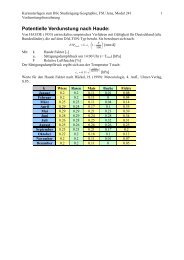
Hausarbeit - Friedrich-Schiller-Universität Jena
Hausarbeit - Friedrich-Schiller-Universität Jena
Hausarbeit - Friedrich-Schiller-Universität Jena

Erfolgreiche ePaper selbst erstellen
Machen Sie aus Ihren PDF Publikationen ein blätterbares Flipbook mit unserer einzigartigen Google optimierten e-Paper Software.
2.2.2 Schiefe und Exzess<br />
Die Schiefe (engl.: skewness) wie der Exzess (engl.: kurtosis) sind Formenparameter, d.h. sie<br />
geben Auskunft über die Form der Verteilung.<br />
„Die Schiefe […] stellt ein Maß für die Symmetrie der Verteilung um das arithmetische<br />
Mittel dar und errechnet sich…“ (HELMSCHROT & FINK 2001) aus der Differenz des<br />
Mittelwert x m vom Median Me, welche durch die Standartabweichung s dividiert wird, wie in<br />
Formel 4 abgebildet. Wenn die Form der Verteilung symmetrisch ist, dann hat die Schiefe g<br />
einen Wert von 0, ist g größer als 0 handelt es sich um eine positive Schiefe, der Median ist<br />
links vom Mittel. Bei einer negativen Schiefe hingegen ist g kleiner als 0 und der Median<br />
rechts vom Mittel.<br />
Formel 4: Schiefe g (HELMSCHROT & FINK 2001) Formel 5: Exzess Ez (HELMSCHROT & FINK 2001)<br />
Der Exzess hingegen ist ein Maß für die Steilheit der Verteilung. So beschreibt er, ob die<br />
Merkmalsverteilung spitz oder flach um das Zentrum verteilt ist. Berechnet wird er, wie in<br />
Formel 5 aufgezeigt. Von einer spitzen Verteilung spricht man, wenn der Exzess Ez größer<br />
als eins ist und damit steiler zuläuft als eine Normalverteilung. Keinen Exzess (Ez = 1) findet<br />
man bei einer Normalverteilung vor. Ist der Exzess kleiner als eins (negativer Exzess) ist die<br />
Verteilung flacher als eine Normalverteilung (LO & YEUNG 2002: 351).<br />
2.3 „Nearest Neighbor“-Analyse<br />
Bei der „Nearest Neighbor“-Analyse werden Verteilungsmuster von Punkten auf einer Fläche<br />
untersucht. Dabei kann bestimmt werden, ob die Messpunkte regelmäßig, unregelmäßig oder<br />
in Clustern (Gruppen) auftreten. „Diese Einordnung [in regelmäßig, unregelmäßig oder in<br />
Clustern] erfolgt über das Messen der Distanzen zwischen gepaarten Datenpunkten. Gepaart<br />
werden dabei die Punkte mit der geringsten räumlichen Distanz zueinander - die ‚Nearest<br />
Neighbor’.“ (DUMFARTH & LORUP 2000)<br />
Um Verwechslungen mit der räumliche Autokorrelation aus dem Weg zu gehen, muss klar<br />
festgestellt werden, dass bei der „Nearest Neighbor“-Analyse nur die räumliche Verteilung<br />
der Punkte bestimmt wird, nicht aber im Zusammenhang mit den Ausmaß der Werte, den<br />
diese Punkte haben<br />
4