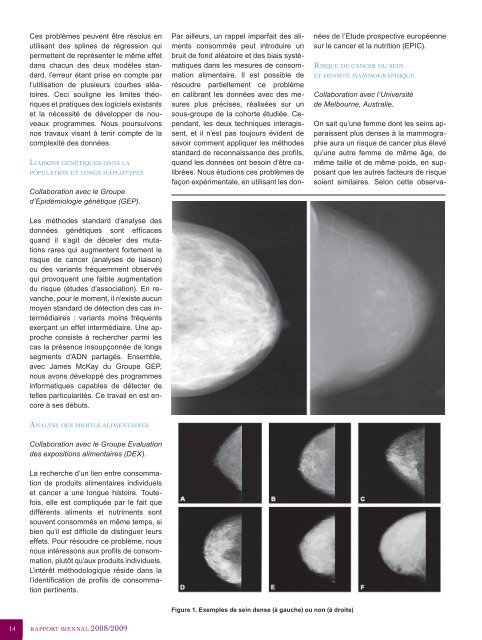
Ces problèmes peuvent être résolus en utilisant des splines de régression qui permettent de représenter le même effet dans chacun des deux modèles standard, l’erreur étant prise en compte par l’utilisation de plusieurs courbes aléatoires. Ceci souligne les limites théoriques et pratiques des logiciels existants et la nécessité de développer de nouveaux programmes. Nous poursuivons nos travaux visant à tenir compte de la complexité des données. Liaisons génétiques dans la population et longs haplotypes Collaboration avec le Groupe d’Epidémiologie génétique (GEP). Les méthodes standard d’analyse des données génétiques sont efficaces quand il s’agit de déceler des mutations rares qui augmentent fortement le risque de cancer (analyses de liaison) ou des variants fréquemment observés qui provoquent une faible augmentation du risque (études d’association). En revanche, pour le moment, il n’existe aucun moyen standard de détection des cas intermédiaires : variants moins fréquents exerçant un effet intermédiaire. Une approche consiste à rechercher parmi les cas la présence insoupçonnée de longs segments d’ADN partagés. Ensemble, avec James McKay du Groupe GEP, nous avons développé des programmes informatiques capables de détecter de telles particularités. Ce travail en est encore à ses débuts. Par ailleurs, un rappel imparfait des aliments consommés peut introduire un bruit de fond aléatoire et des biais systématiques dans les mesures de consommation alimentaire. Il est possible de résoudre partiellement ce problème en calibrant les données avec des mesures plus précises, réalisées sur un sous-groupe de la cohorte étudiée. Cependant, les deux techniques interagissent, et il n’est pas toujours évident de savoir comment appliquer les méthodes standard de reconnaissance des profils, quand les données ont besoin d’être calibrées. Nous étudions ces problèmes de façon expérimentale, en utilisant les données de l’Etude prospective européenne sur le cancer et la nutrition (EPIC). Risque de cancer du sein et densité mammographique Collaboration avec l’Université de Melbourne, Australie. Analyse des profils alimentaires Collaboration avec le Groupe Evaluation des expositions alimentaires (DEX). La recherche d’un lien entre consommation de produits alimentaires individuels et cancer a une longue histoire. Toutefois, elle est compliquée par le fait que différents aliments et nutriments sont souvent consommés en même temps, si bien qu’il est difficile de distinguer leurs effets. Pour résoudre ce problème, nous nous intéressons aux profils de consommation, plutôt qu’aux produits individuels. L’intérêt méthodologique réside dans la l’identification de profils de consommation pertinents. Figure 1. Exemples de sein dense (à gauche) ou non (à droite) 14 On sait qu’une femme dont les seins apparaissent plus denses à la mammographie aura un risque de cancer plus élevé qu’une autre femme de même âge, de même taille et de même poids, en supposant que les autres facteurs de risque soient similaires. Selon cette observarapport biennal 2008/2009
