

FIAS Scientific Report 2011 - Frankfurt Institute for Advanced Studies ...
FIAS Scientific Report 2011 - Frankfurt Institute for Advanced Studies ...
FIAS Scientific Report 2011 - Frankfurt Institute for Advanced Studies ...

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
Lattice QCD on GPUs<br />
Collaborators: M. Bach 1 , V. Lindenstruth 1 , O. Philipsen 2 , C. Pinke 2 , C. Schäfer 2 , L. Zeidlewicz 2<br />
1 <strong>Frankfurt</strong> <strong>Institute</strong> <strong>for</strong> <strong>Advanced</strong> <strong>Studies</strong>, 2 Institut für Theoretische Physik, Goethe-Universität <strong>Frankfurt</strong> am Main<br />
Quantum Chromodynamics (QCD) is the known theory of the strong <strong>for</strong>ce and part of the Standard Model of<br />
particle physics. Its phase diagram is a problem of particular interest and is investigated in current, state-of-theart<br />
collider experiments at CERN and, in the near future, at FAIR. Lattice QCD provides a first principle access<br />
to this problem.<br />
Lattice simulations require an enormous amount of computing power. They sample the phase space using<br />
Hybrid Monte Carlo techniques, requiring the fermion matrix to be inverted many times. The inversion of this<br />
sparse quadratic matrix, typically of size 10 8 × 10 8 , is the most time consuming part of the algorithm. To get<br />
physical results simulations need to be carried out at different lattice spacings and extrapolated to the continuum<br />
limit.<br />
Sparse matrix inversion is completely dominated by the memory bandwidth available in the system. Today<br />
Graphics Processing Units (GPUs) provide significantly more bandwidth than CPUs, making them a promising<br />
plat<strong>for</strong>m <strong>for</strong> QCD codes. However, so far GPU-enabled Lattice QCD codes have always been focused on the<br />
proprietary NVIDIA CUDA programming interface, locking the usability of the code to hardware of this one<br />
vendor.<br />
We aim at building a versatile Lattice QCD solution that can achieve optimum per<strong>for</strong>mance on a wide variety of<br />
modern hardware architectures. There<strong>for</strong>e we base our solution on OpenCL, an open programming standard <strong>for</strong><br />
parallel programming supported by all major hardware vendors. We focus on remaining with a single source<br />
source code, ensuring maintainability and easier verification of code correctness, while achieving maximum<br />
per<strong>for</strong>mance over a wide range of system configurations.<br />
Bandwidth GB/s<br />
140<br />
120<br />
100<br />
80<br />
60<br />
40<br />
20<br />
16^3x4<br />
16^3x8<br />
24^3x4<br />
16^3x16<br />
16^3x20<br />
16^3x24<br />
16^3x28<br />
32^3x4<br />
24^3x12<br />
Dslash Per<strong>for</strong>mance<br />
24^3x16<br />
Lattice Size<br />
32^3x8<br />
24^3x20<br />
24^3x24<br />
32^3x12<br />
GPU Bandwidth<br />
140<br />
GPU Gflops<br />
CPU Bandwidth 120<br />
CPU Gflops 100<br />
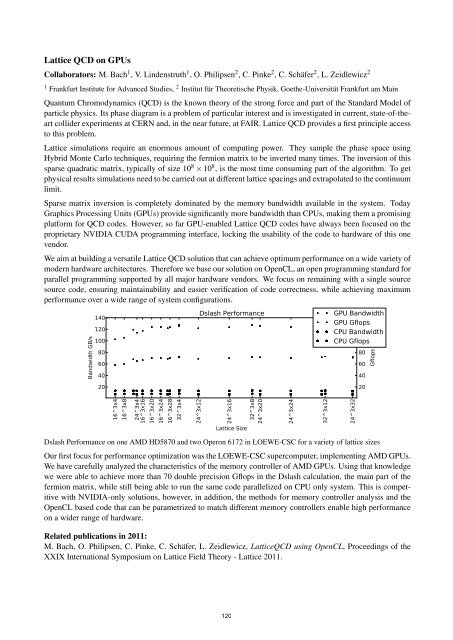
Dslash Per<strong>for</strong>mance on one AMD HD5870 and two Operon 6172 in LOEWE-CSC <strong>for</strong> a variety of lattice sizes<br />
Our first focus <strong>for</strong> per<strong>for</strong>mance optimization was the LOEWE-CSC supercomputer, implementing AMD GPUs.<br />
We have carefully analyzed the characteristics of the memory controller of AMD GPUs. Using that knowledge<br />
we were able to achieve more than 70 double precision Gflops in the Dslash calculation, the main part of the<br />
fermion matrix, while still being able to run the same code parallelized on CPU only system. This is competitive<br />
with NVIDIA-only solutions, however, in addition, the methods <strong>for</strong> memory controller analysis and the<br />
OpenCL based code that can be parametrized to match different memory controllers enable high per<strong>for</strong>mance<br />
on a wider range of hardware.<br />
Related publications in <strong>2011</strong>:<br />
M. Bach, O. Philipsen, C. Pinke, C. Schäfer, L. Zeidlewicz, LatticeQCD using OpenCL, Proceedings of the<br />
XXIX International Symposium on Lattice Field Theory - Lattice <strong>2011</strong>.<br />
120<br />
24^3x32<br />
80<br />
60<br />
40<br />
20<br />
Gflops













