

Shared Gaussian Process Latent Variables Models - Oxford Brookes ...
Shared Gaussian Process Latent Variables Models - Oxford Brookes ...
Shared Gaussian Process Latent Variables Models - Oxford Brookes ...

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
2.7. GAUSSIAN PROCESSES 43<br />
1.5<br />
1<br />
0.5<br />
−3 −2 −1 −0.5 1 2 3<br />
−1<br />
−1.5<br />
−2<br />
−2.5<br />
−3<br />
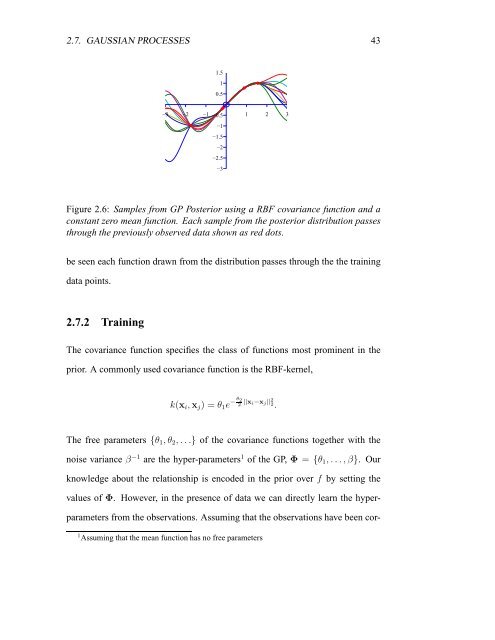
Figure 2.6: Samples from GP Posterior using a RBF covariance function and a<br />
constant zero mean function. Each sample from the posterior distribution passes<br />
through the previously observed data shown as red dots.<br />
be seen each function drawn from the distribution passes through the the training<br />
data points.<br />
2.7.2 Training<br />
The covariance function specifies the class of functions most prominent in the<br />
prior. A commonly used covariance function is the RBF-kernel,<br />
k(xi,xj) = θ1e − θ 2 2 ||xi−xj|| 2 2.<br />
The free parameters {θ1, θ2, . . .} of the covariance functions together with the<br />
noise variance β −1 are the hyper-parameters 1 of the GP, Φ = {θ1, . . .,β}. Our<br />
knowledge about the relationship is encoded in the prior over f by setting the<br />
values of Φ. However, in the presence of data we can directly learn the hyper-<br />
parameters from the observations. Assuming that the observations have been cor-<br />
1 Assuming that the mean function has no free parameters













