- Page 1: FACULTY OF HUMANITIES, SOCIAL S
- Page 5: Acknowledgements After almost eight
- Page 8 and 9: 2.4 SUMMARY 49 3 THE DISTRIBUTION O
- Page 10 and 11: 5.7 5.8 5.8.1 5.8.2 5.8.3 5.8.4 5.8
- Page 12 and 13: viii
- Page 14 and 15: CHAPTER 1 b. Clause initial negatio
- Page 16 and 17: CHAPTER 1 marker in these cases. By
- Page 18 and 19: CHAPTER 1 Map 2: The different vari
- Page 20 and 21: CHAPTER 1 language(s). Within tradi
- Page 22 and 23: CHAPTER 1 (3) CP ty (Neg1P) ty TP t
- Page 24 and 25: CHAPTER 1 short negative markers in
- Page 26 and 27: CHAPTER 1 (6) PF-clitic Syntax: CP
- Page 28 and 29: CHAPTER 1 b. Dermed spiser noen ikk
- Page 30 and 31: CHAPTER 1 The scope of negation has
- Page 32 and 33: CHAPTER 1 The Norwegian form inkje
- Page 34 and 35: CHAPTER 1 1.6 Outline of the disser
- Page 36 and 37: CHAPTER 2 speaking are underlying E
- Page 38 and 39: CHAPTER 2 Henry (2005: 1615) also n
- Page 40 and 41: CHAPTER 2 Map 3 The ScanDiaSyn loca
- Page 42 and 43: CHAPTER 2 included/excluded, but in
- Page 44 and 45: CHAPTER 2 The female informant had
- Page 46 and 47: CHAPTER 2 In this particular case t
- Page 48 and 49: CHAPTER 2 Before each dialect works
- Page 52 and 53: CHAPTER 2 varies whether the record
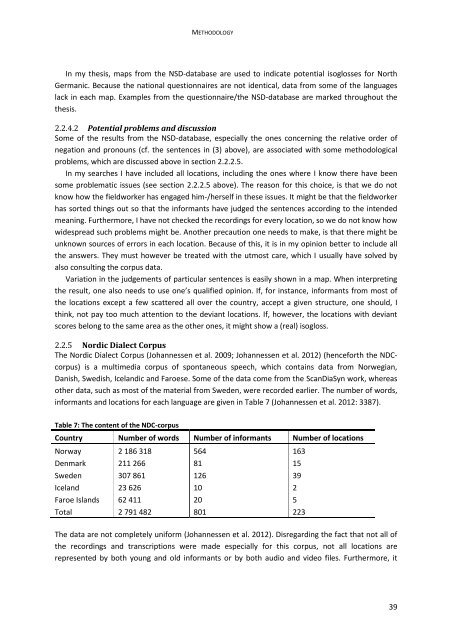
- Page 54 and 55: CHAPTER 2 The Excel features have b
- Page 56 and 57: CHAPTER 2 There are also some poten
- Page 58 and 59: CHAPTER 2 files. The recordings of
- Page 60 and 61: CHAPTER 2 The Internet contains sen
- Page 63 and 64: 3 The distribution of negation in m
- Page 65 and 66: THE DISTRIBUTION OF NEGATION IN MAI
- Page 67 and 68: THE DISTRIBUTION OF NEGATION IN MAI
- Page 69 and 70: THE DISTRIBUTION OF NEGATION IN MAI
- Page 71 and 72: THE DISTRIBUTION OF NEGATION IN MAI
- Page 73 and 74: THE DISTRIBUTION OF NEGATION IN MAI
- Page 75 and 76: THE DISTRIBUTION OF NEGATION IN MAI
- Page 77 and 78: THE DISTRIBUTION OF NEGATION IN MAI
- Page 79 and 80: THE DISTRIBUTION OF NEGATION IN MAI
- Page 81 and 82: THE DISTRIBUTION OF NEGATION IN MAI
- Page 83 and 84: THE DISTRIBUTION OF NEGATION IN MAI
- Page 85 and 86: THE DISTRIBUTION OF NEGATION IN MAI
- Page 87 and 88: THE DISTRIBUTION OF NEGATION IN MAI
- Page 89 and 90: THE DISTRIBUTION OF NEGATION IN MAI
- Page 91 and 92: THE DISTRIBUTION OF NEGATION IN MAI
- Page 93 and 94: THE DISTRIBUTION OF NEGATION IN MAI
- Page 95 and 96: THE DISTRIBUTION OF NEGATION IN MAI
- Page 97 and 98: THE DISTRIBUTION OF NEGATION IN MAI
- Page 99 and 100: THE DISTRIBUTION OF NEGATION IN MAI
- Page 101 and 102:
THE DISTRIBUTION OF NEGATION IN MAI
- Page 103:
THE DISTRIBUTION OF NEGATION IN MAI
- Page 106 and 107:
CHAPTER 4 4.2 Issues of variation E
- Page 108 and 109:
CHAPTER 4 In (5a) the finite verb m
- Page 110 and 111:
CHAPTER 4 First, specificity matter
- Page 112 and 113:
CHAPTER 4 b. og så kunne det jo sk
- Page 114 and 115:
CHAPTER 4 The standard analysis of
- Page 116 and 117:
CHAPTER 4 Table 15: Hooper and Thom
- Page 118 and 119:
CHAPTER 4 b. Men det som er er at
- Page 120 and 121:
CHAPTER 4 impression of contemporar
