

Signal Analysis Research (SAR) Group - RNet - Ryerson University
Signal Analysis Research (SAR) Group - RNet - Ryerson University
Signal Analysis Research (SAR) Group - RNet - Ryerson University

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
formant referenced by the black arrow. The watermark is em-<br />
Normalized frequency<br />
0.5<br />
0.25<br />
0<br />
0 1000 2000 3000 4000<br />
Normalized time<br />
Fig. 3. Log–spectrogram of the test signal. Male utterance of<br />
the word “bingo” with a sampling rate of 8 kHz.<br />
bedded as described in Sec. 3.1. First, the data (τ)2 = 010011<br />
is used to generate the amplitude of the watermark by means<br />
of the Equ. 16. Then the insertion zone is manually choseninordertodene<br />
the warping operator used to generate<br />
the time–warped watermark. Finally, the time–warped watermark<br />
is added to the original signal. Result of the watermark<br />
embedding is shown in Fig. 4. As can be seen, the time–<br />
Normalized frequency<br />
0.5<br />
0.25<br />
0<br />
0<br />
1000<br />
Normalized time<br />
(a) Original signal<br />
Normalized frequency<br />
0.5<br />
0.25<br />
0<br />
0<br />
1000<br />
Normalized time<br />
(b) Watermarked signal<br />
Fig. 4. Zoomed log–spectrogram of the original and watermarked<br />
test signal.<br />
warped watermark is very close to the original formant. As<br />
expected, the frequency spread decreases very fast, thanks to<br />
the smoothness of the amplitude of the watermark sequence.<br />
We found the embedding strategy satisfactory since we<br />
were not able to guess wether the signal was watermarked or<br />
not during blind tests. In order to provide a more objective<br />
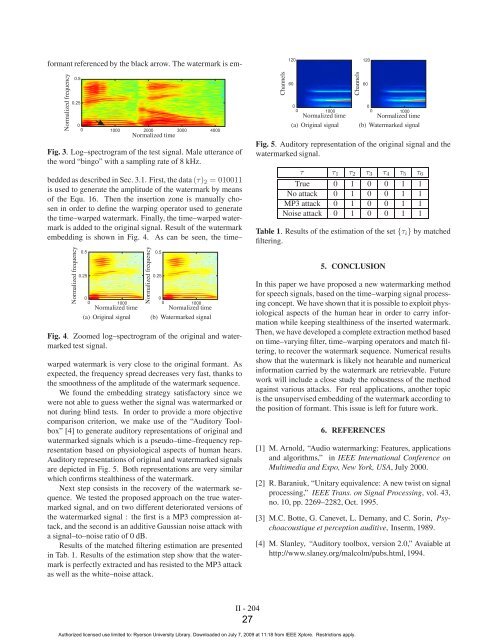
comparison criterion, we make use of the “Auditory Toolbox”<br />
[4] to generate auditory representations of original and<br />
watermarked signals which is a pseudo–time–frequency representation<br />
based on physiological aspects of human hears.<br />
Auditory representations of original and watermarked signals<br />
are depicted in Fig. 5. Both representations are very similar<br />
which conrms stealthiness of the watermark.<br />
Next step consists in the recovery of the watermark sequence.<br />
We tested the proposed approach on the true watermarked<br />
signal, and on two different deteriorated versions of<br />
the watermarked signal : the rst is a MP3 compression attack,<br />
and the second is an additive Gaussian noise attack with<br />
a signal–to–noise ratio of 0 dB.<br />
Results of the matched ltering estimation are presented<br />
in Tab. 1. Results of the estimation step show that the watermark<br />
is perfectly extracted and has resisted to the MP3 attack<br />
as well as the white–noise attack.<br />
II 204<br />
27<br />
Channels<br />
120<br />
60<br />
0<br />
0<br />
1000<br />
Normalized time<br />
(a) Original signal<br />
Channels<br />
120<br />
60<br />
0<br />
0<br />
1000<br />
Normalized time<br />
(b) Watermarked signal<br />
Fig. 5. Auditory representation of the original signal and the<br />
watermarked signal.<br />
τ τ1 τ2 τ3 τ4 τ5 τ6<br />
True 0 1 0 0 1 1<br />
No attack 0 1 0 0 1 1<br />
MP3 attack 0 1 0 0 1 1<br />
Noise attack 0 1 0 0 1 1<br />
Table 1. Results of the estimation of the set {τi} by matched<br />
ltering.<br />
5. CONCLUSION<br />
In this paper we have proposed a new watermarking method<br />
for speech signals, based on the time–warping signal processing<br />
concept. We have shown that it is possible to exploit physiological<br />
aspects of the human hear in order to carry information<br />
while keeping stealthiness of the inserted watermark.<br />
Then, we have developed a complete extraction method based<br />
on time–varying lter, time–warping operators and match ltering,<br />
to recover the watermark sequence. Numerical results<br />
show that the watermark is likely not hearable and numerical<br />
information carried by the watermark are retrievable. Future<br />
work will include a close study the robustness of the method<br />
against various attacks. For real applications, another topic<br />
is the unsupervised embedding of the watermark according to<br />
the position of formant. This issue is left for future work.<br />
6. REFERENCES<br />
[1] M. Arnold, “Audio watermarking: Features, applications<br />
and algorithms,” in IEEE International Conference on<br />
Multimedia and Expo, New York, USA, July 2000.<br />
[2] R. Baraniuk, “Unitary equivalence: A new twist on signal<br />
processing,” IEEE Trans. on <strong>Signal</strong> Processing, vol. 43,<br />
no. 10, pp. 2269–2282, Oct. 1995.<br />
[3] M.C. Botte, G. Canevet, L. Demany, and C. Sorin, Psychoacoustique<br />
et perception auditive, Inserm, 1989.<br />
[4] M. Slanley, “Auditory toolbox, version 2.0,” Avaiable at<br />
http://www.slaney.org/malcolm/pubs.html, 1994.<br />
Authorized licensed use limited to: <strong>Ryerson</strong> <strong>University</strong> Library. Downloaded on July 7, 2009 at 11:18 from IEEE Xplore. Restrictions apply.