

Data Mining von Sequenzdaten - Fachgebiet Datenbanken und ...
Data Mining von Sequenzdaten - Fachgebiet Datenbanken und ...
Data Mining von Sequenzdaten - Fachgebiet Datenbanken und ...

Sie wollen auch ein ePaper? Erhöhen Sie die Reichweite Ihrer Titel.
YUMPU macht aus Druck-PDFs automatisch weboptimierte ePaper, die Google liebt.
2 GRUNDLAGEN 12<br />
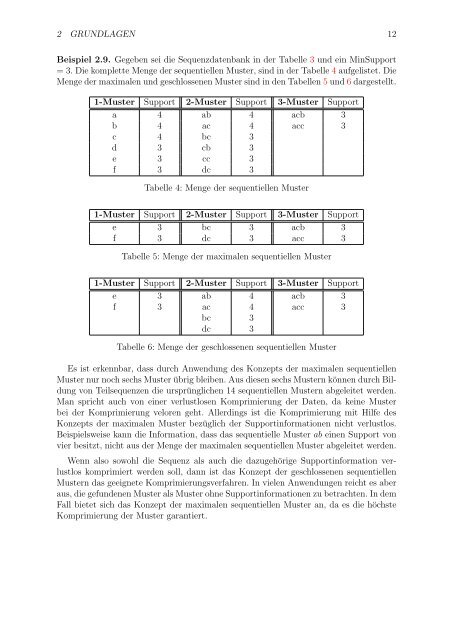
Beispiel 2.9. Gegeben sei die <strong>Sequenzdaten</strong>bank in der Tabelle 3 <strong>und</strong> ein MinSupport<br />
= 3. Die komplette Menge der sequentiellen Muster, sind in der Tabelle 4 aufgelistet. Die<br />
Menge der maximalen <strong>und</strong> geschlossenen Muster sind in den Tabellen 5 <strong>und</strong> 6 dargestellt.<br />
1-Muster Support 2-Muster Support 3-Muster Support<br />
a 4 ab 4 acb 3<br />
b 4 ac 4 acc 3<br />
c 4 bc 3<br />
d 3 cb 3<br />
e 3 cc 3<br />
f 3 dc 3<br />
Tabelle 4: Menge der sequentiellen Muster<br />
1-Muster Support 2-Muster Support 3-Muster Support<br />
e 3 bc 3 acb 3<br />
f 3 dc 3 acc 3<br />
Tabelle 5: Menge der maximalen sequentiellen Muster<br />
1-Muster Support 2-Muster Support 3-Muster Support<br />
e 3 ab 4 acb 3<br />
f 3 ac 4 acc 3<br />
bc 3<br />
dc 3<br />
Tabelle 6: Menge der geschlossenen sequentiellen Muster<br />
Es ist erkennbar, dass durch Anwendung des Konzepts der maximalen sequentiellen<br />
Muster nur noch sechs Muster übrig bleiben. Aus diesen sechs Mustern können durch Bildung<br />
<strong>von</strong> Teilsequenzen die ursprünglichen 14 sequentiellen Mustern abgeleitet werden.<br />
Man spricht auch <strong>von</strong> einer verlustlosen Komprimierung der Daten, da keine Muster<br />
bei der Komprimierung veloren geht. Allerdings ist die Komprimierung mit Hilfe des<br />
Konzepts der maximalen Muster bezüglich der Supportinformationen nicht verlustlos.<br />
Beispielsweise kann die Information, dass das sequentielle Muster ab einen Support <strong>von</strong><br />
vier besitzt, nicht aus der Menge der maximalen sequentiellen Muster abgeleitet werden.<br />
Wenn also sowohl die Sequenz als auch die dazugehörige Supportinformation verlustlos<br />
komprimiert werden soll, dann ist das Konzept der geschlossenen sequentiellen<br />
Mustern das geeignete Komprimierungsverfahren. In vielen Anwendungen reicht es aber<br />
aus, die gef<strong>und</strong>enen Muster als Muster ohne Supportinformationen zu betrachten. In dem<br />
Fall bietet sich das Konzept der maximalen sequentiellen Muster an, da es die höchste<br />
Komprimierung der Muster garantiert.














