Automotive Innovators Hit High Gear in - Xilinx
Automotive Innovators Hit High Gear in - Xilinx
Automotive Innovators Hit High Gear in - Xilinx

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
XCELLENCE IN AUTOMOTIVE & ISM<br />
sync _ <strong>in</strong>p<br />
1<br />
6<br />
Y_<strong>in</strong> 1<br />
2<br />
Y_<strong>in</strong> 2<br />
3<br />
Y_<strong>in</strong> 3<br />
4<br />
Y_<strong>in</strong> 4<br />
5<br />
Y_<strong>in</strong> 5<br />
1<br />
sel<br />
2<br />
A0<br />
3<br />
A1<br />
4<br />
A2<br />
5<br />
A3<br />
6<br />
A4<br />
7<br />
A5<br />
8<br />
A6<br />
9<br />
A7<br />
10<br />
A8<br />
sel<br />
<strong>in</strong> 0<br />
<strong>in</strong> 1<br />
<strong>in</strong> 2<br />
<strong>in</strong> 3<br />
<strong>in</strong> 4<br />
<strong>in</strong> 5<br />
<strong>in</strong> 6<br />
<strong>in</strong> 7<br />
<strong>in</strong> 8<br />
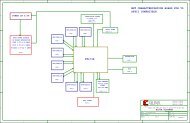
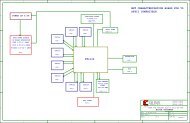
synch counter and reset<br />
for the memory address<strong>in</strong>g, some simple<br />
b<strong>in</strong>ary logic and registers to implement<br />
appropriate delays.<br />
The blue shad<strong>in</strong>g and the Xil<strong>in</strong>x logo<br />
<strong>in</strong>dicate the System Generator primitive<br />
blocks, each of which corresponds to optimized<br />
synthesizable HDL code. Through<br />
this graphical <strong>in</strong>terface, System Generator<br />
allows the algorithm developer to easily<br />
implement a DSP algorithm <strong>in</strong> hardware<br />
without hav<strong>in</strong>g any knowledge of HDL<br />
cod<strong>in</strong>g techniques.<br />
We use the second ma<strong>in</strong> subsystem, the<br />
5x5 FIR kernel (shown <strong>in</strong> blue <strong>in</strong> Figure 3),<br />
to implement the convolution operation. It<br />
receives <strong>in</strong> <strong>in</strong>put a block of 25 pixels from<br />
the l<strong>in</strong>e buffer block, multiplies them by the<br />
25 coefficients of the Gaussian mask and<br />
accumulates the result <strong>in</strong>to a register. We<br />
show the details of the implementation <strong>in</strong><br />
Figure 5. To fit the performance of the tar-<br />
sync<br />
In 1<br />
4 tapsdelay 4<br />
counter<br />
reset _out<br />
Out 1<br />
Out 2<br />
In 1<br />
Out 3<br />
Out 4<br />
4 tapsdelay 0<br />
Out 1<br />
Out 2<br />
In 1<br />
Out 3<br />
Out 4<br />
4 tapsdelay 1<br />
Out 1<br />
Out 2<br />
In 1<br />
Out 3<br />
Out 4<br />
4 tapsdelay 2<br />
Out 1<br />
Out 2<br />
In 1<br />
Out 3<br />
Out 4<br />
4 tapsdelay 3<br />
out<br />
mux 9 A<br />
(latency =2)<br />
Out 1<br />
Out 2<br />
Out 3<br />
Out 4<br />
1<br />
Out A<br />
11<br />
B0<br />
12<br />
B1<br />
13<br />
B2<br />
14<br />
B3<br />
15<br />
B4<br />
16<br />
B5<br />
17<br />
B6<br />
18<br />
B7<br />
19<br />
B8<br />
sel<br />
A0<br />
A1<br />
A2<br />
A3<br />
A4<br />
A5<br />
A6<br />
A7<br />
A8<br />
B0<br />
B1<br />
B2<br />
B3<br />
B4<br />
B5<br />
B6<br />
B7<br />
B8<br />
C0<br />
C1<br />
C2<br />
C3<br />
C4<br />
C5<br />
C6<br />
addr z -2<br />
ROM A<br />
addr z -2<br />
ROM B<br />
addr z -2<br />
ROM C<br />
z -3<br />
Delay 2<br />
Out A<br />
Out B<br />
Out C<br />
3 mux 9 (latency = 2 )<br />
sel<br />
<strong>in</strong> 0<br />
<strong>in</strong> 1<br />
<strong>in</strong> 2<br />
<strong>in</strong> 3<br />
<strong>in</strong> 4<br />
<strong>in</strong> 5<br />
<strong>in</strong> 6<br />
<strong>in</strong> 7<br />
<strong>in</strong> 8<br />
out<br />
mux 9 B<br />
(latency =2)<br />
2<br />
Out B<br />
Sel<br />
Sel<br />
Sel<br />
z -3<br />
Delay 3<br />
coeff _from _rom<br />
mux _out<br />
DSP 48 Macro (latency = 4 ) A<br />
coeff _from _rom<br />
mux _out<br />
DSP 48 Macro (latency = 4 ) B<br />
coeff _from _rom<br />
mux _out<br />
DSP 48 Macro (latency = 4 ) C<br />
20<br />
C0<br />
21<br />
C1<br />
22<br />
C2<br />
