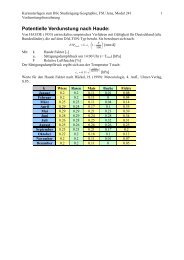
Hausarbeit - Friedrich-Schiller-Universität Jena
Hausarbeit - Friedrich-Schiller-Universität Jena
Hausarbeit - Friedrich-Schiller-Universität Jena

Erfolgreiche ePaper selbst erstellen
Machen Sie aus Ihren PDF Publikationen ein blätterbares Flipbook mit unserer einzigartigen Google optimierten e-Paper Software.
3.3.2 Moran’s (I) Index<br />
Der Moran’s (I) Index hat starke Ähnlichkeit mit Geary’s Index mit dem Unterschied, dass<br />
hier die Ergebnisse dem Betrachter wahrscheinlich logischer erscheinen. Denn hier stehen<br />
positive Ergebnisse auch für eine positive räumliche Autokorrelation und negative für eine<br />
negative räumliche Autokorrelation. Wenn der Index 0 ist, weist dies auf unabhängige<br />
unkorrelierte Daten hin, mit zufälliger Anordnung.<br />
Die Variablen in der unteren Formel 8 zur Berechnung des Index (I) werden fast genauso<br />
definiert wie bei Geary’s (c) Index. Allerdings wird c ij nach der oberen Formel 8 beschrieben.<br />
z i steht wieder für den Wert des Objektes i und j. Die Variable ist der Mittelwert, s²<br />
entspricht der Varianz von z i . Die räumliche Nähe für i und j wird wieder durch w ij,<br />
angegeben (LO & YEUNG 2002:352).<br />
Moran’s and Gearie’s Index kann man nur bei<br />
flächenhaften Objekten anwenden. Es gibt aber<br />
Punkt, Linien und Rasterobjekte für die auch<br />
über Umwege eine Berechnung der räumliche<br />
Autokorrelation möglich ist.<br />
Bei Punktdaten kann man beispielsweise die<br />
Punkte in Flächen umwandeln und dann so die<br />
oben erwähnten Indizes anwenden. Die<br />
räumliche Autokorrelation zwischen<br />
linienförmigen Objekte kann man berechen,<br />
Formel 8: Berechnung des Moran’s (I) Index wenn die Linien Verbindungen zwischen<br />
(LO & YEUNG 2002: 352)<br />
Punkten repräsentieren, die mit Merkmalen<br />
besetzt sind. So wird dann die<br />
Merkmalsähnlichkeit von den Punktpaaren mit anderen Punktpaaren verglichen und die<br />
räumliche Nähe wird dadurch gemessen ob es eine direkte Verbindung zwischen den<br />
Punktpaaren gibt. Bei Rasterdaten wird einfach verglichen, ob einzelne Rasterzellen gleiche<br />
Außengrenzen haben (LO & YEUNG 2002: 352).<br />
3.4 Probleme<br />
3.4.1 Datenherkunft<br />
Ein allgemeines Problem, das viele Analysen betrifft, ist, dass man nicht weiß, ob die<br />
Ergebnisse stimmen, weil man nicht sicher sein kann, dass die Daten, die diesen zu Grunde<br />
liegen, korrekt sind. Mit den Worten von LONGLEY et al. (2001: 137) ausgedrückt: „<br />
Uncertainties in data lead to uncertainties in the result of analysis.“ Die Ursache liegt u.a. in<br />
der Generalisierung und Bündelung der rohen Ausgangsdaten (welche die Realität<br />
widerspiegeln sollen), z.B.: wenn Krankheitsfälle nur pro Bezirk angegeben werden oder<br />
12