indeterminacies in
- Page 280 and 281: B.2. Clustering indeterminacies in
- Page 282 and 283: B.2. Clustering indeterminacies in
- Page 284 and 285: B.2. Clustering indeterminacies in
- Page 286 and 287: C.1. Configuration of a random hier
- Page 288 and 289: C.2. Estimation of the computationa
- Page 290 and 291: C.2. Estimation of the computationa
- Page 292 and 293: C.2. Estimation of the computationa
- Page 294 and 295: C.2. Estimation of the computationa
- Page 296 and 297: C.2. Estimation of the computationa
- Page 298 and 299: C.2. Estimation of the computationa
- Page 300 and 301: C.2. Estimation of the computationa
- Page 302 and 303: C.2. Estimation of the computationa
- Page 304 and 305: C.2. Estimation of the computationa
- Page 306 and 307: C.2. Estimation of the computationa
- Page 308 and 309: C.3. Estimation of the computationa
- Page 310 and 311: C.3. Estimation of the computationa
- Page 312 and 313: C.3. Estimation of the computationa
- Page 314 and 315: C.3. Estimation of the computationa
- Page 316 and 317: C.3. Estimation of the computationa
- Page 318 and 319: C.3. Estimation of the computationa
- Page 320 and 321: C.3. Estimation of the computationa
- Page 322 and 323:
C.3. Estimation of the computationa
- Page 324 and 325:
C.3. Estimation of the computationa
- Page 326 and 327:
C.4. Computationally optimal RHCA,
- Page 328 and 329:
C.4. Computationally optimal RHCA,
- Page 330 and 331:
C.4. Computationally optimal RHCA,
- Page 332 and 333:
C.4. Computationally optimal RHCA,
- Page 334 and 335:
C.4. Computationally optimal RHCA,
- Page 336 and 337:
C.4. Computationally optimal RHCA,
- Page 338 and 339:
C.4. Computationally optimal RHCA,
- Page 340 and 341:
C.4. Computationally optimal RHCA,
- Page 342 and 343:
C.4. Computationally optimal RHCA,
- Page 344 and 345:
C.4. Computationally optimal RHCA,
- Page 346 and 347:
C.4. Computationally optimal RHCA,
- Page 348 and 349:
C.4. Computationally optimal RHCA,
- Page 350 and 351:
C.4. Computationally optimal RHCA,
- Page 352 and 353:
C.4. Computationally optimal RHCA,
- Page 354 and 355:
C.4. Computationally optimal RHCA,
- Page 356 and 357:
C.4. Computationally optimal RHCA,
- Page 358 and 359:
C.4. Computationally optimal RHCA,
- Page 360 and 361:
C.4. Computationally optimal RHCA,
- Page 362 and 363:
C.4. Computationally optimal RHCA,
- Page 364 and 365:
C.4. Computationally optimal RHCA,
- Page 366 and 367:
C.4. Computationally optimal RHCA,
- Page 368 and 369:
C.4. Computationally optimal RHCA,
- Page 370 and 371:
D.1. Experiments on consensus-based
- Page 372 and 373:
D.1. Experiments on consensus-based
- Page 374 and 375:
D.1. Experiments on consensus-based
- Page 376 and 377:
D.1. Experiments on consensus-based
- Page 378 and 379:
D.1. Experiments on consensus-based
- Page 380 and 381:
D.1. Experiments on consensus-based
- Page 382 and 383:
D.1. Experiments on consensus-based
- Page 384 and 385:
D.2. Experiments on selection-based
- Page 386 and 387:
D.2. Experiments on selection-based
- Page 388 and 389:
D.2. Experiments on selection-based
- Page 390 and 391:
D.2. Experiments on selection-based
- Page 392 and 393:
D.2. Experiments on selection-based
- Page 394 and 395:
D.2. Experiments on selection-based
- Page 396 and 397:
E.1. CAL500 data set φ (NMI) 1 0.8
- Page 398 and 399:
E.1. CAL500 data set φ (NMI) CSPA
- Page 400 and 401:
E.2. InternetAds data set φ (NMI)
- Page 402 and 403:
E.3. Corel data set φ (NMI) 1 0.8
- Page 404 and 405:
E.3. Corel data set φ (NMI) 1 0.8
- Page 406 and 407:
E.3. Corel data set φ (NMI) 1 0.8
- Page 408 and 409:
E.3. Corel data set φ (NMI) 1 0.8
- Page 410 and 411:
F.1. Iris data set φ (NMI) 1 0.8 0
- Page 412 and 413:
F.3. Glass data set CSPA EAC HGPA M
- Page 414 and 415:
F.5. WDBC data set φ (NMI) 1 0.8 0
- Page 416 and 417:
F.7. MFeat data set φ (NMI) 1 0.8
- Page 418 and 419:
F.9. Segmentation data set φ (NMI)
- Page 420 and 421:
F.10. BBC data set φ (NMI) 1 0.8 0
- Page 422 and 423:
F.11. PenDigits data set φ (NMI) 1