- Page 122 and 123:
CHAPTER 4 In non-V2 contexts the Fo
- Page 124 and 125:
CHAPTER 4 After the exclusions, the
- Page 126 and 127:
CHAPTER 4 The DP subjects that prec
- Page 128 and 129:
CHAPTER 4 In (34) the word order do
- Page 130 and 131:
CHAPTER 4 this adverb and a compari
- Page 132 and 133:
CHAPTER 4 In (41) an analysis of an
- Page 134 and 135:
CHAPTER 4 move to FinP, in order to
- Page 136 and 137:
CHAPTER 4 as some of the examples a
- Page 138 and 139:
CHAPTER 4 Having considered the com
- Page 140 and 141:
CHAPTER 4 discussed by Jensen 1995
- Page 142 and 143:
CHAPTER 4 states that negation cann
- Page 144 and 145:
CHAPTER 4 b. Markerne de blev opdyr
- Page 146 and 147:
CHAPTER 4 (64) a. Det var fordi (*
- Page 148 and 149:
CHAPTER 4 (66) a. Har vóru nógv f
- Page 150 and 151:
CHAPTER 4 4.7.7 On the modern varie
- Page 152 and 153:
CHAPTER 4 4.8 Summary This chapter
- Page 154 and 155:
CHAPTER 5 The empirical and theoret
- Page 156 and 157:
CHAPTER 5 The pronominal systems in
- Page 158 and 159:
CHAPTER 5 (6) a. I går las (??itj)
- Page 160 and 161:
CHAPTER 5 5.2.2.2 The Fosen dialect
- Page 162 and 163:
CHAPTER 5 In these three sentences
- Page 164 and 165:
CHAPTER 5 Bjugn Rissa Sto. (11) a.
- Page 166 and 167:
CHAPTER 5 would favour the order su
- Page 168 and 169:
CHAPTER 5 Map 16: The locations in
- Page 170 and 171:
CHAPTER 5 is however not corroborat
- Page 172 and 173:
CHAPTER 5 (17) a. Korsen hadde det
- Page 174 and 175:
CHAPTER 5 Stamsund, Myre and Karls
- Page 176 and 177:
CHAPTER 5 In at least old varieties
- Page 178 and 179:
CHAPTER 5 (24) a. eg hadde klabba o
- Page 180 and 181:
CHAPTER 5 Table 36: Form of the neg
- Page 182 and 183:
CHAPTER 5 However, the observed opt
- Page 184 and 185:
CHAPTER 5 Table 40: Form of the neg
- Page 186 and 187:
CHAPTER 5 Map 18: The villages of
- Page 188 and 189:
CHAPTER 5 in all the eight instance
- Page 190 and 191:
CHAPTER 5 In (35a) the pronouns an
- Page 192 and 193:
CHAPTER 5 chapter 4 that in the tra
- Page 194 and 195:
CHAPTER 5 (40) Råka (int) Lasse (
- Page 196 and 197:
CHAPTER 5 b. Dette er en bok som (*
- Page 198 and 199:
CHAPTER 5 With regard to I-language
- Page 200 and 201:
CHAPTER 5 the pre-subject position,
- Page 202 and 203:
CHAPTER 5 Map 20: The relative orde
- Page 204 and 205:
CHAPTER 5 Map 22: The relative orde
- Page 206 and 207:
CHAPTER 5 Table 48: Types of embedd
- Page 208 and 209:
CHAPTER 5 (56) indirect wh-question
- Page 210 and 211:
CHAPTER 5 (61) a. Koss va det laga
- Page 212 and 213:
CHAPTER 5 adverb. Here we may have
- Page 214 and 215:
CHAPTER 5 5.8.4 Premises of an anal
- Page 216 and 217:
CHAPTER 5 b. *Itt du vi kji allstø
- Page 218 and 219:
CHAPTER 5 (74) SubP Verb movement a
- Page 220 and 221:
CHAPTER 5 Whatever the explanation
- Page 222 and 223:
CHAPTER 5 Table 52 shows that propo
- Page 224 and 225:
CHAPTER 5 moved finite verb, which
- Page 226 and 227:
CHAPTER 6 (1) Types of Negative Con
- Page 228 and 229:
CHAPTER 6 example, a consequence of
- Page 230 and 231:
CHAPTER 6 elements in this example