tion, il serait donc possible que d’importants mécanismes intervenant dans le développement du cancer du sein puissent dépendre de gènes associés à la densité mammographique. L’étude australienne sur les jumelles (cohorte de jumelles et de leurs sœurs) constitue une ressource particulièrement utile pour de telles recherches. La comparaison des données génétiques et de la densité mammographique dans ces familles a soulevé un certain nombre de difficultés d’ordre méthodologique qui sont désormais résolues, ce qui a donné lieu à plusieurs articles, dont certains sont publiés et d’autres soumis à publication. Cours de formation Université d’été du CIRC en Epidémiologie du Cancer 2008 (CIRC, du 2 au 27 juin 2008 et du 15 juin au 3 juillet 2009). Réunions Atelier de travail « Unclassified Variants/ Clinical Interpretation » (CIRC, 4–5 fév. 2008) ; Groupe de travail « Unclassified Variants in Mismatch Repair Genes » (CIRC, 19–20 fév. 2009). Le Groupe BST remercie les personnes suivantes pour leur collaboration : Australie : Lyle Gurrin, Carolyn Nickson, John Hopper, Jennifer Stone ; Allemagne : Heiner Boeing, Brian Buijsse ; Etats-Unis : David Goldgar Publications Abraham G, Byrnes GB, Bain C (2009). Short-Term Forecasting of Emergency Inpatient Flow. IEEE Trans Inf Technol Biomed. May; 13: 380 - 8. Au L, Byrnes GB, Bain CA, Fackrell M, Brand C, Campbell DA, Taylor PG (2009). Predicting overflow in an emergency department. IMA J Management Math, January; 20: 39 - 49. Burgess JA, Dharmage SC, Byrnes GB, Matheson MC, Gurrin LC, Wharton CL, Johns DP, Abramson MJ, Hopper JL, Walters EH (2008). Childhood eczema and asthma incidence and persistence: a cohort study from childhood to middle age. J Allergy Clin Immunol. Aug;122(2):280-5. Epub 2008 Jun 24. Davis SM, Donnan GA, Parsons MW, Levi C, Butcher KS, Peeters A, Barber PA, Bladin C, De Silva DA, Byrnes GB, Chalk JB, Fink JN, Kimber TE, Schultz D, Hand PJ, Frayne J, Hankey G, Muir K, Gerraty R, Tress BM, Desmond PM; for the EPI- THET investigators (2008). Effects of alteplase beyond 3 h after stroke in the Echoplanar Imaging Thrombolytic Evaluation Trial (EPITHET): a placebo-controlled randomised trial. Lancet Neurol. Feb 22; [Epub ahead of print] Dite GS, Gurrin LC, Byrnes GB, Stone J, Gunasekara A, McCredie MR, English DR, Giles GG, Cawson J, Hegele RA, Chiarelli AM, Yaffe MJ, Boyd NF, Hopper JL (2008). Predictors of mammographic density: insights gained from a novel regression analysis of a twin study. Cancer Epidemiol Biomarkers Prev. Dec;17(12):3474-81. Goldgar DE, Easton DF, Byrnes GB, Spurdle AB, Iversen ES, Greenblatt MS (2008); <strong>IARC</strong> Unclassified Genetic Variants Working Group. Genetic evidence and integration of various data sources for classifying uncertain variants into a single model. Hum Mutat. Nov;29(11):1265-72. Jenab M, McKay J, Bueno-de-Mesquita HB, van Duijnhoven FJ, Ferrari P, Slimani N, Jansen EH, Pischon T, Rinaldi S, Tjønneland A, Olsen A, Overvad K, Boutron-Ruault MC, Clavel-Chapelon F, Engel P, Kaaks R, Linseisen J, Boeing H, Fisher E, Trichopoulou A, Dilis V, Oustoglou E, Berrino F, Vineis P, Mattiello A, Masala G, Tumino R, Vrieling A, van Gils CH, Peeters PH, Brustad M, Lund E, Chirlaque MD, Barricarte A, Suárez LR, Molina E, Dorronsoro M, Sala N, Hallmans G, Palmqvist R, Roddam A, Key TJ, Khaw KT, Bingham S, Boffetta P, Autier P, Byrnes GB, Norat T, Riboli E (2009). Vitamin D Receptor and Calcium Sensing Receptor Polymorphisms and the Risk of Colorectal Cancer in European Populations. Cancer Epidemiol Biomarkers Prev. Aug 25. [Epub ahead of