23<br />
C3<br />
24<br />
C4<br />
25<br />
C5<br />
26<br />
C6<br />
P<br />
P<br />
P<br />
sel<br />
<strong>in</strong> 0<br />
<strong>in</strong> 1<br />
<strong>in</strong> 2<br />
<strong>in</strong> 3<br />
<strong>in</strong> 4<br />
<strong>in</strong> 5<br />
<strong>in</strong> 6<br />
<strong>in</strong> 7<br />
<strong>in</strong> 8<br />
d<br />
en<br />
d<br />
en<br />
d<br />
en<br />
z q -1<br />
Register 1<br />
z q -1<br />
Register 2<br />
z q -1<br />
Register 4<br />
mux 9 C<br />
latency =3<br />
out<br />
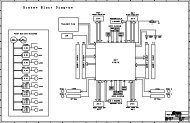
get device and to achieve a specified sample<br />
rate of 9 million samples per second<br />
(MSPS), we chose to use three multiplyaccumulators<br />
(which we implemented us<strong>in</strong>g<br />
the FPGA’s DSP48 programmable Multiply<br />
Accumulator functional units) <strong>in</strong> parallel.<br />
We dedicated each of them, at most, to n<strong>in</strong>e<br />
multiplications, via time-division multiplex<strong>in</strong>g<br />
(see the larger System Generator blocks<br />
<strong>in</strong> the top diagram of Figure 5). We split and<br />
stored the set of 25 coefficients of the mask<br />
<strong>in</strong> three ROMs that we implemented as distributed<br />
RAM (another memory resource<br />
the FPGA provides).<br />
In our implementation, we chose to fix<br />
the coefficients of the mask at compile time.<br />
However, we could have easily updated the<br />
design to accept these values as real-time<br />
<strong>in</strong>puts. In this way we could dynamically<br />
change the run-time <strong>in</strong>tensity of the filter<strong>in</strong>g<br />
based on environmental conditions.<br />
(Implementation Note: Because of the<br />
isotropic shape of the Gaussian, the kernel<br />
could be decomposed <strong>in</strong> two separable<br />
masks and the filter<strong>in</strong>g could be obta<strong>in</strong>ed as<br />
two consecutive convolutions with 1x5 and<br />
5x1 masks along the horizontal and vertical<br />
directions. Even though this approach<br />
would reduce the FPGA resources required,<br />
we didn’t adopt it to avoid los<strong>in</strong>g generality<br />
and readability of the design.)<br />
Another powerful feature found <strong>in</strong><br />
System Generator is the ability to apply a<br />
preload MATLAB function to customize<br />
the design before compilation. By sett<strong>in</strong>g<br />
parameters of the System Generator module<br />
(such as image resolution, FIR kernel<br />
values and the number of computational<br />
precision bits) and <strong>in</strong>itializ<strong>in</strong>g the workspace<br />
signals we used dur<strong>in</strong>g the run-time<br />
simulation, we can quickly and easily<br />
experiment with different process<strong>in</strong>g<br />
24 Xcell Journal Fourth Quarter 2008<br />
3<br />
Out C<br />
↓9<br />
z -1<br />
Down Sample<br />
↓9<br />
z -1<br />
Down Sample 1<br />
↓9<br />
z -1<br />
Down Sample 2<br />
Figure 5 – System Generator implementation<br />
of FIR (convolution) filter<br />
a<br />
b<br />
z a + b<br />
-1<br />
AddSub 1<br />
z -1<br />
Delay<br />
a<br />
b<br />
z a + b<br />
-1<br />
AddSub 3<br />
1<br />
sel<br />
z cast -1<br />
Convert 1<br />
1<br />
filtered<br />
[a:b]<br />
Slice 1<br />
[a:b]<br />
Slice<br />
2<br />
<strong>in</strong> 0<br />
3<br />
<strong>in</strong> 1<br />
4<br />
<strong>in</strong> 2<br />
5<br />
<strong>in</strong> 3<br />
6<br />
<strong>in</strong> 4<br />
7<br />
<strong>in</strong> 5<br />
8<br />
<strong>in</strong> 6<br />
9<br />
<strong>in</strong> 7<br />
10<br />
<strong>in</strong> 8<br />
z -1<br />
Delay 1<br />
sel<br />
d0<br />
d1z<br />
d2<br />
d3<br />
-1<br />
sel<br />
d0<br />
d1<br />
z<br />
d2<br />
d3<br />
-1<br />
Mux<br />
Mux 1<br />
z<br />
Delay<br />
-1<br />
sel<br />
d0<br />
d1 z -1<br />
d2<br />
d3<br />
Mux6<br />
out<br />
1