- Page 232 and 233:
CHAPTER 6 or two negations, such th
- Page 234 and 235:
CHAPTER 6 Norwegian. These examples
- Page 236 and 237:
CHAPTER 6 (17) a. ja, ellest ir it
- Page 238 and 239:
CHAPTER 6 (21) a. ig ir inggan redd
- Page 240 and 241:
CHAPTER 6 c. It duge on ti nogontin
- Page 242 and 243:
CHAPTER 6 In none of the discussed
- Page 244 and 245:
CHAPTER 6 taken from Christensen (2
- Page 246 and 247:
CHAPTER 6 The observation that pres
- Page 248 and 249:
CHAPTER 6 Testing of only clause-in
- Page 250 and 251:
CHAPTER 6 dominates the entire clau
- Page 252 and 253:
CHAPTER 6 (43) a. Nede i kjelleren
- Page 254 and 255:
CHAPTER 6 Table 55: Types of clause
- Page 256 and 257:
CHAPTER 6 (50) O ik is nie bang woo
- Page 258 and 259:
CHAPTER 6 In Övdalian, there might
- Page 260 and 261:
CHAPTER 6 However, none of the maps
- Page 262 and 263:
CHAPTER 6 d. D æ ittj så væ’st
- Page 264 and 265:
CHAPTER 6 frequent contact across t
- Page 266 and 267:
CHAPTER 6 It may also be that the c
- Page 268 and 269:
CHAPTER 6 Thus, in these examples t
- Page 271 and 272:
7 Negative imperatives 7.1 Introduc
- Page 273 and 274:
NEGATIVE IMPERATIVES In ON, the neg
- Page 275 and 276:
NEGATIVE IMPERATIVES associated wit
- Page 277 and 278:
NEGATIVE IMPERATIVES 7.3.2 Zanuttin
- Page 279 and 280:
NEGATIVE IMPERATIVES imperative ver
- Page 281 and 282:
NEGATIVE IMPERATIVES The neg-initia
- Page 283 and 284:
NEGATIVE IMPERATIVES (31) a. ?Vennl
- Page 285 and 286:
NEGATIVE IMPERATIVES Recall that Je
- Page 287 and 288:
NEGATIVE IMPERATIVES (41) CP V-init
- Page 289 and 290:
NEGATIVE IMPERATIVES Regarding impe
- Page 291 and 292:
NEGATIVE IMPERATIVES Map 27: Neg-in
- Page 293 and 294:
NEGATIVE IMPERATIVES 7.5.2 Övdalia
- Page 295 and 296:
NEGATIVE IMPERATIVES (50) a. it ti
- Page 297 and 298:
NEGATIVE IMPERATIVES constituent to
- Page 299 and 300:
NEGATIVE IMPERATIVES The å-imperat
- Page 301 and 302:
NEGATIVE IMPERATIVES The initial ve
- Page 303 and 304:
NEGATIVE IMPERATIVES between komma
- Page 305 and 306:
NEGATIVE IMPERATIVES marginally app
- Page 307 and 308:
NEGATIVE IMPERATIVES respect to the
- Page 309 and 310:
NEGATIVE IMPERATIVES intervene betw
- Page 311:
NEGATIVE IMPERATIVES as the negativ
- Page 314 and 315:
CHAPTER 8 across North Germanic: 1.
- Page 316 and 317:
CHAPTER 8 specific structures are r
- Page 318 and 319:
g CHAPTER 9 g (2) ΣP strong negati
- Page 320 and 321:
CHAPTER 9 Clause-initial negation o
- Page 322 and 323:
CHAPTER 9 9.4 The syntax of negatio
- Page 324 and 325:
CHAPTER 9 principle it follows that
- Page 327 and 328:
10 Conclusion There has been an inc
- Page 329 and 330:
LIST OF MAPS List of Maps MAP 1: TH
- Page 331:
LIST OF TABLES TABLE 42: PARTS OF T
- Page 334 and 335:
REFERENCES Andréasson, M. (2007).
- Page 336 and 337:
REFERENCES Cornips, L., & Corrigan,
- Page 338 and 339:
REFERENCES 145-166. Henry, A. (2005
- Page 340 and 341:
REFERENCES questions Papers from th
- Page 342 and 343:
REFERENCES Radford, A. (2004). Mini
- Page 344:
REFERENCES Wiklund, A.-L., Hrafnbja