

cloudera-spark

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
Developing Spark Applications<br />
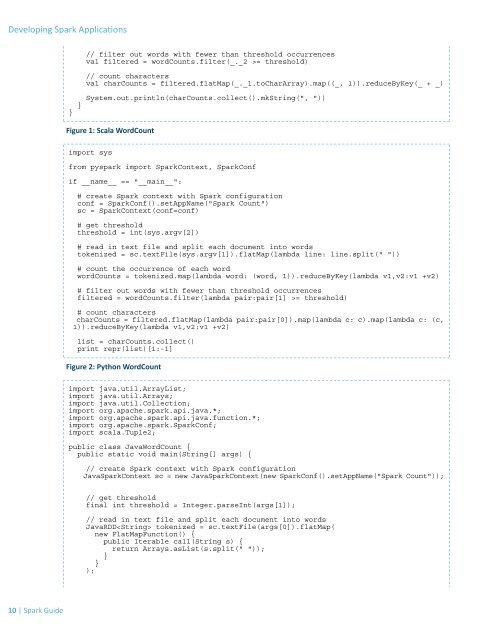
// filter out words with fewer than threshold occurrences<br />
val filtered = wordCounts.filter(_._2 >= threshold)<br />
// count characters<br />
val charCounts = filtered.flatMap(_._1.toCharArray).map((_, 1)).reduceByKey(_ + _)<br />
}<br />
}<br />
System.out.println(charCounts.collect().mkString(", "))<br />
Figure 1: Scala WordCount<br />
import sys<br />
from py<strong>spark</strong> import SparkContext, SparkConf<br />
if __name__ == "__main__":<br />
# create Spark context with Spark configuration<br />
conf = SparkConf().setAppName("Spark Count")<br />
sc = SparkContext(conf=conf)<br />
# get threshold<br />
threshold = int(sys.argv[2])<br />
# read in text file and split each document into words<br />
tokenized = sc.textFile(sys.argv[1]).flatMap(lambda line: line.split(" "))<br />
# count the occurrence of each word<br />
wordCounts = tokenized.map(lambda word: (word, 1)).reduceByKey(lambda v1,v2:v1 +v2)<br />
# filter out words with fewer than threshold occurrences<br />
filtered = wordCounts.filter(lambda pair:pair[1] >= threshold)<br />
# count characters<br />
charCounts = filtered.flatMap(lambda pair:pair[0]).map(lambda c: c).map(lambda c: (c,<br />
1)).reduceByKey(lambda v1,v2:v1 +v2)<br />
list = charCounts.collect()<br />
print repr(list)[1:-1]<br />
Figure 2: Python WordCount<br />
import java.util.ArrayList;<br />
import java.util.Arrays;<br />
import java.util.Collection;<br />
import org.apache.<strong>spark</strong>.api.java.*;<br />
import org.apache.<strong>spark</strong>.api.java.function.*;<br />
import org.apache.<strong>spark</strong>.SparkConf;<br />
import scala.Tuple2;<br />
public class JavaWordCount {<br />
public static void main(String[] args) {<br />
// create Spark context with Spark configuration<br />
JavaSparkContext sc = new JavaSparkContext(new SparkConf().setAppName("Spark Count"));<br />
// get threshold<br />
final int threshold = Integer.parseInt(args[1]);<br />
// read in text file and split each document into words<br />
JavaRDD tokenized = sc.textFile(args[0]).flatMap(<br />
new FlatMapFunction() {<br />
public Iterable call(String s) {<br />
return Arrays.asList(s.split(" "));<br />
}<br />
}<br />
);<br />
10 | Spark Guide