print] Kavanagh AM, Byrnes GB, Nickson C, Cawson JN, Giles GG, Hopper JL, Gertig DM, English DR (2008). Using mammographic density to improve breast cancer screening outcomes. Cancer Epidemiol Biomarkers Prev. Oct;17(10):2818-24. McKay JD, Hung RJ, Gaborieau V, Boffetta P, Chabrier A, Byrnes GB, Zaridze D, Mukeria A, Szeszenia-Dabrowska N, Lissowska J, Rudnai P, Fabianova E, Mates D, Bencko V, Foretova L, Janout V, McLaughlin J, Shepherd F, Montpetit A, Narod S, Krokan HE, Skorpen F, Elvestad MB, Vatten L, Njølstad I, Axelsson T, Chen C, Goodman G, Barnett M, Loomis MM, Lubiñski J, Matyjasik J, Lener M, Oszutowska D, Field J, Liloglou T, Xinarianos G, Cassidy A; EPIC Study, Vineis P, Clavel-Chapelon F, Palli D, Tumino R, Krogh V, Panico S, González CA, Ramón Quirós J, Martínez C, Navarro C, Ardanaz E, Larrañaga N, Kham KT, Key T, Buenode-Mesquita HB, Peeters PH, Trichopoulou A, Linseisen J, Boeing H, Hallmans G, Overvad K, Tjønneland A, Kumle M, Riboli E, Zelenika D, Boland A, Delepine M, Foglio M, Lechner D, Matsuda F, Blanche H, Gut I, Heath S, Lathrop M, Brennan P (2008). Lung cancer susceptibility locus at 5p15.33. Nat Genet. Dec;40(12):1404-6. Epub 2008 Nov 2. Pala V, Krogh V, Berrino F, Sieri S, Grioni S, Tjønneland A, Olsen A, Jakobsen MU, Overvad K, Clavel-Chapelon F, Boutron-Ruault MC, Romieu I, Linseisen J, Rohrmann S, Boeing H, Steffen A, Trichopoulou A, Benetou V, Naska A, Vineis P, Tumino R, Panico S, Masala G, Agnoli C, Engeset D, Skeie G, Lund E, Ardanaz E, Navarro C, Sánchez MJ, Amiano P, Svatetz CA, Rodriguez L, Wirfält E, Manjer J, Lenner P, Hallmans G, Peeters PH, van Gils CH, Bueno-de-Mesquita HB, van Duijnhoven FJ, Key TJ, Spencer E, Bingham S, Khaw KT, Ferrari P, Byrnes GB, Rinaldi S, Norat T, Michaud DS, Riboli E (2009). Meat, eggs, dairy products, and risk of breast cancer in the European Prospective Investigation into Cancer and Nutrition (EPIC) cohort. Am J Clin Nutr. Sep;90(3):602-12. groupe biostatistique 15
- Page 1: Centre international de Recherche s
- Page 6 and 7: ISBN 978-92-832-0426-8 ISSN 1017-34
- Page 9: Table des matières Introduction 1
- Page 12 and 13: Par conséquent, le Centre doit ori
- Page 14 and 15: HANCE). Le Centre contribue aussi
- Page 16 and 17: des Sections : Données du Cancer ;
- Page 18 and 19: Références Didier Colin C’est a
- Page 21 and 22: Section Données du Cancer (cin) Ch
- Page 23: Groupe Biostatistique (bst) Chef Dr
- Page 27 and 28: Groupe Analyse et Interprétation d
- Page 29 and 30: Figure 3 Réseau européen des Regi
- Page 31 and 32: Course on Introduction to Cancer Re
- Page 33 and 34: women attending cervical cancer scr
- Page 35 and 36: Groupe Production Epidémiologie de
- Page 37 and 38: Figure 1. Page extraite de l’Atla
- Page 39 and 40: era les différents moyens d’asso
- Page 41 and 42: 2) Pays d’Amérique latine à fai
- Page 43: va C, Holcátová I, Agudo A, Caste
- Page 46 and 47: Le Volume 100 indique un degré plu
- Page 48 and 49: El Ghissassi F, Baan R, Straif K, G
- Page 51 and 52: Groupe Epigénétique (ege) Chef Dr
- Page 53 and 54: composant invariable Skp1 du comple
- Page 55 and 56: Groupe Cancérogenèse moléculaire
- Page 57 and 58: mécanisme rédox-dépendant (Bykov
- Page 59 and 60: Références et Publications Achatz
- Page 61: Section Pathologie moléculaire (mp
- Page 64 and 65: dans les astrocytomes sporadiques.
