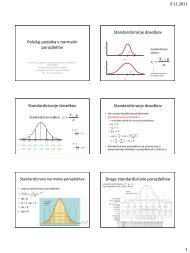
METODA POVPREÄNE NAPAKE
METODA POVPREÄNE NAPAKE
METODA POVPREÄNE NAPAKE

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
Predpostavke ANOVE<br />
M T = 7<br />
M 1 = 4<br />
M 2 = 10<br />
n = 9<br />
a = 2<br />
2 3 4 5 6 7 8 9 10 11 12<br />
df znotraj = N - a = 18 - 2 = 16<br />
df med = a - 1 = 2 - 1 = 1<br />
MS znotraj = 1.5<br />
MS med = 162<br />
F = 162 / 1.5 = 108<br />
F .05 (1, 16) = 4.49<br />
E(<br />
MS<br />
2 2<br />
E(<br />
MS ) n<br />
162<br />
2<br />
<br />
A<br />
18<br />
ˆ2<br />
17,83<br />
A<br />
S<br />
A<br />
/<br />
2<br />
) 1,5<br />
A<br />
e<br />
e<br />
ˆ2<br />
a 1<br />
ˆ2<br />
2 1<br />
<br />
A <br />
A 17,83<br />
8,92<br />
a 2<br />
2<br />
2 <br />
A<br />
9<br />
ω A 0,87<br />
2 2<br />
3,21<br />
Y<br />
A<br />
a 1<br />
MS<br />
A<br />
MSS<br />
/ A 1 162<br />
1,5<br />
<br />
<br />
2<br />
2 9<br />
ωˆ a n<br />
A <br />
<br />
<br />
0,86<br />
a 1<br />
MS<br />
A<br />
MSS<br />
/ A 1 162<br />
1,5<br />
<br />
MSS<br />
/ A 1,5<br />
a n 2 9 <br />
2 a<br />
1 FA<br />
1<br />
1107<br />
ωˆ<br />
A <br />
<br />
0,86<br />
a<br />
1 F 1<br />
na 1107<br />
92<br />
A<br />
n<br />
98,92<br />
7,32<br />
1,5<br />
2<br />
A<br />
2<br />
e<br />
1-b > 0,99<br />
• Napake (ε ij v strukturnem modelu) so neodvisne,<br />
nekorelirane<br />
• Porazdelitev napak ε ij je normalna (v vsakem<br />
pogoju)<br />
pomembno pri majhnih vzorcih<br />
pogosto kršeno pri diskretnih spremenljivkah<br />
F-test je precej robusten, neobčutljiv na kršitve te<br />
predpostavke, razen v primerih ekstremne As ali Spl<br />
• Homogenost varianc<br />
Predpostavke ANOVE<br />
Homogenost varianc = Porazdelitev napak ima<br />
enako varianco pri vseh ravneh NV<br />
V imenovalcu F razmerja je skupna varianca<br />
napake, ki je tehtana znotrajskupinska<br />
varianca. Če se variance skupin zelo<br />
razlikujejo, je taka skupna mera slaba ocena<br />
variance napake.<br />
Verjetnost napake je navadno večja, kot jo<br />
kaže F test.<br />
Problem predvsem pri neenakih skupinah (že<br />
razmerje 2:1 je lahko kritično; priporočeno je,<br />
naj bo razmerje manjše od 4:1), predvsem če<br />
je večja varianca značilna za manjšo skupino.<br />
Preverjamo jo z Levenovim testom<br />
• Računa ANOVO na absolutnih odklonih od M.<br />
• Statistično pomemben rezultat pove, da<br />
variance niso homogene.<br />
• Ni občutljiv na odstopanja od N. D.<br />
Pregled grafov<br />
• Spread vs. Level Plot<br />
• Box-Plot<br />
<br />
Predpostavke ANOVE<br />
• Verjetnost nenormalne porazdelitve in<br />
heterogenosti varianc raste:<br />
z nižanjem N<br />
z večanjem raznolikosti velikosti različnih<br />
skupin<br />
z večanjem števila faktorjev<br />
• Ne sme biti osamelcev, saj ti povečajo<br />
varianco napake in povečajo verjetnost b<br />
napake.<br />
Rešitve v primeru kršenja<br />
predpostavk<br />
• v popravkih stopenj svobode<br />
Welchov t test<br />
• korekcija df (df se zmanjšajo)<br />
• boljši pri visokem razmerju varianc različnih skupin, pri n j vsaj 10 in<br />
N.D., kadar sta vzorca različno velika in varianci nehomogeni<br />
• običajno večja moč<br />
• napihnjena alfa pri asimetričnih porazdelitvah<br />
Brown-Forsythov F test<br />
• robusten test, večja moč v primeru, ko so vse sredine razen ene<br />
enake in ima vzorec z izstopajočo sredino tudi veliko varianco<br />
• primeren ob neenakih skupinah, heterogenih variancah in<br />
asimetrični porazdelitvi odklonov rezultatov od M j (kadar ni N. D.)<br />
• primerljiva pri vzorcih z n j < 6<br />
• Z WLS (weighted least squares) utežmi – osebe različno obtežimo,<br />
da bi zmanjšali heteroscedastičnost<br />
Rešitve v primeru kršenja<br />
predpostavk<br />
• v transformaciji podatkov<br />
Asimetrične porazdelitve približamo normalnim<br />
Zmanjšamo heterogenost varianc<br />
Transformacije: arc sin (sqrt(Y ij )), log, potence<br />
• Slika log j / log M j ; Y transf = Y 1-nagib ; če je nagib funkcije enak<br />
1 log<br />
• Transformacije v primeru asimetričnosti porazdelitev<br />
podatkov povečajo moč, vendar testirajo ničelno hipotezo na<br />
drugačni lestvici – težave pri interpretaciji rezultatov<br />
4