

cloudera-spark

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
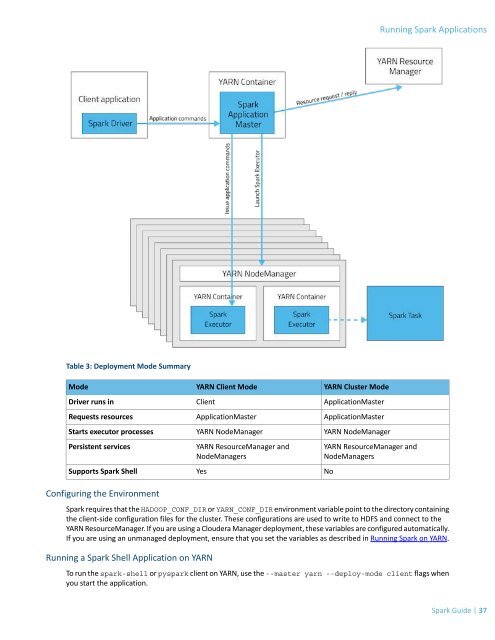
Running Spark Applications<br />
Table 3: Deployment Mode Summary<br />
Mode<br />
Driver runs in<br />
Requests resources<br />
Starts executor processes<br />
Persistent services<br />
Supports Spark Shell<br />
YARN Client Mode<br />
Client<br />
ApplicationMaster<br />
YARN NodeManager<br />
YARN ResourceManager and<br />
NodeManagers<br />
Yes<br />
YARN Cluster Mode<br />
ApplicationMaster<br />
ApplicationMaster<br />
YARN NodeManager<br />
YARN ResourceManager and<br />
NodeManagers<br />
No<br />
Configuring the Environment<br />
Spark requires that the HADOOP_CONF_DIR or YARN_CONF_DIR environment variable point to the directory containing<br />
the client-side configuration files for the cluster. These configurations are used to write to HDFS and connect to the<br />
YARN ResourceManager. If you are using a Cloudera Manager deployment, these variables are configured automatically.<br />
If you are using an unmanaged deployment, ensure that you set the variables as described in Running Spark on YARN.<br />
Running a Spark Shell Application on YARN<br />
To run the <strong>spark</strong>-shell or py<strong>spark</strong> client on YARN, use the --master yarn --deploy-mode client flags when<br />
you start the application.<br />
Spark Guide | 37