- Page 66 and 67: La Section exprime sa gratitude aux
- Page 69 and 70: Groupe Biologie des Infections et C
- Page 71 and 72: Prévalence des infections à VPH e
- Page 73 and 74: Chef Dr Silvia Franceschi Chercheur
- Page 75 and 76:
ces HAART est en effet associée à
- Page 77 and 78:
Edefonti V, Decarli A, La Vecchia C
- Page 79:
C, Pelucchi C, Montella M, Francesc
- Page 82 and 83:
72 rapport biennal 2008/2009
- Page 84 and 85:
Les recherches du Groupe Mode de vi
- Page 86 and 87:
2008). Le Groupe a également termi
- Page 88 and 89:
Chuang SC, Hashibe M, Scelo G, Brew
- Page 90 and 91:
Rayonnements non ionisants Avec la
- Page 93 and 94:
Section Nutrition et Métabolisme (
- Page 95 and 96:
Groupe Evaluation des expositions a
- Page 97 and 98:
dologique est également en prépar
- Page 99 and 100:
Kiemeney LA, Chirlaque MD, Ardanaz
- Page 101 and 102:
ducts, and risk of breast cancer in
- Page 103:
Section génétique (gen) Chef Dr P
- Page 106 and 107:
Epidémiologie génétique et molé
- Page 108 and 109:
Publications Abnet CC, Kamangar F,
- Page 110 and 111:
100 rapport biennal 2008/2009
- Page 112 and 113:
Tableau 1. Projet de système de cl
- Page 114 and 115:
Références Chaudru V, Lo MT, Lesu
- Page 117 and 118:
Groupe Prévention (pre) Chef Dr Ph
- Page 119 and 120:
J/cm2 J/cm2 a b Figure 1. Moyenne q
- Page 121 and 122:
Publications *Autier P, *Héry C, H
- Page 123 and 124:
Groupe Dépistage (scr) Chef Dr R.
- Page 125 and 126:
Projet multicentrique sur le vaccin
- Page 127 and 128:
Mathur, All India Institute of Medi
- Page 129 and 130:
Sankaranarayanan R, Ferlay J (2009)
- Page 131 and 132:
Groupe Assurance-Qualité (qas) Che
- Page 133 and 134:
fin 2007, 70 programmes de dépista
- Page 135 and 136:
Références Perry N, Broeders M, d
- Page 137 and 138:
Groupe Communication (com) Chef Dr
- Page 139 and 140:
Education et Formation (etr) Dr P.
- Page 141 and 142:
nale sur le cancer, ce qui pourrait
- Page 143 and 144:
Etude d’intervention contre l’h
- Page 145 and 146:
Comité d’éthique du CIRC (ce) E
- Page 147 and 148:
Conseils scientifique et de Directi
- Page 149 and 150:
Suisse Dr Gérard Escher Secrétari
- Page 151 and 152:
Membres du Conseil scientifique (20
- Page 153 and 154:
Division de l’administration et d
- Page 155 and 156:
Publications du personnel du CIRC 2
- Page 157 and 158:
Boffetta P, Hecht S, Gray N, Gupta
- Page 159 and 160:
of major lymphoma subtypes. Occup E
- Page 161 and 162:
elative validity of dietary glycaem
- Page 163 and 164:
Greenblatt MS, Brody LC, Foulkes WD
- Page 165 and 166:
Johansson M, Appleby PN, Allen NE,
- Page 167 and 168:
Lopez-Beltran A, Kirkali Z, Cheng L
- Page 169 and 170:
M, Moutsiou E, Trichopoulou A, Laur
- Page 171 and 172:
J, Johansson I, Ye W, Slimani N, Du
- Page 173 and 174:
Spurdle AB, Couch FJ, Hogervorst FB
- Page 175 and 176:
Vrieling A, Verhage BA, van Duijnho