Jahresbericht 2009/2010 - RRZN - Leibniz Universität Hannover
Jahresbericht 2009/2010 - RRZN - Leibniz Universität Hannover
Jahresbericht 2009/2010 - RRZN - Leibniz Universität Hannover

Erfolgreiche ePaper selbst erstellen
Machen Sie aus Ihren PDF Publikationen ein blätterbares Flipbook mit unserer einzigartigen Google optimierten e-Paper Software.
13<br />
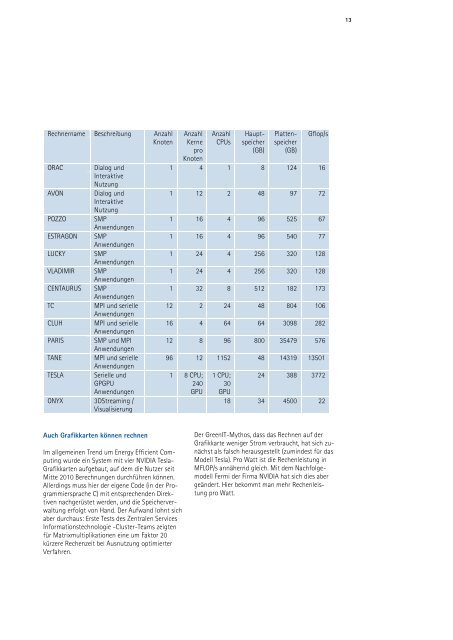
Rechnername Beschreibung Anzahl<br />
Knoten<br />
ORAC Dialog und<br />
Interaktive<br />
Nutzung<br />
AVON Dialog und<br />
Interaktive<br />
Nutzung<br />
POZZO SMP<br />
Anwendungen<br />
ESTRAGON SMP<br />
Anwendungen<br />
LUCKY SMP<br />
Anwendungen<br />
VLADIMIR SMP<br />
Anwendungen<br />
CENTAURUS SMP<br />
Anwendungen<br />
TC<br />
MPI und serielle<br />
Anwendungen<br />
CLUH MPI und serielle<br />
Anwendungen<br />
PARIS SMP und MPI<br />
Anwendungen<br />
TANE MPI und serielle<br />
Anwendungen<br />
TESLA Serielle und<br />
GPGPU<br />
Anwendungen<br />
ONYX 3DStreaming /<br />
Visualisierung<br />
Anzahl<br />
Kerne<br />
pro<br />
Knoten<br />
Anzahl<br />
CPUs<br />
Hauptspeicher<br />
(GB)<br />
Plattenspeicher<br />
(GB)<br />
Gflop/s<br />
1 4 1 8 124 16<br />
1 12 2 48 97 72<br />
1 16 4 96 525 67<br />
1 16 4 96 540 77<br />
1 24 4 256 320 128<br />
1 24 4 256 320 128<br />
1 32 8 512 182 173<br />
12 2 24 48 804 106<br />
16 4 64 64 3098 282<br />
12 8 96 800 35479 576<br />
96 12 1152 48 14319 13501<br />
1 8 CPU;<br />
240<br />
GPU<br />
1 CPU;<br />
30<br />
GPU<br />
24 388 3772<br />
18 34 4500 22<br />
Auch Grafikkarten können rechnen<br />
Im allgemeinen Trend um Energy Efficient Computing<br />
wurde ein System mit vier NVIDIA Tesla-<br />
Grafikkarten aufgebaut, auf dem die Nutzer seit<br />
Mitte <strong>2010</strong> Berechnungen durchführen können.<br />
Allerdings muss hier der eigene Code (in der Programmiersprache<br />
C) mit entsprechenden Direktiven<br />
nachgerüstet werden, und die Speicherverwaltung<br />
erfolgt von Hand. Der Aufwand lohnt sich<br />
aber durchaus: Erste Tests des Zentralen Services<br />
Informationstechnologie -Cluster-Teams zeigten<br />
für Matrixmultiplikationen eine um Faktor 20<br />
kürzere Rechenzeit bei Ausnutzung optimierter<br />
Verfahren.<br />
Der GreenIT-Mythos, dass das Rechnen auf der<br />
Grafikkarte weniger Strom verbraucht, hat sich zunächst<br />
als falsch herausgestellt (zumindest für das<br />
Modell Tesla). Pro Watt ist die Rechenleistung in<br />
MFLOP/s annähernd gleich. Mit dem Nachfolgemodell<br />
Fermi der Firma NVIDIA hat sich dies aber<br />
geändert. Hier bekommt man mehr Rechenleistung<br />
pro Watt.